想学数据分析但不会Python,过来看看SQL吧!
Hi,各位同学,《从0到1,数据分析师修炼之路》专栏在上周发布了有关SQL的基础知识,包括SQL的书写规则、检索、排序以及过滤,不知道各位看完之后有没有去SQL Zoo(https://sqlzoo.net/)上去练习一波呢?有问题的话,欢迎随时在我们的微信群@我发起讨论~
本篇文章包含的知识点有:分组,子查询,链接表,聚合,条件判断,时间序列的处理以及数据清理。文章末尾再附上SELECT子句顺序和数据分析师的SQL思维导图。
知识清单
数据分组
创建分组(GROUP BY)
之前学到的筛选操作都是基于整个表去进行的,那如果想要依据某列中的不同类别(比如说不同品牌/不同性别等等)进行分类统计时,就要用到数据分组,在SQL中数据分组是使用GROUP BY子句建立的。
在使用GROUP BY时需要注意的几点:

- GROUP BY子句可以包含任意数量的列,因而可以对分组进行多重嵌套,如按照班级和性别进行分组的话,结果中班级A包含男生组和女生组,班级B也包含男生组和女生组;
- GROUP BY子句必须出现在WHERE子句之后,ORDER BY之前。
使用示例:
SELECT col_1,COUNT(*) AS num_col FROM table_1 GROUP BY col_1;
以上即可实现按col_1列中的不同类目进行行数统计。
过滤分组(HAVING)
在SQL入门中我们学过WHERE,它是对行数据进行筛选过滤的,那么,如果我想对创建的分组数据进行筛选过滤呢?这时候,你就要用到HAVING子句了,它与WHERE的操作符一致,只是换了关键字而已。
使用示例:
SELECT col_1,COUNT(*) AS num_col FROM table_1 GROUP BY col_1 HAVING COUNT(*) >= 2;
这里我们就筛选出了具有两个以上类别的分组。
⚠️使用HAVING时应该结合GROUP BY子句。
子查询与临时表格
我们之前所涉及到的都是从数据库中检索数据的单条语句,但当我们想要检索的数据并不能直接从数据库表中获取,而是需要从筛选后的表格中再度去查询时,就要用到子查询和临时表格了。
子查询与临时表格所完成的任务是一致的,只不过子查询是通过嵌套查询完成,而另一种是通过WITH创建临时表格进行查询。
构建子查询
构建子查询十分简单,只需将被查询的语句放在小括号里,进行嵌套即可,但在使用时一定要注意格式要清晰。
使用示例:
SELECT * FROM (SELECT day,channel, COUNT(*) AS events FROM web_events GROUP BY 1,2 -- 按照第一列(day)和第二列(channel)进行分组 ORDER BY 3 DESC) sub -- 小括号内的查询语句即为子查询 GROUP BY channel ORDER BY 2 DESC;
如上,我们创建了一个子查询,放在小括号里,并将其命名为sub。在子查询中也注意到了各个子句上下对齐,这样条例更清晰。
临时表格(WITH)
这种方法,就是使用WITH将子查询的部分创建为一个临时表格,然后再进行查询即可。
我们还是使用上面子查询的例子,这次用临时表格的形式实现:
WITH sub AS( SELECT day,channel, COUNT(*) AS events FROM web_events GROUP BY 1,2 ORDER BY 3 DESC) -- 创建临时表格 SELECT * FROM sub -- 对临时表格进行检索 GROUP BY channel ORDER BY 2 DESC; -- 这里是根据临时表格的第二列(channel)进行排序
如上,我们将被嵌套的子查询单独拎出来,用WITH创建了一个临时表格,再之后又使用SELECT根据该表格进行查询。
链接表
基本链接(JOIN)
SQL最强大的功能之一就是能在数据查询的执行中进行表的链接(JOIN)。
在关系数据库中,将数据分解为多个表能更有效地存储,更方便地处理,但这些数据储存在多个表中,怎样用一条SELECT语句就检索出数据呢?那就要使用链接。
创建链接的方式很简单,如下便是使用WHERE创建链接:
SELECT col_1,col_2,col_3 FROM table_1,table_2 WHERE table_1.id = table2.id;
如上,col_1和col_2属于table_1表中,col_3属于table_2表中,而这两个表使用相同的id列进行匹配。这种方法被称为等值链接,也就是内链接,我们可以使用如下的语句,更直观地实现内连接:
SELECT col_1,col_2,col_3 FROM table_1 INNER JOIN table_2 ON table_1.id = table2.id;
当然你也可以使用别名,简化输入,并且标明各列与表的隶属关系:
SELECT t1.col_1,t1.col_2,t2.col_3 FROM table_1 t1 INNER JOIN table_2 t2 ON t1.id = t2.id;
如上代码同样适用于左链接、右链接和外链接:
- LEFT JOIN : 获取FROM语句后的表格中的所有行,对于那些不存在于 JOIN 语句后的表格中的数据填充None;
- RIGHT JOIN : 获取JOIN语句后的表格中的所有行,对于那些不存在于 FROM语句后的表格中的数据填充None;
- FULL JOIN: 只要其中一个表中存在匹配,就返回数据,结果是两表的并集。
自链接
自链接经常用于对子查询的简化,如下示例:
假如要获取与Allen同一公司的所有顾客信息,那就需要你先筛选出Allen所在的公司,然后再根据该公司筛选出所有的顾客。使用子查询的方式如下:
SELECT id,customer_name,company_name,phone_number FROM customers WHERE company_name = (SELECT company_name FROM customers WHERE customer_name = 'Allen')
如果改为自链接的方式如下:
SELECT c1.id, c1.customer_name, c1.company_name, c1.phone_number FROM customers c1,customers c2 WHERE c1.company_name = c2.company_name AND c2.customer_name = 'Allen';
结果是一样的,但是使用自链接的处理速度比子查询要快得多。
组合查询(UNION)
UNION用于合并两个或多个SELECT 语句的结果集,使用方法也很简单,只要在多条SELECT语句中添加UNION关键字即可。
⚠️UNION 内部的 SELECT 语句必须拥有相同数量的列,列也必须拥有相似的数据类型。而且UNION返回的结果只会选取列中不同的值(即唯一值)。
使用UNION的场合情况:
- 在一个查询中从不同的表返回结果;
- 对一个表执行多个查询返回结果。
示例:
如下三个语句的结果是一致的。
多数情况下,组合相同表的多个查询所完成的任务与具有多个WHERE子句的一个查询是一样的。
-- 语句1:原始语句
-- 查询一
SELECT customer_name,phone_number
FROM customers
WHERE customer_state IN ('str1','str2');
--查询二
SELECT customer_name,phone_number
FROM customers
WHERE customer_state = 'str3';
-- 语句2:使用UNION链接
SELECT customer_name,phone_number
FROM customers
WHERE customer_state IN ('str1','str2')
UNION
SELECT customer_name,phone_number
FROM customers
WHERE customer_state= 'str3'
ORDER BY customer_name;
-- 在最后添加了ORDER BY对所有SELECT语句进行排序,这里只是为了示例在使用UNION时如何进行排序。
-- 语句3:使用WHERE
SELECT customer_name,phone_number
FROM customers
WHERE customer_state IN ('str1','str2')
OR customer_state = 'str3';
虽然这里看起来使用UNION比WHERE更复杂,但对于较复杂的筛选条件,或者从多个表中检索数据时,使用UNION更简单一些。
♂️如果想要获取筛选列的所有值,可以使用UNION ALL代替UNION,他们的使用方式是一样的。
SQL聚合
有时候我们只是需要获取数据的汇总信息,比如说行数啊、平均值啊这种,并不需要吧所有数据都检索出来,为此,SQL提供了专门的函数,这也是SQL最强大功能之一。
聚合函数
SQL的聚合函数如下所示:
函数说明AVG()返回某列的均值COUNT()返回某列的行数MAX()返回某列的最大值MIN()返回某列的最小值SUM()返回某列的和
使用示例:
SELECT AVG(col_1) AS avg_col_1 FROM table_1;
⚠️聚合函数都会忽略列中的NULL值,但是COUNT(*)也就是统计全部数据的行数时,不会忽略NULL值。
聚合不同值
当添加DISTINCT参数时,就可以只对不同值(也就是某列中的唯一值)进行函数操作。
使用示例:
SELECT AVG(DISTINCT col_1) AS avg_dist_col_1 FROM table_1;
条件判断
CASE语句是用来做条件判断的,如果满足条件A,那么就xxx,如果满足条件B,那么就xx。
需要注意的几点:
- CASE 语句始终位于 SELECT 条件中。
- CASE 必须包含以下几个部分:WHEN、THEN和 END。ELSE 是可选组成部分,用来包含不符合上述任一 CASE 条件的情况。
- 你可以在 WHEN 和 THEN之间使用任何条件运算符编写任何条件语句(例如 WHERE),包括使用 AND 和 OR 连接多个条件语句。
使用示例:
SELECT account_id, unit_name, CASE WHEN standard_qty = 0 OR standard_qty IS NULL THEN 0 ELSE standard_amt_usd/standard_qty END AS unit_price FROM orders LIMIT 10;
如上,我们使用CASE WHEN(条件一) THEN(条件一的结果),ELSE(其他不符合条件一的结果),END语句设立了两个条件,即当standard_qty为0或者不存在时我们返回0,当standard_qty不为0时进行计算,并储存为新列unit_price。
时间序列的处理
在SQL中有一套专门的内置函数,用来处理时间序列,那就是DATE函数。
SQL Date 数据类型
先了解一下在不同的数据库中的时间序列的表示。(了解即可)
MySQL 使用下列数据类型在数据库中存储日期或日期/时间值:
- DATE - 格式:YYYY-MM-DD
- DATETIME - 格式:YYYY-MM-DD HH:MM:SS
- TIMESTAMP - 格式:YYYY-MM-DD HH:MM:SS
- YEAR - 格式:YYYY 或 YY
SQL Server 使用下列数据类型在数据库中存储日期或日期/时间值:
- DATE - 格式:YYYY-MM-DD
- DATETIME - 格式:YYYY-MM-DD HH:MM:SS
- SMALLDATETIME - 格式:YYYY-MM-DD HH:MM:SS
- TIMESTAMP - 格式:唯一的数字
`DATE_TRUNC`函数
DATE_TRUNC使你能够将日期截取到特定部分。常见的截取依据包括日期、月份 和 年份。
语法:
DATE_TRUNC('datepart', timestamp)
其中datepart即为你的截取依据,后面的timestamp类型可以参考上面的Date数据类型。
我总结了一份SQL的datepart速查表放在了下面。
使用示例:
SELECT DATE_TRUNC('y',col_date) col_year
FROM table_1
GROUP BY 1
ORDER BY 1 DESC
LIMIT 10;
如上,我们将col_date列按照年(’y’)进行了分组,并按由大至小的顺序排序,取前10组数据。
`DATE_PART`函数
DATE_PART 可以用来获取日期的特定部分,如获取日期2018-10-6的月份,只会获得一个结果10,这是它与DATE_TRUNC的最大区别。
语法:
DATE_PART ('datepart', date或timestamp)
其中datepart即为你的截取依据,后面的timestamp类型可以参考上面的Date数据类型。
使用示例:
SELECT DATE_PART('y',col_date) col_year
FROM table_1
GROUP BY 1;
如上,我们筛选了col_date列的年份,并依据它做了分组。
想了解更多DATE函数,可以戳SQL日期和时间函数参考
(https://docs.aws.amazon.com/zh_cn/redshift/latest/dg/Date_functions_header.html)
datepart总结
如下给了很多的缩写,只记住最简单的即可。
日期部分或时间部分缩写世纪c、cent、cents十年dec、decs年y、yr、yrs季度qtr、qtrs月mon、mons周w,与 DATE_TRUNC一起使用时将返回离时间戳最近的一个星期一的日期。一周中的日 ( DATE_PART支持)dayofweek、dow、dw、weekday 返回 0–6 的整数(星期日是0,星期六是6)。一年中的日 ( DATE_PART支持)dayofyear、doy、dy、yearday日d小时h、hr、hrs分钟m、min、mins秒s、sec、secs毫秒ms、msec、msecs、msecond、mseconds、millisec、millisecs、millisecon
SQL数据清理
这一部分主要针对数据清理讲解了几个SQL中的常用函数,一般来说,也都是用在筛选阶段,更详尽的数据清理还是建议放在python中去进行。
字符串函数
LEFT、RIGHT、LENGTH
LEFT和RIGHT相当于是字符串截取,LEFT 是从左侧起点开始,从特定列中的每行获取一定数量的字符,而RIGHT是从右侧。
LENGTH就是获取字符串的长度,比如说字符串AIGROUP的长度为7。
语法:
LEFT(phone_number, 3) -- 返回从左侧数,前3个字符 RIGHT(phone_number, 8) -- 返回从右侧数,前8个字符 LENGTH(phone_number) -- 返回phone_number的长度
POSITION、STRPOS、SUBSTR
这三个函数都是与位置相关的函数。
POSITION 和STRPOS 可以获取某一字符在字符串中的位置,这个位置是从左开始计数,最左侧第一个字符起始位置为1,但他俩的语法稍有不同。
SUBSTR可以筛选出指定位置后指定数量的字符。
语法:
POSITION(',' IN city_state) -- 返回‘,’在city_state中的位置
STRPOS(city_state, ‘,’) -- 跟上面的语句等价
SUBSTR(city_state,4,5) -- 返回city_state字符串中,以第4个字符为起始的5个字符。
字符串拼接(CONCAT)
顾名思义,就是将两个字符串进行拼接。
语法:
CONCAT(first_name, ' ', last_name) -- 结果为:first_name last_name --或者你也可以使用双竖线来实现上述任务 first_name || ' ' || last_name
更改数据格式
- TO_DATE函数
TO_DATE函数可以将某列转为DATE格式,主要是将单独的月份或者年份等等转换为SQL可以读懂的DATE类型数据,这样做的目的是为了后续可以方便地使用时间筛选函数。
语法:
TO_DATE(col_name,'datepart')
TO_DATE('02 Oct 2001', 'DD Mon YYYY');
这里是将col_name这列按照datepart转化为DATE类型的数据,datepart可以参考之前的总结。
- CAST函数
CAST函数是SQL中进行数据类型转换的函数,但经常用于将字符串类型转换为时间类型。
语法:
CAST(date_column AS DATE) -- 你也可以写成这样 date_column::DATE
这里是将date_column转换为DATE格式的数据,其他时间相关的数据类型与样式对照可以参考上面写过的SQL Date数据类型,确保你想转换的数据样式与数据类型对应。
缺失值的处理
之前有提到过如何筛选出缺失值,即使用WHERE加上IS NULL或者IS NOT NULL。
那么如何对缺失值进行处理呢?(其实这里可以直接无视,筛选出来后在python中再进行处理)
SQL中提供了一个替换NULL值的函数COALESCE。
使用示例:
COALESCE(col_1,0) -- 将col_1中的NULL值替换为0 COALESCE(col_2,'no DATA') -- 将col_2中的NULL值替换为no DATA
总结
好啦,至此课程中的所有SQL知识点已经总结完了,希望大家能够用得上,除了看这些枯燥的文字和代码之外,希望大家一定一定要多加练习(SQL zoo),未来的数据分析师之路,还要继续加油呀!
附:SELECT子句顺序
下表中列出了这两周中涉及到的子句,在进行使用时,应严格遵循下表中从上至下的顺序。
子句说明是否必须使用SELECT要返回的列或表达式是FROM用于检索数据的表仅在从表中选择数据时使用JOIN…ON…用于链接表仅在需要链接表时使用WHERE过滤行数据否GROUP BY分组数据仅在按组计算时使用HAVING过滤分组否ORDER BY对输出进行排序否LIMIT限制输出的行数否
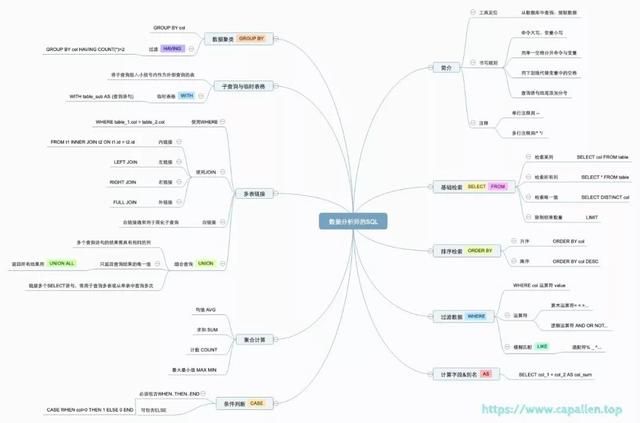
附:数据分析师的SQL思维导图