C语言探索之旅 | 第二部分第一课:模块化编程

作者 谢恩铭,公众号「程序员联盟」(微信号:coderhub)。
转载请注明出处。
原文:https://www.jianshu.com/p/2070cfd368ca《C语言探索之旅》全系列
内容简介
- 前言
- 函数原型
- 头文件
- 分开编译
- 变量和函数的作用范围
- 总结
- 第二部分第二课预告
1. 前言
上一课是 C语言探索之旅 | 第一部分练习题 。
话说上一课是第一部分最后一课,现在开始第二部分的探索之旅!
在这一部分中,我们会学习 C语言的高级技术。这一部分内容将是一座高峰,会挺难的,但是我们一起翻越。
俗语说得好:“一口是吃不成一个胖子的。”
但是一小口一小口,慢慢吃,还是能吃成胖子的嘛。所以要细水长流,肥油慢积,一路上有你(“油腻”)~
一旦你跟着我们的课程一直学到这一部分的结束,你将会掌握 C语言的核心技术,也可以理解大部分 C语言写的程序了。
到目前为止我们的程序都只是在一个 main.c 文件里捣腾,因为我们的程序还很短小,这也足够了。
但如果之后你的程序有了十多个函数,甚至上百个函数,那么你就会感到全部放在一个 main.c 文件里是多么拥挤和混乱。
正因为如此,计算机科学家才想出了模块化编程。原则很简单:与其把所有源代码都放在一个 main.c 当中,我们将把它们合理地分割,放到不同的文件里面。
2. 函数原型
到目前为止,写自定义函数的时候,我们都要求大家暂时把函数写在 main 函数的前面。
这是为什么呢?
因为这里的顺序是一个重要的问题。如果你将自己定义的函数放置在 main 函数之前,电脑会读到它,就会“知道”这个函数。当你在 main 函数中调用这个函数时,电脑已经知道这个函数,也知道到哪里去执行它。
但是假如你把这个函数写在 main 函数后面,那你在 main 函数里调用这个函数的时候,电脑还不“认识”它呢。你可以自己写个程序测试一下。是的,很奇怪对吧?这绝对有点任性的。
那你会说:“C语言岂不是设计得不好么?”
我“完全”同意(可别让 C语言之父 Dennis Ritchie 听到了…)。但是请相信,这样设计应该也是有理由的。计算机先驱们早就想到了,也提出了解决之道。
下面我们就来学一个新的知识点,借着这个技术,你可以把你的自定义函数放在程序的任意位置。
用来声明一个函数的“函数原型”
我们会声明我们的函数,需要用到一个专门的技术:函数原型,英语是 function prototype。function 表示“函数”,prototype 表示“原型,样本,模范”。
就好比你对电脑发出一个通知:“看,我的函数的原型在这里,你给我记住啦!”
我们来看一下上一课举的一个函数的例子(计算矩形面积):
double rectangleArea(double length, double width)
{
return length * width;
}
怎么来声明我们上面这个函数的原型呢?
- 复制,粘贴第一行。
- 在最后放上一个分号(
;)。 - 把这一整行放置在 main 函数前面。
很简单吧?现在你就可以把你的函数的定义放在 main 函数后面啦,电脑也会认识它,因为你在 main 函数前面已经声明过这个函数了。
你的程序会变成这样:
#include
#include
// 下面这一行是 rectangleArea 函数的函数原型
double rectangleArea(double length, double width);
int main(int argc, char *argv[])
{
printf("长为 10,宽为 5 的矩形面积 = %f\n", rectangleArea(10, 5));
printf("长为 3.5,宽为 2.5 的矩形面积 = %f\n", rectangleArea(3.5, 2.5));
printf("长为 9.7,宽为 4.2 的矩形面积 = %f\n", rectangleArea(9.7, 4.2));
return 0;
}
// 现在我们的 rectangleArea 函数就可以放置在程序的任意位置了
double rectangleArea(double length, double width)
{
return length * width;
}
与原先的程序相比有什么改变呢?
其实就是在程序的开头加了函数的原型而已(记得不要忘了那个分号)。
函数的原型,其实是给电脑的一个提示或指示。比如上面的程序中,函数原型
double rectangleArea(double length, double width);
就是对电脑说:“老兄,存在一个函数,它的输入是哪几个参数,输出是什么类型”,这样就能让电脑更好地管理。
多亏了这一行代码,现在你的 rectangleArea 函数可以置于程序的任何位置了。
记得:最好养成习惯,对于 C语言程序,总是定义了函数,再写一下函数的原型。
那么不写函数原型行不行呢?
也行。只要你把每个函数的定义都放在 main 函数之前。但是你的程序慢慢会越来越大,等你有几十或者几百个函数的时候,你还顾得过来么?
所以养成好习惯,不吃亏的。
你也许注意到了,main 函数没有函数原型。因为不需要,main 函数是每个 C程序必须的入口函数。人家 main 函数“有权任性”,跟编译器关系好,编译器对 main 函数很熟悉,是经常打交道的“哥们”,所以不需要函数原型来“介绍” main 函数。
还有一点,在写函数原型的时候,对于圆括号里的函数参数,名字是不一定要写的,可以只写类型。
因为函数原型只是给电脑做个介绍,所以电脑只需要知道输入的参数是什么类型就够了,不需要知道名字。所以我们以上的函数原型也可以简写如下:
double rectangleArea(double, double);
看到了吗,我们可以省略 length 和 width 这两个变量名,只保留 double(双精度浮点型)这个类型名字。
千万不要忘了函数原型末尾的分号,因为这是编译器区分函数原型和函数定义开头的重要指标。如果没有分号,编译时会出现比较难理解的错误提示。
3. 头文件
头文件在英语中是 header file。header 表示“数据头,页眉”,file 表示“文件”。
每次看到这个术语,我都想到已经结婚的“我们的青春”:周杰伦 的《头文字D》。
到目前为止,我们的程序只有一个 .c 文件(被称为“源文件”,在英语中是 source file。source 表示“源,源头,水源”),比如我们之前把这个 .c 文件命名为 main.c。当然名字是无所谓的,起名为hello.c,haha.c 都行。
一个项目多个文件
在实际编写程序的时候,你的项目一般肯定不会把代码都写在一个 main.c 文件中。当然,也不是不可以。
但是,试想一下,如果你把所有代码都塞到这一个 main.c 文件中,那如果代码量达到 10000 行甚至更多,你要在里面找一个东西就太难了。也正是因为这样,通常我们每一个项目都会创建多个文件。
那以上说到的项目是指什么呢?
之前我们用 CodeBlocks 这个 IDE 创建第一个 C语言项目的时候,其实已经接触过了。
一个项目(英语是 project),简单来说是指你的程序的所有源代码(还有一些其他的文件),项目里面的文件有多种类型。
目前我们的项目还只有一个源文件:main.c 。
看一下你的 IDE,一般来说项目是列在左边。
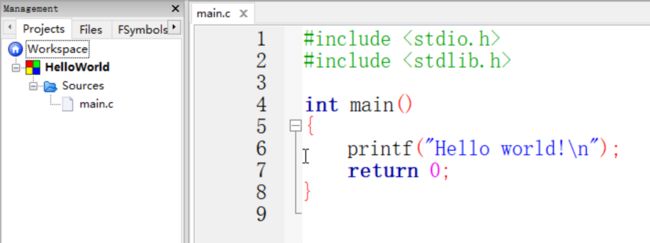
如上图,你可以看到,这个项目(在 Projects 一栏里)只有一个文件:main.c 。
现在我们再来展示一个包含好多个文件的项目:

上图中,我们可以看到在这个项目里有好几个文件。实际中的项目大多是这样的。你看到那个 main.c 文件了吗?通常来说在我们的程序中,会把 main 函数只定义在 main.c 当中。
当然也不是非要这样,每个人都有自己的编程风格。不过希望跟着这个课程学习的读者,可以和我们保持一致的风格,方便理解。
那你又要问了:“为什么创建多个文件呢?我怎么知道为项目创建几个文件合适呢?”
答案是:这是你的选择。通常来说,我们把同一主题的函数放在一个文件里。
.h 文件和 .c 文件
在上图中,我们可以看到有两种类型的文件:一种是以 .h 结尾的,一种是以 .c 结尾的。
- .h 文件:header file,表示“头文件”,这些文件包含了函数的原型。
- .c 文件:source file,表示“源文件”,包含了函数本身(定义)。
所以,通常来说我们不常把函数原型放在 .c 文件中,而是放在 .h 文件中,除非你的程序很小。
对每个 .c 文件,都有同名的 .h 文件。上面的项目那个图中,你可以看到 .h 和 .c 文件一一对应。
- files.h 和 files.c
- editor.h 和 editor.c
- game.h 和 game.c
但我们的电脑怎么知道函数原型是在 .c 文件之外的另一种文件里呢?
需要用到我们之前介绍过的预处理指令 #include 来将其引入到 .c 文件中。
请做好准备,下面将有一波密集的知识点“来袭”。
怎么引入一个头文件呢?其实你已经知道怎么做了,之前的课程我们已经写过了。
比如我们来看我们上面的 game.c 文件的开头
#include
#include
#include "game.h"
void player(SDL_Surface* screen)
{
// ...
}
看到了吗,其实你早就熟悉了,要引入头文件,只需要用 #include 这个预处理指令。
因此我们在 game.c 源文件中一共引入了三个头文件:stdlib.h, stdio.h,game.h。
注意到一个不同点了吗?
在标准库的头文件(stdlib.h,stdio.h)和你自己定义的头文件(game.h)的引入方式是有点区别的:
<>用于引入标准库的头文件。对于 IDE,这些头文件一般位于 IDE 安装目录的 include 文件夹中;在 Linux 操作系统下,则一般位于系统的 include 文件夹里。""用于引入自定义的头文件。这些头文件位于你自己的项目的目录中。
我们再来看一下对应的 game.h 这个头文件的内容:
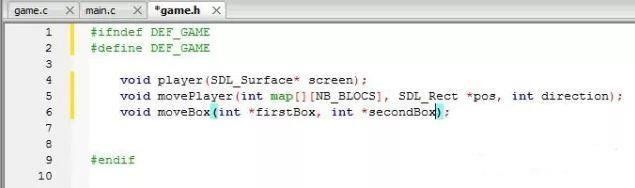
看到了吗,.h 文件中存放的是函数原型。
你已经对一个项目有大致概念了。
那你又会问了:“为什么要这样安排呢?把函数原型放在 .h 头文件中,在 .c 源文件中用 #include 引入。为什么不把函数原型写在 .c 文件中呢?”
答案是:方便管理,条理清晰,不容易出错,省心。
因为如前所述,你的电脑在调用一个函数前必须先“知道”这个函数,我们需要函数原型来让使用这个函数的其他函数预先知道。
如果用了 .h 头文件的管理方法,在每一个 .c 文件开头只要用 #include 这个指令来引入头文件的所有内容,那么头文件中声明的所有函数原型都被当前 .c 文件所知道了,你就不用再操心那些函数的定义顺序或者有没有被其他函数知道
例如我的 main.c 函数要使用 functions.c 文件中的函数,那我只要在 main.c 的开头写 #include "functions.h",之后我在 main.c 函数中就可以调用 function.c 中定义的函数了。
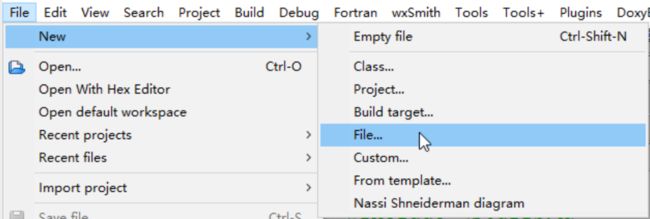
你可能又要问了:“那我怎么在项目中加入新的 .h 和 .c 文件呢?”
很简单,在 CodeBlocks 里,鼠标右键点击项目列表的主菜单处,选择 Add Files,或者在菜单栏上依次单击 File -> New -> File… ,就可以选择添加文件的类型了。
引入标准库
你脑海里肯定出现一个问题:
如果我们用 #include 来引入 stdio.h 和 stdlib.h 这样的标准库的头文件,而这些文件又不是我自己写的,那么它们肯定存在于电脑里的某个地方,我们可以找到,对吧?
是的,完全正确!
如果你使用的是 IDE(集成开发环境),那么它们一般就在你的 IDE 的安装目录里。
如果是在纯 Linux 环境下,那就要到系统文件夹里去找,这里不讨论了,感兴趣的读者可以去网上搜索。
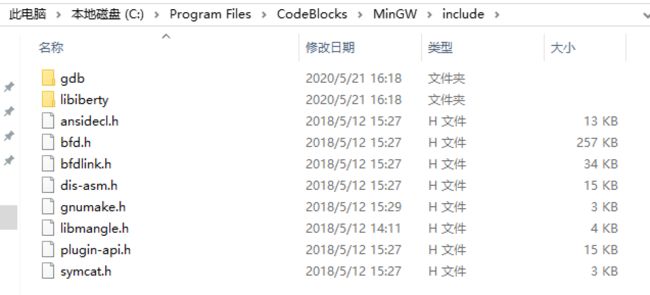
在我的情况,因为安装的是 CodeBlocks 这个 IDE,所以在 Windows下,我的头文件们“隐藏”在这两个路径下:
C:\Program Files\CodeBlocks\MinGW\include
和
C:\Program Files\CodeBlocks\MinGW\x86_64-w64-mingw32\include
一般来说,都在一个叫做 include 的文件夹里。
在里面,你会找到很多文件,都是 .h 文件,也就是 C语言系统定义的标准头文件,也就是系统库的头文件(对 Windows,macOS,Linux 都是通用的,C语言本来就是可移植的嘛)。
在这众多的头文件当中,你可以找到我们的老朋友:stdio.h 和 stdlib.h。
你可以双击打开这些文件或者选择你喜欢的文本编辑器来打开,不过也许你会吓一跳,因为这些文件里的内容很多,而且好些是我们还没学到的用法,比如除了 #include 以外的其他的预处理指令。
你可以看到这些头文件中充满了函数原型,比如你可以在 stdio.h 中找到 printf 函数的原型。
你要问了:“OK,现在我已经知道标准库的头文件在哪里了,那与之对应的标准库的源文件(.c 文件)在哪里呢?”
不好意思,你见不到它们啦。因为 .c 文件已经被事先编译好,转换成计算机能理解的二进制码了。
“伊人已去,年华不复,吾将何去何从?”
既然见不到原先的它们了,至少让我见一下“美图秀秀”之后的它们吧…
可以,你在一个叫 lib 的文件夹下面就可以找到,在我的 Windows 下的路经为:
C:\Program Files\CodeBlocks\MinGW\lib
和
C:\Program Files\CodeBlocks\MinGW\x86_64-w64-mingw32\lib

被编译成二进制码的 .c 文件,有了一个新的后缀名:.a(在 CodeBlocks 的情况,它的编译器是 MinGW。MinGW 简单来说就是 GCC 编译器的 Windows 版本)或者 .lib(在 Visual C++ 的情况),等。这是静态链接库的情况。
你在 Windows 中还能找到 .dll 结尾的动态链接库;你在 Linux 中能找到 .so 结尾的动态链接库。暂时我们不深究静态链接库和动态链接库,有兴趣的读者可以去网上自行搜索。
这些被编译之后的文件被叫做库文件或 Library 文件(library 表示“库,图书馆,文库”),不要试着去阅读这些文件的内容,因为是看不懂的乱码。
学到这里可能有点晕,不过继续看下去就会渐渐明朗起来,下面的内容会有示意图帮助理解。
小结一下:
在我们的 .c 源文件中,我们可以用 #include 这个预处理指令来引入标准库的 .h 头文件或自己定义的头文件。这样我们就能使用标准库所定义的 printf 这样的函数,电脑就认识了这些函数(借着 .h 文件中的函数原型),就可以检验你调用这些函数时有没有用对,比如函数的参数个数,返回值类型,等。
4. 分开编译
现在我们知道了一个项目是由若干文件组成的,那我们就可以来了解一下编译器(compiler)的工作原理。
之前的课里面展示的编译示例图是比较简化的,下图是一幅编译原理的略微详细的图,希望大家用心理解并记住:
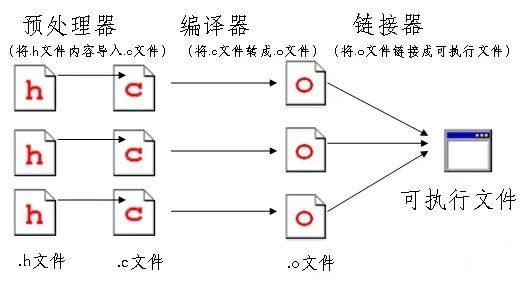
上图将编译时所发生的事情基本详细展示了,我们来仔细分析:
- 预处理器(preprocessor):顾名思义,预处理器为编译做一些预备工作,所以预处理器是在编译之前启动的。它的任务是执行特殊的指令,这些指令是通过预处理命令给出的,预处理命令以 # 开头,很容易辨认。
预处理指令有好多种,目前我们学过的只有 #include,它使我们可以在一个文件中引入另一个文件的内容。#include 这个预处理指令也是最常用的。
预处理器会把 #include 所在的那一句话替换为它所引入的头文件的内容,比如
#include
预处理器在执行时会把上面这句指令替换为 stdio.h 文件的内容。所以到了编译的时候,你的 .c 文件的内容会变多,包含了所有引入的头文件的内容,显得比较臃肿。
- 编译(compilation):这是核心的步骤,以前的课我们说过,正是编译把我们人类写的代码转换成计算机能理解的二进制码(0 和 1 组成)。编译器编译一个个 .c 文件。对于 CodeBlocks 这样的 IDE 来说,就是你放在项目列表中的所有 .c 文件;如果你是用 gcc 这个编译器来编译,那么你要指定编译哪几个 .c 文件。
编译器会把 .c 文件先转换成 .o 文件(有的编译器会生成 .obj 文件),.o 文件一般叫做目标文件(o 是 object 的首字母,表示“目标”),是临时的二进制文件,会被用于之后生成最终的可执行二进制文件。
.o 文件一般会在编译完成后被删除(根据你的 IDE 的设置)。从某种程度上来说 .o 文件虽然是临时中间文件,好像没什么大用,但保留着不删除也是有好处:假如项目有 10 个 .c 文件,编译后生成了 10 个 .o 文件。之后你只修改了其中的一个 .c 文件,如果重新编译,那么编译器不会为其他 9 个 .c 文件重新生成 .o 文件,只会重新生成你更改的那个。这样可以节省资源。
- 链接器(linker):顾名思义,链接器的作用是链接。链接什么呢?就是编译器生成的 .o 文件。链接器把所有 .o 文件链接起来,“制作成”一个“大块头”:最终的可执行文件(在 Windows下是 .exe 文件。在 Linux 下有不少种形式)。
现在你知道从代码到生成一个可执行程序的内部原理了吧,下面我们要展示给大家的这张图,很重要,希望大家理解并记住。
大部分的错误都会在编译阶段被显示,但也有一些是在链接的时候显示,有可能是少了 .o 文件之类。
之前那幅图其实还不够完整,你可能想到了:我们用 .h 文件引入了标准库的头文件的内容(里面主要是函数原型),函数的具体实现的代码我们还没引入呢,怎么办呢?
对了,就是之前提到过的 .a 或 .lib 这样的库文件(由标准库的 .c 源文件编译而成)。
所以我们的链接器(linker)的活还没完呢,它还需要负责链接标准库文件,把你自己的 .c 文件编译生成的 .o 目标文件和标准库文件整合在一起,然后链接成最终的可执行文件。
如下图所示:
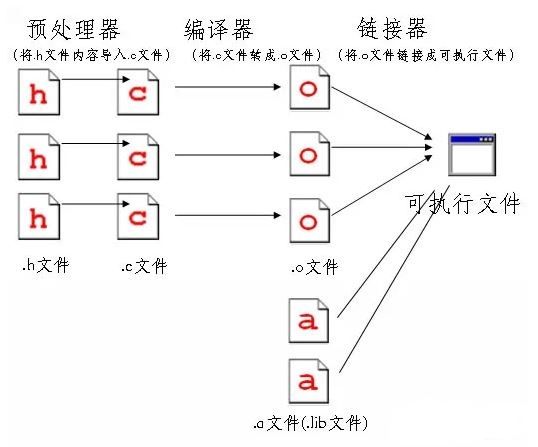
这下我们的示意图终于完整了。
这样我们才有了一个完整的可执行文件,里面有它需要的所有指令的定义,比如 printf 的定义。
5. 变量和函数的作用范围
为了结束这一课,我们还得学习最后一个知识点:变量和函数的作用范围(有效范围)。
我们将学习变量和函数什么时候是可以被调用的。
函数的私有变量(局部变量)
当你在一个函数里定义了一个变量之后,这个变量会在函数结尾时从内存中被删除。
int multipleTwo(int number)
{
int result = 0; // 变量 result 在内存中被创建
result = 2 * number;
return result;
} // 函数结束,变量 result 从内存中被删除
在一个函数里定义的变量,只在函数运行期间存在。
这意味着什么呢?意味着你不能从另一个函数中调用它。
#include
int multipleTwo(int number);
int main(int argc, char *argv[])
{
printf("15 的两倍是 %d\n", multipleTwo(15));
printf("15 的两倍是 %d", result); // 错误!
return 0;
}
int multipleTwo(int number)
{
int result = 0;
result = 2 * number;
return result;
}
可以看到,在 main 函数中,我们试着调用 result 这个变量,但是因为这个变量是在 multipleTwo 函数中定义的,在 main 函数中就不能调用,编译会出错。
记住:在函数里定义的变量只能在函数内部使用,我们称之为局部变量,英语是 local variable。local 表示“局部的,本地的”,variable 表示“变量”。
全局变量(请避免使用)
全局变量的英语是 global variable。global 表示“全局的,总体的”。
能被所有文件使用的全局变量
我们可以定义能被项目的所有文件的所有函数调用的变量。我们会展示怎么做,是为了说明这方法存在,但是一般来说,要避免使用能被所有文件使用的全局变量。
可能这样做一开始会让你的代码简单一些,但是不久你就会为之烦恼了。
为了创建能被所有函数调用的全局变量,我们须要在函数之外定义。通常我们把这样的变量放在程序的开头,#include 预处理指令的后面。
#include
int result = 0; // 定义全局变量 result
void multipleTwo(int number); // 函数原型
int main(int argc, char *argv[])
{
multipleTwo(15); // 调用 multipleTwo 函数,使全局变量 result 的值变为原来的两倍
printf("15 的两倍是 %d\n", result); // 我们可以调用变量 result
return 0;
}
void multipleTwo(int number)
{
result = 2 * number;
}
上面的程序中,我们的函数 multipleTwo 不再有返回值了,而是用于将 result 这个全局变量的值变成 2 倍。之后 main 函数可以再使用 result 这个变量。
由于这里的 result 变量是一个完全开放的全局变量,所以它可以被项目的所有文件调用,也就能被所有文件的任何函数调用。
注:这种类型的变量是很不推荐使用的,因为不安全。一般用函数里的 return 语句来返回一个变量的值。
只能在一个文件里被访问的全局变量
刚才我们学习的完全开放的全局变量可以被项目的所有文件访问。我们也可以使一个全局变量只能被它所在的那个文件调用。
就是说它可以被自己所在的那个文件的所有函数调用,但不能被项目的其他文件的函数调用。
怎么做呢?
只需要在变量前面加上 static 这个关键字。如下所示:
static int result = 0;
static 表示“静态的,静止的”。
函数的 static(静态)变量
注意:
如果你在声明一个函数内部的变量时,在前面加上 static 这个关键字,它的含义和上面我们演示的全局变量是不同的。
函数内部的变量如果加了 static,那么在函数结束后,这个变量也不会销毁,它的值会保持。下一次我们再调用这个函数时,此变量会延用上一次的值。
例如:
int multipleTwo(int number)
{
static int result = 0; // 静态变量 result 在函数第一次被调用时创建
result = 2 * number;
return result;
} // 变量 result 在函数结束时不会被销毁
这到底意味着什么呢?
就是说:result 这个变量的值,在下次我们调用这个函数时,会延用上一次结束调用时的值。
有点晕是吗?不要紧。来看一个小程序,以便加深理解:
#include
int increment();
int main(int argc, char *argv[])
{
printf("%d\n", increment());
printf("%d\n", increment());
printf("%d\n", increment());
printf("%d\n", increment());
return 0;
}
int increment()
{
static int number = 0;
number++;
return number;
}
上述程序中,在我们第一次调用 increment 函数时,number 变量被创建,初始值为 0,然后对其做自增操作(++ 运算符),所以 number 的值变为 1。
函数结束后,number 变量并没有从内存中被删除,而是保存着 1 这个值。
之后,当我们第二次调用 increment 函数时,变量 number 的声明语句(static int number = 0;)会被跳过不执行(因为变量 number 还在内存里呢。你想,一个皇帝还没驾崩,太子怎么能继位呢?)。
我们继续使用上一次创建的 number 变量,这时候变量的值沿用第一次 increment 函数调用结束后的值:1,再对它做 ++ 操作(自加 1),number 的值就变为 2 了。
依此类推,第三次调用 increment 函数后 number 的值为 3。第四次 number 的值为 4。
所以程序的输出如下:
1
2
3
4
一个文件中的局部函数(本地函数或静态函数)
我们用函数的作用域来结束我们关于变量和函数的作用域的学习。
正常来说,当你在一个 .c 源文件中创建了一个函数,那它就是全局的,可以被项目中所有其他 .c 文件调用。
但是有时我们需要创建只能被本文件调用的函数,怎么做呢?
聪明如你肯定想到了:对了,就是使用 static 关键字,与变量类似。
把它放在函数前面。如下:
static int multipleTwo(int number)
{
// 指令
}
现在,你的函数就只能被同一个文件中的其他函数调用了,项目中的其他文件中的函数就只“可远观而不可亵玩焉”…
小结一下变量的所有可能的作用范围
-
在函数体内定义的变量,如果前面没加 static 关键字,则是局部变量,在函数结束时被删除,只能在本函数内被使用。
-
在函数体内定义,但是前面加了 static 关键字,则为静态变量,在函数结束时不被删除,其值也会保留。
-
在函数外面定义的变量被称为全局变量,如果前面没有static关键字,则其作用范围是整个项目的所有文件,就是说它可以被项目的所有文件的函数调用。
-
函数外面定义的变量,如果前面加了 static 关键字,那就只能被本文件的所有函数调用,而不能被项目其他的文件的函数调用。
小结一下函数的所有可能的作用范围
-
一个函数在默认情况下是可以被项目的所有文件的函数调用的。
-
如果我们想要一个函数只能被本文件的函数所调用,只需要在函数前加上 static 关键字。
6. 总结
-
一个程序包含一个或多个 .c 文件(一般称为源文件,source file。当然,我们一般也把所有的高级语言代码叫做源代码)。通常来说,每个 .c 文件都有一个和它同名但不同扩展名的 .h 文件。.c 文件里面包含了函数的实际定义,而 .h 文件里包含函数的原型声明。
-
.h 文件的内容被一个叫做预处理器(preprocessor)的程序引入到 .c 文件的开头。
-
.c 文件被一个叫做编译器(compiler)的程序转换成 .o 的二进制目标文件。
-
.o 文件又被一个叫做链接器(linker)的程序链接成一个最终的可执行文件(在 Windows 操作系统里可执行程序的扩展名是 .exe,因为 exe 是英语 executable 的前三个字母,表示“可执行的”。在 Linux 系统里,可执行程序有不少扩展名(.elf,等),也可以没有扩展名)。
-
变量和函数都有“有效范围”,某些时候是访问不到的。
7. 第二部分第二课预告
今天的课就到这里,一起加油吧!
下一课:C语言探索之旅 | 第二部分第二课:进击的指针,C语言的王牌!
我是 谢恩铭,公众号「程序员联盟」(微信号:coderhub)运营者,慕课网精英讲师 Oscar 老师,终生学习者。
热爱生活,喜欢游泳,略懂烹饪。
人生格言:「向着标杆直跑」