MYSQL 中级知识总结
数据库设计三范式
1NF :原子性,列不能再拆分成其他列
2NF :满足1NF,另外包含两步内内容,一个表必须有一个主键;非主键必须完全依赖于主键。
3NF:满足2NF,非主键直接依赖于主键,不能传递依赖
1NF介绍:

2NF介绍:

第三范式:

总结:

E-R模型
实体 - 关系 模型
表和 表 之间的关系
先用建模工具。将表和表之间的关系建立
再根据 E-R模型。满足三范式,创建设计数据库表结构
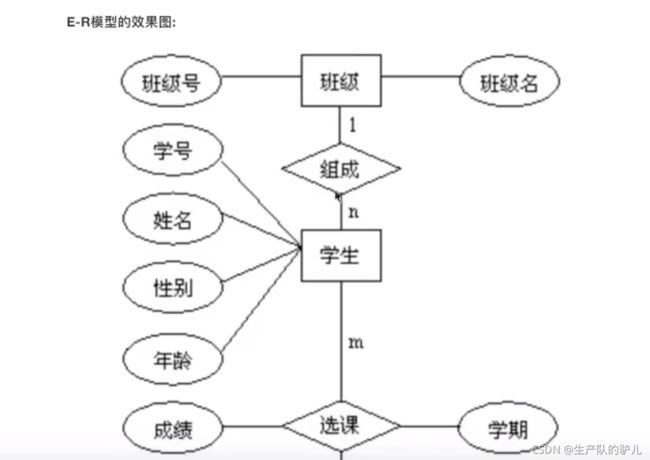

矩形: 表
菱形: 表和表关系
椭圆形: 字段
表和表关系: 1对1 关系
1对多 关系
多对多 关系
一对一的关系

一对多的关系
把关系字段 放在 多的一方

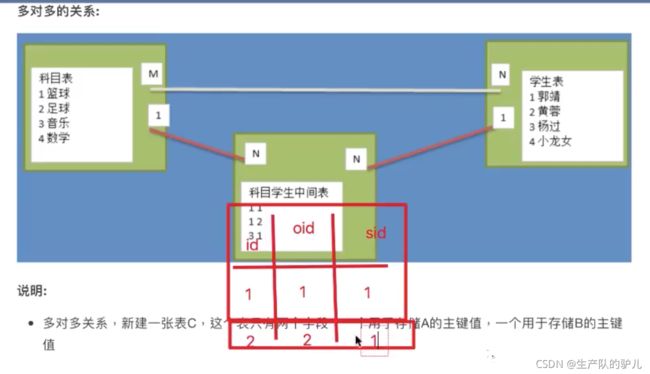
多对多的关系:
搞一张中间表,用于存储这两个表之间的关系。
外键约束 编写
外键所使用的数据,必须来源于某个表中的主键
不是的话,绝对不允许插入数据
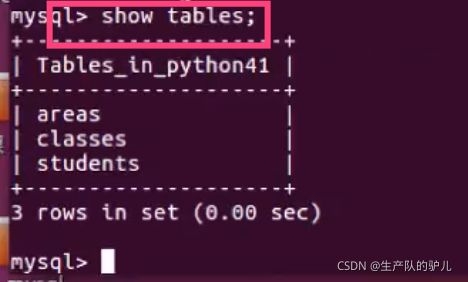
mysql -uroot -p
show tables;
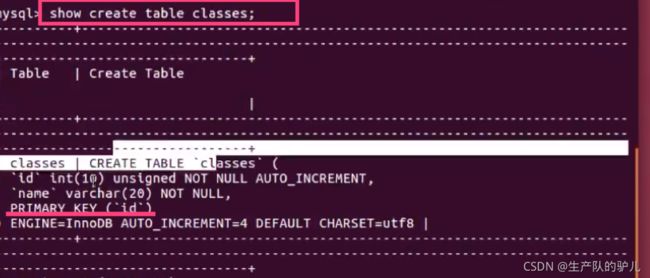
show create table class;
show create table students;

给students添加外键约束,以后给students表添加数据,必须c-id在class表的id中存在,该数据才可以添加。
alter table students add foreign key(cls_id) references classes(id);
不搞外键,会容易产生垃圾数据
例子:
随便插入数据

增加外键约束
alter table students add foreign key(cls_id) references classes(id);
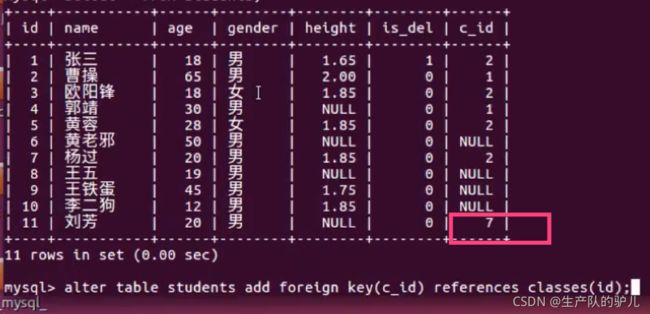

注意:如果students c-id 之前有个7,在class的id本身不存在
是没办法 将c_id的外键 添加设定为为class表id

创建老师表的时候,就填外键约束,老师的s_id必须是来自于school表的id
create table school(
id int unsigned not null primary key auto_increment,
name varchar(30) not null
);
create table teacher(
id int unsinged not null primary key auto_increment,
name varchar(20) not null,
s_id int unsigned,
forenign key(s_id) references school(id)
);
删除外键约束

总结:

小tips:
desc xxx;
可以直接查看xx的字段信息
事务
标的存储引擎 为 innoDB类型,才可以使用事务。
存储引擎: 存储数据的机制,不同存储引擎不同存储机制。
show engines; 可以查看引擎


开启事务:

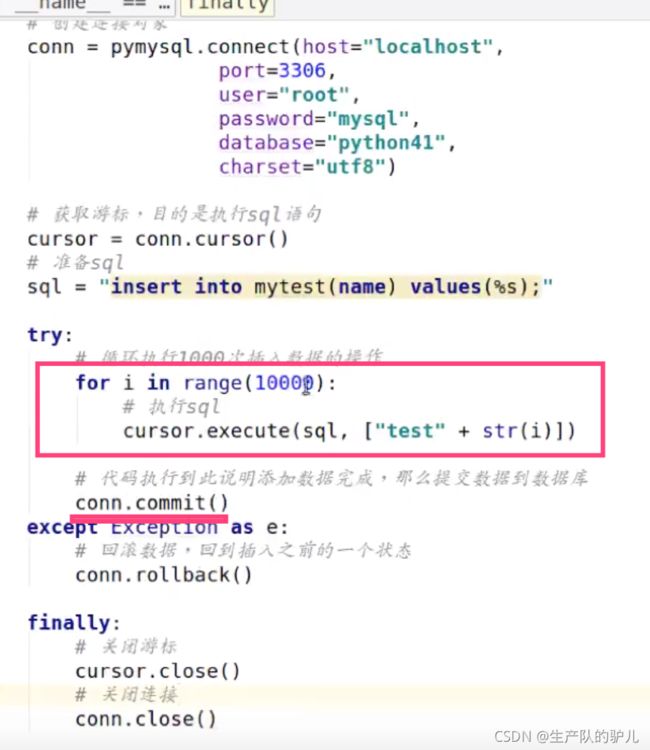
Python操控数据库
pymysql包




多个参数
事务

索引
提升查询速度
索引 称 键,特殊文件,保持数据表中 所有记录的位置信息
好比 一本书 的目录,提升数据库的查询速度。
查看索引
show index from 表名;
索引创建
alter table 表名 add index 索引名(列名);

主键 会 自带索引,查询速度快!
外键 也会 自带索引
删除索引
alter table 表名 drop index 索引名;

案例-索引演练:


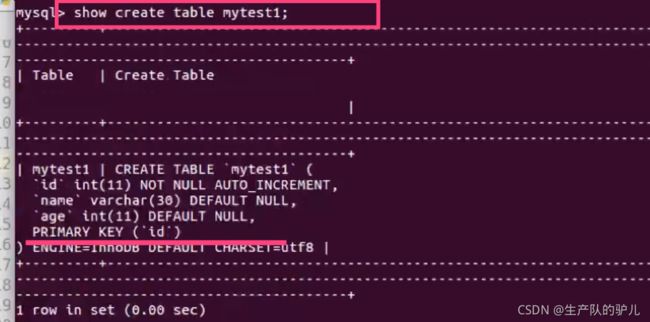
这个是主键的索引
show create table classes;
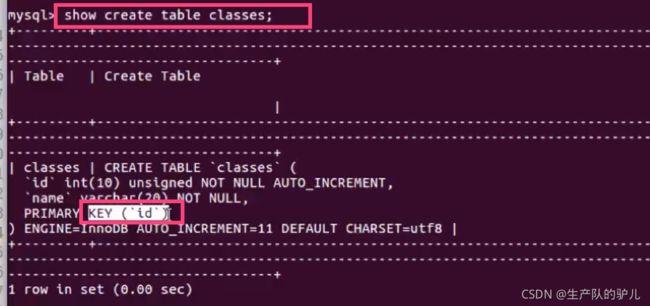
有key 就是有索引,通过name查询,要比id快!!
show create table students;

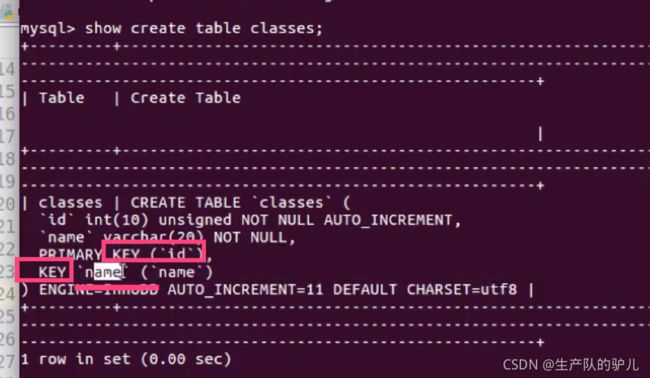
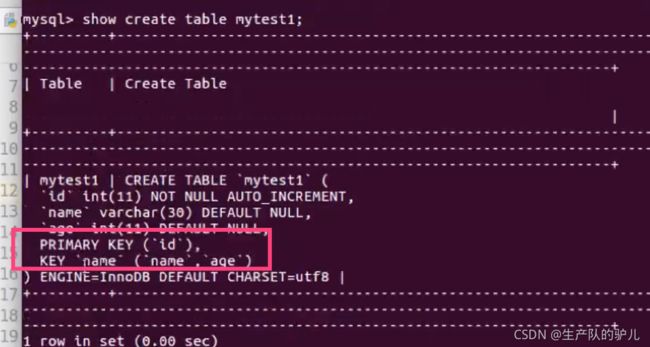
两个key 说明 两个索引
给班级表添加索引

给 classes 表的name字段添加索引
不写索引名,默认为和字段名一样。
alter table classes add index(name);

删除索引
alter table classes drop index name;


案例测试 索引速度:
创建一个表,插入10w条数据
检测时间:
set profiling = 1;
show profiles;

联合索引
这个索引,只能影响一个字段,变为多个字段。
一个索引覆盖多个字段,用于多个字段查询。
好处:
减少磁盘开销

案例练习:
create table my_test1(
id int not null primary key auto_increment.
name varchar(30),
age int
);
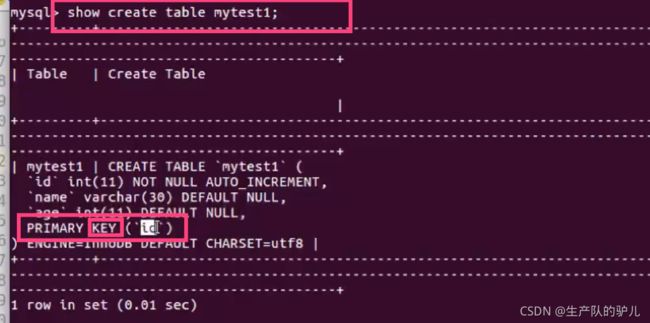
不指定默认为第一个字段的名字
lter table mytest1 add index(name,age) ;
alter table mytest1 drop index name;

联合索引 最左原则:


就是 最左边的字段 一定要出现在where 条件里面,这个索引才会起作用
索引的优缺点
优点: 查询速度快
缺点: 占用磁盘空间
数据越多,创建索引时候,越消耗时间。
使用原则:
经常更新的表,不要创建索引
经常查询的表,创建索引
数据小,不要创建索引
字段相同值多,不要加索引, 比如 性别 字段 就是 男 女
小结
