Elasticsearch核心知识点大全
文章目录
- 1.为什么要使用Elasticsearch框架
- 2.Elasticsearch的应用场景
- 3.ElasticSearch的存储结构
- 4.Linux环境安装elasticsearch
- 5.Linux环境安装Kibana
- 6.Kibana对数据的增删改查
- 7.ElasticSearch乐观锁控制并发
- 8.SpringBoot整合ElasticSearch
- 9.ES的实现原理
- 10. DSL语言查询
- 11.安装IK分词器
- 12.自定义IK扩展词
- 13.文档映射
- 14. Elasticsearch的集群搭建
- 15.网盘搜索小案例
1.为什么要使用Elasticsearch框架
1.响应时间
MySQL
背景:+
小刘在做测试时,发现当数据库中的文档数仅仅上万条时,关键词查询就比较慢了。如果一旦到企业级的数据,响应速度就会更加不可接受。
原因:
在数据库做模糊查询时,如LIKE语句,它会遍历整张表,同时进行字符串匹配。
例如,当小刘在数据库查询“市场”时,数据库会在每一条记录去匹配“市场”这两字是否出现。实际上,并不是所有记录都包含“市场”,所以做了很多无用功。
这两个步骤都不高效,而且随着数据量的增大,消耗的资源和时间都会线性的增长。
Elasticsearch
提升:
小刘使用了云搜索服务后,发现这个问题被很好解决,TB级数据在毫秒级就能返回检索结果,很好地解决了痛点。
原因:
而Elasticsearch是基于倒排索引的,例子如下。

当小刘搜索“手机”时,Elasticsearch就会立即返回文档F,G,H。这样就不用花多余的时间在其他文档上了,因此检索速度得到了数量级的提升
2.分词
MySQL
背景:
在做中文搜索时,小刘发现组合词检索在数据库是很难完成的。
例如,当用户在搜索框输入“四川火锅”时,数据库通常只能把这四个字去进行全部匹配。可是在文本中,可能会出现“推荐四川好吃的火锅”,这时候就没有结果了。
原因:
数据库并不支持分词。如果人工去开发分词功能,费时费精力。
Elasticsearch
提升:
小刘使用云搜索服务后,就不用太过于关注分词了,因为Elasticsearch支持中文分词插件,很好地解决了问题。
原因:
当用户使用Elasticsearch时进行搜索时,Elasticsearch就自动帮他分好词了。
例如当小刘输入“四川火锅”时,Elasticsearch会自动做下面两件事
(1) 将“四川火锅”分词成“四川”和“火锅”
(2) 查找包含这两个词的文档
3.相关性
MySQL
背景:
在用数据库做搜索时,结果经常会出现一系列文档。小刘不禁思考:
· 到底什么文档是用户真正想要的呢?
· 怎么才能把用户想看的文档放在搜索列表最前面呢?
原因:
数据库并不支持相关性搜索。
例如,当用户搜索“咖啡厅”的时候,他很可能更想知道附近哪里可以喝咖啡,而不是怎么开咖啡厅。
Elasticsearch
提升:
小刘使用了云搜索服务后,发现Elasticsearch能很好地支持相关性评分。通过合理的优化,云搜索服务能够返回精准的结果,满足用户的需求。
原因:
Elasticsearch支持全文搜索和相关度评分。这样在返回结果就会根据分数由高到低排列。分数越高,意味着和查询语句越相关。
例如,当用户搜索“星巴克咖啡”,带有“星巴克咖啡”的信息就要比只包含“咖啡”的信息靠前。
4.可视化界面
MySQL
背景:
在使用数据库进行查询数据时,很多时候都是通过工程代码或者命令端完成。小刘发现很多时候分析结果并不太方便,缺少一个可视化界面来提高效率。
原因:
数据库自身通常不带可视化界面。而在完成搜索相关的任务时,常常需要根据搜索结果来进行分析。
Elasticsearch
提升:
小刘使用了云搜索服务后,发现可视化Kibana界面提升了研发的速度。
原因:
Kibana可视化界面完美支持Elasticsearch。研发人员能够在上面快速地进行概念验证,分析结果,提高开发效率。

2.Elasticsearch的应用场景
-
维基百科
-
The Guardian(国外新闻网站)
-
Stack Overflow(国外的程序异常讨论论坛)
-
GitHub(开源代码管理)
-
电商网站
-
日志数据分析
-
商品价格监控网站
-
BI系统
-
站内搜索
3.ElasticSearch的存储结构
ElasticSearch是文件存储,ElasticSearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面的这天格式
{
“name”:“william”,
“age”:“12”;
}
- 关系数据库 ⇒ 数据库 (会员数据库)⇒ 表 (用户表) ⇒ 行 ⇒ 列(Columns)
- Elasticsearch ⇒ 索引(Index) ⇒ 类型(type) ⇒ 文档(Docments) ⇒ 字段(Fields)
4.Linux环境安装elasticsearch
依赖软件链接:https://pan.baidu.com/s/1YwtEJkXThqU7ufxbJbLEiA
提取码:fq24
复制这段内容后打开百度网盘手机App,操作更方便哦
4.1 安装jdk
https://blog.csdn.net/qq_42815754/article/details/82968464
4.2 Elasticsearch
1.进入解压后的config文件,并且编辑elasticsearch.yml host填写本机服务器,port为9200

2.进入bin目录,启动elasticsearch
./elasticsearch
**注意:**但是此时我们发现会报一个错,大概意思就是不能使用root启动
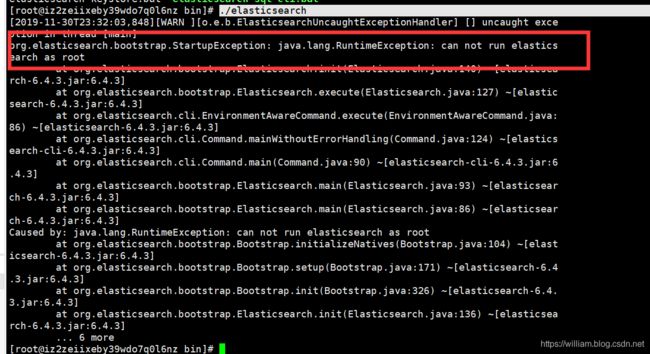
问题的解决:
groupadd esmayikt 添加用户群主
useradd esyushengjun -g esmayikt -p 123456 添加用户,设置设置密码
chown -R esyushengjun:esmayikt elasticsearch-6.4.3 给这个用户赋予es的权限
su esyushengjun 切换用户
./elasticsearch 启动es
启动报错的相关解决方案(注意:如果这个时候启动还是报错相关错误的话,以下的操作都是root进行的)
https://www.cnblogs.com/zhi-leaf/p/8484337.html
然后放你 阿里云服务器IP:9200 即可,就可以看到如下的界面

5.Linux环境安装Kibana
1: tar -zxvf kibana-6.4.3-linux-x86_64.tar.gz 解压
2: cd config 进入到config文件夹
3: vim kibana.yml 修改配置文件
4: 修改如下的内容,host为服务器的ip, url为es的服务器地址

cluster-name 也需要进行开启
cluster-name: my-application
5:进入到bin目录启动kibana
./kibana (记得先启动es,启动的时候 别用管理员账户)
然后浏览器搜索 服务器IP:5601 即可看到如下的界面

6.Kibana对数据的增删改查
1.创建索引

后面的命令,我不会附加图片,直接上命令
2.查询索引
GET mydata
3.创建文档 (索引/类型/id)
索引可以看成数据库
类型可以看成表
ID:可以看出表的主键ID.而{}代表ID那一行对应的数据
PUT /mydata/user/1
{
"name": "william",
"age": "13"
}
记住这个{}必须这样的格式.不然会报错.类似如下图

4.查询文档
GET /mydata/user/1

注意这个version 后面我会讲到.
5.修改文档(比如name修改为jack)
PUT /mydata/user/1
{
"name": "jacky",
"age": "13"
}
1.如果我们不写索引,此时利用put是无法进行添加,此时我们可以利用post请求进行添加,此时程序会默认给你创建一个ID
POST/mydata/user/
{
"name": "jacky",
"age": "13"
}
2.每次进行修改的时候,利用Get查询的时候,可以看出来的他的Version每次修改会+1
6.删除文档
delete /mydata/user
7.查询所有的数据
GET /mydata/user/_search
8.根据多个ID进行查询
GET /mydata/user/_mget
{
"ids":["1","2"]
}
9.查询属性
GET /mydata/user/_search?age:21
查询年龄30岁-60岁之间
GET /mydata/user/_search?age:[30 TO 60]
10.排序分页
查询年龄30岁-60岁之间 并且年龄降序、从0条数据到第1条数据
GET /mymayikt/user/_search?q=age[30 TO 60]&sort=age:desc&from=0&size=1
查询年龄30岁-60岁之间 并且年龄降序、从0条数据到第1条数据,展示name和age字段
GET /mymayikt/user/_search?q=age[30 TO 60]&sort=age:desc&from=0&size=1
&_source=name,age
7.ElasticSearch乐观锁控制并发
上面我提到过version字段的出现,其实也可以看出里面用的是无锁cas的机制,来控制并发的,具体cas的资料
可以参考我的博客https://william.blog.csdn.net/article/details/102870414
8.SpringBoot整合ElasticSearch
1.依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
<relativePath /> <!-- lookup parent from repository -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
2.配置文件
spring:
data:
elasticsearch:
####集群名称
cluster-name: myes
####地址
cluster-nodes: 192.168.212.151:9300
3.实体类
@Document(indexName = "mymayikt", type = "user")
@Data
public class UserEntity {
@Id
private String id;
private String name;
private int sex;
private int age;
}
4.dao
public interface UserReposiory extends CrudRepository<UserEntity, String> {
}
5.controller
@RestController
public class EsController {
@Autowired
private UserReposiory userReposiory;
@RequestMapping("/addUser")
public UserEntity addUser(@RequestBody UserEntity user) {
return userReposiory.save(user);
}
@RequestMapping("/findUser")
public Optional<UserEntity> findUser(String id) {
return userReposiory.findById(id);
}
}
6.启动项目
@SpringBootApplication
@EnableElasticsearchRepositories(basePackages = "com.mayikt.repository")
public class AppEs {
public static void main(String[] args) {
SpringApplication.run(AppEs.class, args);
}
}
然后访问localhost:800/addUser进行添加即可
9.ES的实现原理
全文检索底层采用的是倒排索引,那么何为倒排索引呢? 举个例子比如下面我们有这几条数据,每个数据在单独的一个文档
倒排索引:倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。
| 1.小俊是一家科技公司创始人,开的汽车是奥迪a8l,加速爽。 |
|---|
| 2.小薇是一家科技公司的前台,开的汽车是保时捷911 |
| 3.小红买了小薇的保时捷911,加速爽。 |
| 4.小明是一家科技公司开发主管,开的汽车是奥迪a6l,加速爽。 |
| 5.小军是一家科技公司开发,开的汽车是比亚迪速锐,加速有点慢 |
比如我们要搜索"比亚迪", 此时传统方式是从第一个文档依次进行查询的.如果查询有值则返回.
倒排索引会对以上文档进行关键字分词,可以使用关键字进行纪律,直接定位到文档,下标对应着关键字和文档的序号的对应关系

10. DSL语言查询
根据上面的传统的方式的命令,我们可以体会到传统的方式很麻烦,那么如何解决呢?
es中的查询请求有两种方式,一种是简易版的查询,另外一种是使用JSON完整的请求体,叫做结构化查询(DSL)。
由于DSL查询更为直观也更为简易,所以大都使用这种方式。
DSL查询是POST过去一个json,由于post的请求是json格式的,所以存在很多灵活性,也有很多形式。
term查询是精确匹配的,他不会进行分词
GET mymayikt/user/_search
{
"query": {
"term": {
"name": "xiaoming"
}
}
}
match查询相当于模糊匹配,只包含其中一部分关键词就行
GET /mymayikt/user/_search
{
"from": 0,
"size": 2,
"query": {
"match": {
"car": "奥迪"
}
}
}
使用filter过滤年龄
GET /mymayikt/user/_search
{
"query": {
"bool": {
"must": [{
"match_all": {
}
}],
"filter": {
"range": {
"age": {
"gt": 21,
"lte": 51
}
}
}
}
},
"from": 0,
"size": 10,
"_source": ["name", "age"]
}
11.安装IK分词器
为什么需要分词器?
因为Elasticsearch中默认的标准分词器分词器对中文分词不是很友好,会将中文词语拆分成一个一个中文的汉子。因此引入中文分词器-es-ik插件,比如我爱写代码,但是默认他把 代码拆分了代, 码 两个词.
安装说明
第一步:下载es的IK插件(资料中有)命名改为ik插件
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
第二步: 上传到/usr/local/elasticsea rch-6.4.3/plugins
第三步: 重启elasticsearch即可
http://192.168.212.181:9200/_analyze ## 访问地址
{
"analyzer": "ik_smart", ## 注意是ik_smart
"text": "奥迪"
}
{
"tokens": [
{
"token": "奥迪",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "a4l",
"start_offset": 2,
"end_offset": 5,
"type": "LETTER",
"position": 1
}
]
}
12.自定义IK扩展词
-
/usr/local/elasticsearch-6.4.3/plugins/ik/config目录下
-
vi custom/new_word.dic
老铁
王者荣耀
洪荒之力
共有产权房
一带一路
把这些词进行添加即可,注意换行,注意关闭es进行修改,否则会无法保存,或者您可以换个方法2
方法2:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/new_word.dic</entry> ## 指定下配置文件地址即可
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
13.文档映射
ElasticSearch的核心概念和关系数据库做了一个对比,
索引(index)相当于数据库,
类型(type)相当于数据表,
映射(Mapping)相当于数据表的表结构。
ElasticSearch中的映射(Mapping)用来定义一个文档,可以定义所包含的字段以及字段的类型、分词器及属性等等。
文档映射就是给文档中的字段指定字段类型、分词器。
使用GET /mymayikt/user/_mapping
13.1 动态映射
我们知道,在关系数据库中,需要事先创建数据库,然后在该数据库实例下创建数据表,然后才能在该数据表中插入数据。而ElasticSearch中不需要事先定义映射(Mapping),文档写入ElasticSearch时,会根据文档字段自动识别类型,这种机制称之为动态映射。
比如下面的命令
PUT /mydata/user/1
{
"name": "jacky", # String 分为text和 key Word 两种类型 ,text 会进行分词,key Word不会
"age": 13 , # 默认为Long类型的
}
13.2 静态映射
在ElasticSearch中也可以事先定义好映射,包含文档的各个字段及其类型等,这种方式称之为静态映射。
13.3 修改文档映射
像一般情况下,我们的age 想用 Integer 不想用long 该如何修改呢?
## 映射不发更改,一般采用删除,再次创建的方式进行修改
POST /mymayikt/_mapping/user
{
"user":{
"properties":{
"age":{
"type":"integer"
},
"sex":{
"type":"integer"
},
"name":{
"type":"text",
"analyzer":"ik_smart",
"search_analyzer":"ik_smart" # 指定分词器
},
"car":{
"type":"keyword"
}
}
}
}
14. Elasticsearch的集群搭建
14.1 Elasticsearch为什么要做集群
在单台ES服务器节点上,随着业务量的发展索引文件慢慢增多,会影响到效率和内存存储问题等。我们可以采用ES集群,将单个索引的分片到多个不同分布式物理机器上存储,从而可以实现高可用、容错性等
14.2 Elasticsearch集群的原理
1、每个索引会被分成多个分片shards进行存储,默认创建索引是分配5个分片进行存储,每个分片都会分布式部署在多个不同的节点上进行部署,该分片成为primary shards 主分片。 查看索引分片信息http://192.168.212.181:9200/mymayikt/_settings 注意:索引的主分片数量定义好后,不能被修改(待会讲)
2、每一个主分片为了实现高可用,都会有自己对应的备分分片,主分片对应的备分片不能存放同一台服务器上,主分片可以和其他备分片存放在同一个node节点上。 画图演示:为什么ES主分片对应的备分片不在同一台节点存放
14.3 Elasticsearch如何解决高并发
ES是一个分布式全文检索框架,隐藏了复杂的处理机制,内部使用 分片机制、集群发现、分片负载均衡请求路由。
Shards 分片:代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
Replicas分片:代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
14.4 为什么主分片的数量不能修改
当客户端发起创建document的时候,es需要确定这个document放在该index哪个shard上。这个过程就是数据路由。 路由算法:shard = hash(routing) % number_of_primary_shards 如果number_of_primary_shards在查询的时候取余发生的变化,无法获取到该数据 画图演示 注意:索引的主分片数量定义好后,不能被修改
14.5 Elasticsearch的集群搭建
1.关系对应 比如我们准备三台服务器,他们的关系如下

2.修改配置
1: vi elasticsearch.yml
2: cluster.name: myes ###保证三台服务器节点集群名称相同
3: node.name: node-1 #### 每个节点名称不一样 其他两台为node-1 ,node-2
4: network.host: 192.168.212.180 #### 实际服务器ip地址
5: discovery.zen.ping.unicast.hosts: ["192.168.212.184", "192.168.212.185","192.168.212.186"]##多个服务集群ip
6: discovery.zen.minimum_master_nodes: 1
关闭防火墙 systemctl stop firewalld.service
默认底层开启9300 集群
3.进行验证
http://192.168.212.185:9200/_cat/nodes?pretty

15.网盘搜索小案例
一般的网盘,是通过爬虫实时获取网盘链接的,这里因为不涉及第三方技术,所以es的数据这里是写死的,具体前台代码,参考链接
链接:https://pan.baidu.com/s/1NMmLxg135zLEXKkqbyqtCQ
提取码:af3i
复制这段内容后打开百度网盘手机App,操作更方便哦
1.依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
<relativePath /> <!-- lookup parent from repository -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>com.google.collections</groupId>
<artifactId>google-collections</artifactId>
<version>1.0-rc2</version>
</dependency>
<!-- springboot整合freemarker -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-freemarker</artifactId>
</dependency>
</dependencies>
2.实体类
package com.mayikt.entity;
import java.util.Date;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import lombok.Data;
@Data
@Document(indexName = "clouddisk", type = "disk")
public class CloudDiskEntity {
@Id
private String id;
// 名称
private String name;
// 来源
private String source;
// 描述
private String describe;
// 分享时间
private Date shartime;
// 浏览次数
private Long browsetimes;
// 文件大小
private Double filesize;
// 分享人
private String sharpeople;
// 收录时间
private String collectiontime;
// 地址
private String baiduaddres;
}
3.dao
public interface CloudDiskDao extends ElasticsearchRepository<CloudDiskEntity, String> {
}
4.controller
//普通的操作
@RequestMapping("/findById/{id}")
public Optional<CloudDiskEntity> findById(@PathVariable String id) {
return cloudDiskDao.findById(id);
}
//es的模糊查询
@RequestMapping("/search")
public Page<CloudDiskEntity> search(String keyWord, @PageableDefault(page =
0, value = 2) Pageable pageable) {
// 查询所有的
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
if (!StringUtils.isEmpty(keyWord)) {
// 模糊查询 一定要ik中文
MatchQueryBuilder matchQuery = QueryBuilders.matchQuery("name", keyWord);
boolQuery.must(matchQuery);
}
Page<CloudDiskEntity> page = cloudDiskDao.search(boolQuery, pageable);
return page;
}
5.配置信息
spring:
data:
elasticsearch:
####集群名称
cluster-name: myes
####地址
cluster-nodes: 192.168.212.180:9300
freemarker:
# 设置模板后缀名
suffix: .ftl
# 设置文档类型
content-type: text/html
# 设置页面编码格式
charset: UTF-8
# 设置页面缓存
cache: false
# 设置ftl文件路径
template-loader-path:
- classpath:/templates
# 设置静态文件路径,js,css等
mvc:
static-path-pattern: /static/**
server:
port: 80
6.启动类
@SpringBootApplication
@EnableElasticsearchRepositories(basePackages = "com.mayikt.repository")
public class AppEs {
public static void main(String[] args) {
SpringApplication.run(AppEs.class, args);
}
}