《Python 深度学习》刷书笔记 Chapter 6 Part-5 循环神经网络RNN
文章目录
- 引入循环神经网络
-
- 6-19 RNN 伪代码
- 6-20 更详细的RNN伪代码
- 6-21 简单RNN的Numpy实现
- 使用RNN解决IMDB电影评价分类问题
-
- 6-22 准备IMDB数据
- 6-23 用Embedding层和SimpleRNN来训练模型
- 6-24 绘制结果
- 理解LSTM与GRU层
- Keras中的一个LSTM例子
-
- 6-27 使用Keras中的LSTM层
- 写在最后
引入循环神经网络
在此之前的神经网络所具有的特点:没有记忆,只会向前传播,在输入输出之间(模型的两端)没有任何状态
循环神经网络:能够模拟人的阅读,在读这个句子的时候,我们总能记住这之前的内容,从而能够动态理解整个句子的含义
循环神经网络的处理方式:
- 遍历所有元素
- 保存一个状态
- 将这个状态加入到影响下一次的输出中
RNN是一类具有内部环的神经网络,在处理两个不同的序列时,RNN会被重置
为了解释清楚,我们将使用Numpy来实现一个简单的循环神经网络:
输入:一个张量序列(timesteps, input_features)
时间步:time_steps
- 考虑t时刻当前状态与t时刻的输入(input_features)
- 对二者计算得到t时刻的输出
- 将下一个时间步的状态设置为上一个时间步的输出
- (对于第一个时间步,上一个时间步没有意义)
- 因此我们需要初始化一个全零向量作为初始状态
6-19 RNN 伪代码
# t时刻的状态
state_t = 0
# 对元素进行遍历
for input_t in input_sequence:
output_t = f(input_t, state_t)
state_t = output_t
6-20 更详细的RNN伪代码
state_t = 0
for input_t in input_sequence:
output_t = activation(dot(W, input_t) + dot(U, state_t) + b)
state_t = output_t
6-21 简单RNN的Numpy实现
import numpy as np
# 输入的时间步数
timesteps = 100
# 输入的特征空间维度
input_features = 32
# 输出的特征空间维度
output_features = 64
# 生成一个输入数据(随机噪声)
inputs = np.random.random((timesteps, input_features))
# 初始状态:全0向量
state_t = np.zeros((output_features, ))
# 创建随机的权重矩阵
W = np.random.random((output_features, input_features))
U = np.random.random((output_features, output_features))
b = np.random.random((output_features, ))
successive_outputs = []
# input_t 是形状为(input_features, )的向量
for input_t in inputs:
# RNN核心
output_t = np.tanh(np.dot(W, input_t) + np.dot(U, state_t) + b)
# 将这个输出保存在列表中
successive_outputs.append(output_t)
# 更新网络的状态
state_t = output_t
# 最终输出一个二维张量
final_output_sequence = np.stack(successive_outputs, axis = 0)
使用RNN解决IMDB电影评价分类问题
6-22 准备IMDB数据
from keras.datasets import imdb
from keras.preprocessing import sequence
# 特征单词数
max_features = 10000
# 在maxlen之后截断
maxlen = 500
batch_size = 32
print('loading data...')
(input_train, y_train), (input_test, y_test) = imdb.load_data(
num_words = max_features)
print(len(input_train), 'train sequence')
print(len(input_test), 'test_sequence')
print('Pad sequences (sampels x time)')
input_train = sequence.pad_sequences(input_train, maxlen = maxlen)
input_test = sequence.pad_sequences(input_test, maxlen = maxlen)
print('input_train shape:', input_train.shape)
print('input_test shape:', input_test.shape)
loading data...
E:\develop_tools\Anaconda\envs\py36\lib\site-packages\keras\datasets\imdb.py:101: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
x_train, y_train = np.array(xs[:idx]), np.array(labels[:idx])
E:\develop_tools\Anaconda\envs\py36\lib\site-packages\keras\datasets\imdb.py:102: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
x_test, y_test = np.array(xs[idx:]), np.array(labels[idx:])
25000 train sequence
25000 test_sequence
Pad sequences (sampels x time)
input_train shape: (25000, 500)
input_test shape: (25000, 500)
6-23 用Embedding层和SimpleRNN来训练模型
from keras.models import Sequential
from keras.layers import Embedding, Flatten, Dense, SimpleRNN
model = Sequential()
model.add(Embedding(max_features, 32))
model.add(SimpleRNN(32))
model.add(Dense(1, activation = 'sigmoid'))
model.compile(optimizer = 'rmsprop', loss = 'binary_crossentropy', metrics = ['acc'])
history = model.fit(input_train, y_train,
epochs = 10,
batch_size = 128,
validation_split = 0.2)
E:\develop_tools\Anaconda\envs\py36\lib\site-packages\tensorflow_core\python\framework\indexed_slices.py:424: UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory.
"Converting sparse IndexedSlices to a dense Tensor of unknown shape. "
Train on 20000 samples, validate on 5000 samples
Epoch 1/10
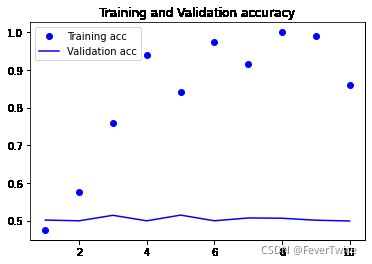
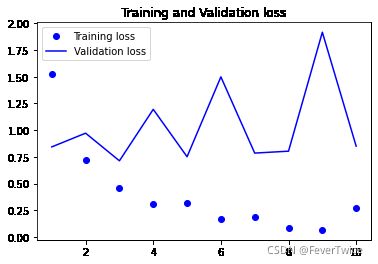
20000/20000 [==============================] - 20s 988us/step - loss: 0.5623 - acc: 0.7004 - val_loss: 0.4207 - val_acc: 0.8242
Epoch 2/10
20000/20000 [==============================] - 21s 1ms/step - loss: 0.3479 - acc: 0.8576 - val_loss: 0.3817 - val_acc: 0.8386
Epoch 3/10
20000/20000 [==============================] - 20s 1ms/step - loss: 0.2690 - acc: 0.8948 - val_loss: 0.3466 - val_acc: 0.8480
Epoch 4/10
20000/20000 [==============================] - 21s 1ms/step - loss: 0.2299 - acc: 0.9143 - val_loss: 0.3445 - val_acc: 0.8572
Epoch 5/10
20000/20000 [==============================] - 22s 1ms/step - loss: 0.1918 - acc: 0.9286 - val_loss: 0.3320 - val_acc: 0.8660
Epoch 6/10
20000/20000 [==============================] - 22s 1ms/step - loss: 0.1630 - acc: 0.9405 - val_loss: 0.3832 - val_acc: 0.8730
Epoch 7/10
20000/20000 [==============================] - 21s 1ms/step - loss: 0.1280 - acc: 0.9549 - val_loss: 0.3604 - val_acc: 0.8602
Epoch 8/10
20000/20000 [==============================] - 20s 1ms/step - loss: 0.1089 - acc: 0.9624 - val_loss: 0.8731 - val_acc: 0.7722
Epoch 9/10
20000/20000 [==============================] - 20s 1ms/step - loss: 0.0797 - acc: 0.9744 - val_loss: 0.4186 - val_acc: 0.8540
Epoch 10/10
20000/20000 [==============================] - 21s 1ms/step - loss: 0.0602 - acc: 0.9821 - val_loss: 0.4674 - val_acc: 0.8576
6-24 绘制结果
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label = 'Training acc')
plt.plot(epochs, val_acc, 'b', label = 'Validation acc')
plt.title('Training and Validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label = 'Training loss')
plt.plot(epochs, val_loss, 'b', label = 'Validation loss')
plt.title('Training and Validation loss')
plt.legend()
plt.show()
理解LSTM与GRU层
使用SimpleRNN可能会存在梯度消失问题
LSTM通过引入数据流来解决这一问题
- 保存前面网络训练的信息
- 这些信息通过与输入的信息进行运算,调节下一输出
- 从而影响下一个时间步的状态
Keras中的一个LSTM例子
我们使用LSTM创建一个模型,然后在IMDB数据集上训练模型
6-27 使用Keras中的LSTM层
from keras.layers import LSTM
model = Sequential()
model.add(Embedding(max_features, 32))
model.add(LSTM(32))
model.add(Dense(1, activation = 'sigmoid'))
model.compile(optimizer = 'rmsprop',
loss = 'binary_crossentropy',
metrics = ['acc'])
history = model.fit(input_train, y_train,
epochs = 10,
batch_size = 128,
validation_split = 0.2)
E:\develop_tools\Anaconda\envs\py36\lib\site-packages\tensorflow_core\python\framework\indexed_slices.py:424: UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory.
"Converting sparse IndexedSlices to a dense Tensor of unknown shape. "
Train on 20000 samples, validate on 5000 samples
Epoch 1/10
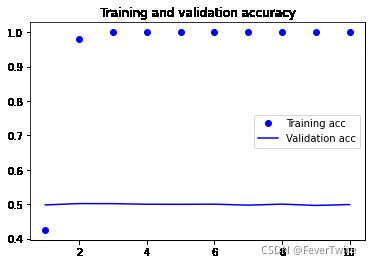
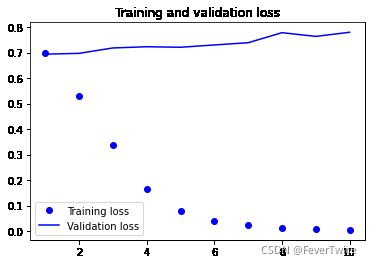
20000/20000 [==============================] - 61s 3ms/step - loss: 0.5330 - acc: 0.7372 - val_loss: 0.4527 - val_acc: 0.7856
Epoch 2/10
20000/20000 [==============================] - 61s 3ms/step - loss: 0.2970 - acc: 0.8835 - val_loss: 0.3529 - val_acc: 0.8548
Epoch 3/10
20000/20000 [==============================] - 61s 3ms/step - loss: 0.2362 - acc: 0.9089 - val_loss: 0.4686 - val_acc: 0.8236
Epoch 4/10
20000/20000 [==============================] - 61s 3ms/step - loss: 0.2057 - acc: 0.9233 - val_loss: 0.2931 - val_acc: 0.8764
Epoch 5/10
20000/20000 [==============================] - 62s 3ms/step - loss: 0.1801 - acc: 0.9357 - val_loss: 0.3112 - val_acc: 0.8762
Epoch 6/10
20000/20000 [==============================] - 65s 3ms/step - loss: 0.1611 - acc: 0.9420 - val_loss: 0.2988 - val_acc: 0.8818
Epoch 7/10
20000/20000 [==============================] - 62s 3ms/step - loss: 0.1519 - acc: 0.9485 - val_loss: 0.3054 - val_acc: 0.8890
Epoch 8/10
20000/20000 [==============================] - 62s 3ms/step - loss: 0.1366 - acc: 0.9525 - val_loss: 0.3484 - val_acc: 0.8884
Epoch 9/10
20000/20000 [==============================] - 63s 3ms/step - loss: 0.1254 - acc: 0.9567 - val_loss: 0.3382 - val_acc: 0.8870
Epoch 10/10
20000/20000 [==============================] - 64s 3ms/step - loss: 0.1138 - acc: 0.9625 - val_loss: 0.3998 - val_acc: 0.8762
# 画图
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
写在最后
注:本文代码来自《Python 深度学习》,做成电子笔记的方式上传,仅供学习参考,作者均已运行成功,如有遗漏请练习本文作者
各位看官,都看到这里了,麻烦动动手指头给博主来个点赞8,您的支持作者最大的创作动力哟!
<(^-^)>
才疏学浅,若有纰漏,恳请斧正
本文章仅用于各位同志作为学习交流之用,不作任何商业用途,若涉及版权问题请速与作者联系,望悉知