【模型推理】谈谈 darknet yolo 的 route 算子
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
O_o >_< o_O O_o ~_~ o_O
本文聊一聊 darknet yolo 网络中的 route 算子。
yolo 是目标检测算法落地常用的网络,具有速度快、精度高的优点,相信很多同学都熟悉,route 层在 yolov1、yolov2、yolov3、yolov4 中均有出现,yolov4 tiny 中的 route 又有了一些新特性,现在的它既能做类似 concatenate 的拼接,也能做类似 slice 的切割,算子功能十分丰富。这里把 route 拿出来聊一聊,主要说一下它的功能、与 darknet 源码实现。
文章目录
-
- 1、route 化作 concatenate
- 2、route 化作 slice
- 3、route 化作恒等映射
- 4、darknet 源码解读
1、route 化作 concatenate
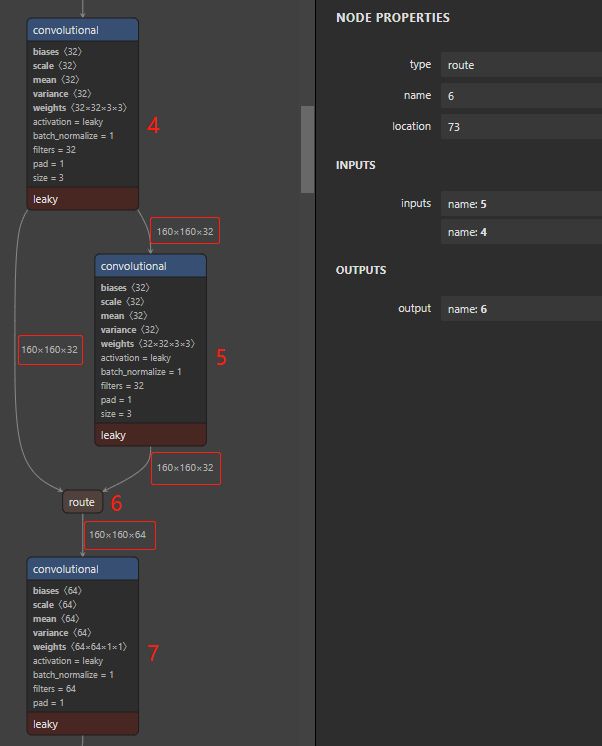
上面说过 route 能化作 concatenate,来完成拼接的操作,来看看 route 是怎么样幻化成一缕 convatenate 的,下面一张图就可以看明白,看右侧 route 参数栏可知,route 层的输入为 4 和 5,即接两个大卷积输入,维度分别为 160 x 160 x 32、160 x 160 x 32,这里 route 的作用就是把这两个大卷积的输出做拼接,可以看到经 route 作用后的输出维度为 160 x 160 x 64,64 就是 32 + 32 来的。
2、route 化作 slice
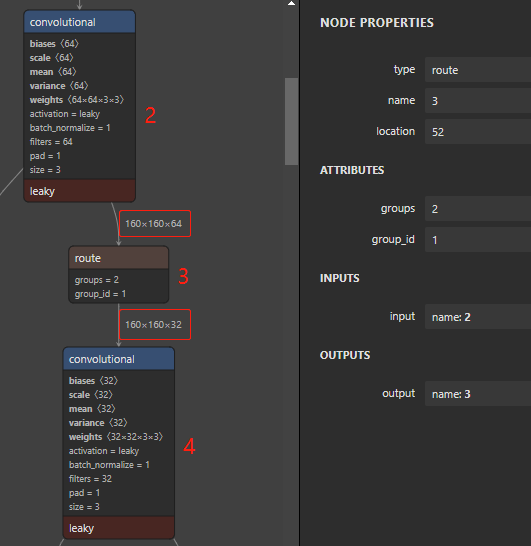
route 除了能化作 concatenate,还能化作 slice 来完成切割的操作,让我们来看看 route 是怎么样幻化成一缕 slice 的。同样来看下面这张图,这时候的 route 只有一个输入,即 2 号大卷积,然后你再仔细观察会发现还有 groups 和 group_id 两个奇怪的参数,这两个参数就是拿来做 切割 的参数。groups 的意思是把输入切成 groups 份,group_id 的意思是拿 第 group_id 索引的数据传出给下一层,所以 yolo 的 route 切割其实和 slice 又不太一样,route 切割后是要了一份丢了一份 (可能是防止过拟合),而 slice 切割后往往是两份都要,这个坑大家需要注意一下。
3、route 化作恒等映射
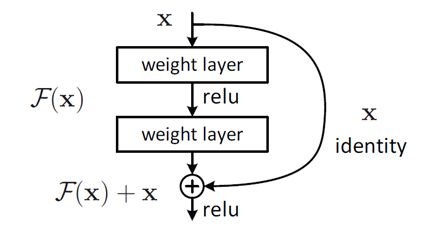
这个其实是我猜的,先来说下什么是恒等映射,恒等映射是 resnet 残差结构中的一个概念,如下图,恒等映射的意思就是把输入 x 原模原样的通过一个畅通无阻的高速路给传递过去。为什么要做这个操作呢,有了恒等映射,网络再深我也能通过这个小道把信息给你传递下去,且 x 的导数为 1,也可防止回传时梯度消失,关键还不增加额外计算量。
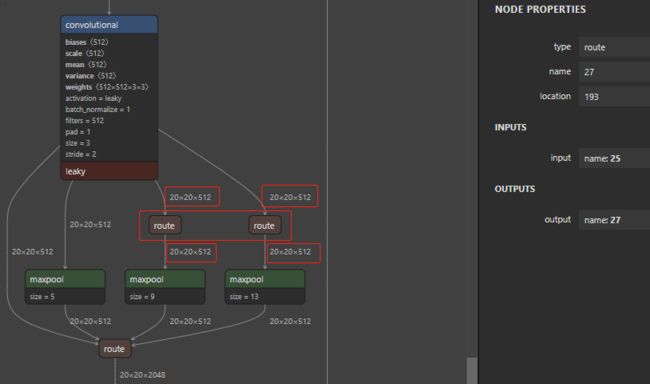
回到我们的 route,来看一下下面这张图,可以看到框起来这两个 route 其实啥也没做,就是原封不动的将 20 x 20 x 512 维度的数据传递下去,这是不是和 恒等映射 异曲同工。
4、darknet 源码解读
先看下 route_layer 的头:
#ifndef ROUTE_LAYER_H
#define ROUTE_LAYER_H
#include "network.h"
#include "layer.h"
typedef layer route_layer;
#ifdef __cplusplus
extern "C" {
#endif
route_layer make_route_layer(int batch, int n, int *input_layers, int *input_size, int groups, int group_id);
void forward_route_layer(const route_layer l, network_state state);
void backward_route_layer(const route_layer l, network_state state);
void resize_route_layer(route_layer *l, network *net);
#ifdef GPU
void forward_route_layer_gpu(const route_layer l, network_state state);
void backward_route_layer_gpu(const route_layer l, network_state state);
#endif
#ifdef __cplusplus
}
#endif
#endif
其中有几个比较关键的函数声明,forward_route_layer 和 backward_route_layer 是 cpu 上的前向和后向,forward_route_layer_gpu 和 backward_route_layer_gpu 是 gpu 上的前向和后向。make_route_layer 是用于构建 route 层的,里面会调 cpu 和 gpu 的前向和后面,当然 gpu 的话需要你开了 gpu 才会去调,resize_route_layer 是经过 route 层作用后数据维度方面的变换。
来看一下 darknet 构建 route 的操作,darkent 里 src/ 有一个 darknet.c,里面的 main 是整个框架的入口,里面也提供了功能丰富的传参示例能够帮你快速应用 darkent 这个好用的框架。顺着 darknet.c 里的逻辑你会找到构建 route 层的代码:
else if(lt == ROUTE){
l = parse_route(options, params);
int k;
for (k = 0; k < l.n; ++k) {
net.layers[l.input_layers[k]].use_bin_output = 0;
net.layers[l.input_layers[k]].keep_delta_gpu = 1;
}
我们来看看 parse_route 做了什么:
route_layer parse_route(list *options, size_params params)
{
char *l = option_find(options, "layers");
if(!l) error("Route Layer must specify input layers");
int len = strlen(l);
int n = 1;
int i;
for(i = 0; i < len; ++i){
if (l[i] == ',') ++n;
}
int* layers = (int*)xcalloc(n, sizeof(int));
int* sizes = (int*)xcalloc(n, sizeof(int));
for(i = 0; i < n; ++i){
int index = atoi(l);
l = strchr(l, ',')+1;
if(index < 0) index = params.index + index;
layers[i] = index;
sizes[i] = params.net.layers[index].outputs;
}
int batch = params.batch;
int groups = option_find_int_quiet(options, "groups", 1);
int group_id = option_find_int_quiet(options, "group_id", 0);
route_layer layer = make_route_layer(batch, n, layers, sizes, groups, group_id);
convolutional_layer first = params.net.layers[layers[0]];
layer.out_w = first.out_w;
layer.out_h = first.out_h;
layer.out_c = first.out_c;
for(i = 1; i < n; ++i){
int index = layers[i];
convolutional_layer next = params.net.layers[index];
if(next.out_w == first.out_w && next.out_h == first.out_h){
layer.out_c += next.out_c;
}else{
fprintf(stderr, " The width and height of the input layers are different. \n");
layer.out_h = layer.out_w = layer.out_c = 0;
}
}
layer.out_c = layer.out_c / layer.groups;
layer.w = first.w;
layer.h = first.h;
layer.c = layer.out_c;
if (n > 3) fprintf(stderr, " \t ");
else if (n > 1) fprintf(stderr, " \t ");
else fprintf(stderr, " \t\t ");
fprintf(stderr, " ");
if (layer.groups > 1) fprintf(stderr, "%d/%d", layer.group_id, layer.groups);
else fprintf(stderr, " ");
fprintf(stderr, " -> %4d x%4d x%4d \n", layer.out_w, layer.out_h, layer.out_c);
return layer;
}
其中关键的是:
route_layer layer = make_route_layer(batch, n, layers, sizes, groups, group_id);
这就来到了上面 route_layer 头里的 make_route_layer 了:
route_layer make_route_layer(int batch, int n, int *input_layers, int *input_sizes, int groups, int group_id)
{
fprintf(stderr,"route ");
route_layer l = { (LAYER_TYPE)0 };
l.type = ROUTE;
l.batch = batch;
l.n = n;
l.input_layers = input_layers;
l.input_sizes = input_sizes;
l.groups = groups;
l.group_id = group_id;
int i;
int outputs = 0;
for(i = 0; i < n; ++i){
fprintf(stderr," %d", input_layers[i]);
outputs += input_sizes[i];
}
outputs = outputs / groups;
l.outputs = outputs;
l.inputs = outputs;
//fprintf(stderr, " inputs = %d \t outputs = %d, groups = %d, group_id = %d \n", l.inputs, l.outputs, l.groups, l.group_id);
l.delta = (float*)xcalloc(outputs * batch, sizeof(float));
l.output = (float*)xcalloc(outputs * batch, sizeof(float));
l.forward = forward_route_layer;
l.backward = backward_route_layer;
#ifdef GPU
l.forward_gpu = forward_route_layer_gpu;
l.backward_gpu = backward_route_layer_gpu;
l.delta_gpu = cuda_make_array(l.delta, outputs*batch);
l.output_gpu = cuda_make_array(l.output, outputs*batch);
#endif
return l;
}
来看一下这个函数,传参中 n 是输入层的个数,groups 和 group_id 就是前面提到的 route 作 slice 的参数,由下面定义可以知道 groups 默认会是 1,group_id 默认会是 0,也就是当 route 没有 groups 参数时,上面函数中的 outputs = outputs / groups 和 group_id 偏移就相当于啥都没做。
int groups = option_find_int_quiet(options, "groups", 1);
int group_id = option_find_int_quiet(options, "group_id", 0);
来看一下 forward_route_layer:
void forward_route_layer(const route_layer l, network_state state)
{
int i, j;
int offset = 0;
for(i = 0; i < l.n; ++i){
int index = l.input_layers[i];
float *input = state.net.layers[index].output;
int input_size = l.input_sizes[i];
int part_input_size = input_size / l.groups;
for(j = 0; j < l.batch; ++j){
//copy_cpu(input_size, input + j*input_size, 1, l.output + offset + j*l.outputs, 1);
copy_cpu(part_input_size, input + j*input_size + part_input_size*l.group_id, 1, l.output + offset + j*l.outputs, 1);
}
//offset += input_size;
offset += part_input_size;
}
}
最关键的实现很简单就是在 copy_cpu 的一个赋值语句,其实想想也是,route 并没有做什么复杂的操作,拼接 或者 切割 或者 链路 的操作用一些指针偏移和赋值就可以实现了。
void copy_cpu(int N, float *X, int INCX, float *Y, int INCY)
{
int i;
for(i = 0; i < N; ++i) Y[i*INCY] = X[i*INCX];
}
同样,高性能计算离不开 cuda,来看一下 forward_route_layer_gpu 的操作:
void forward_route_layer_gpu(const route_layer l, network_state state)
{
if (l.stream >= 0) {
switch_stream(l.stream);
}
if (l.wait_stream_id >= 0) {
wait_stream(l.wait_stream_id);
}
int i, j;
int offset = 0;
for(i = 0; i < l.n; ++i){
int index = l.input_layers[i];
float *input = state.net.layers[index].output_gpu;
int input_size = l.input_sizes[i];
int part_input_size = input_size / l.groups;
for(j = 0; j < l.batch; ++j){
//copy_ongpu(input_size, input + j*input_size, 1, l.output_gpu + offset + j*l.outputs, 1);
//simple_copy_ongpu(input_size, input + j*input_size, l.output_gpu + offset + j*l.outputs);
simple_copy_ongpu(part_input_size, input + j*input_size + part_input_size*l.group_id, l.output_gpu + offset + j*l.outputs);
}
//offset += input_size;
offset += part_input_size;
}
}
route_gpu 的操作逻辑和 route_cpu 的一样,区别在于 gpu 的数据拷贝给并行起来了,来看一下 simple_copy_ongpu:
extern "C" void simple_copy_ongpu(int size, float *src, float *dst)
{
const int num_blocks = size / BLOCK + 1;
simple_copy_kernel << > >(size, src, dst);
CHECK_CUDA(cudaPeekAtLastError());
}
simple_copy_ongpu 里调了 simple_copy_kernel 这个 cuda kernel,我们来看一下:
__global__ void simple_copy_kernel(int size, float *src, float *dst)
{
int index = blockIdx.x*blockDim.x + threadIdx.x;
if (index < size)
dst[index] = src[index];
}
很简单,就是一个 device_to_device 的数据赋值过程。
说到这里应该是比较清晰的了,不得不感慨一句:C 语言看起来真清爽啊~
好了,有问题欢迎讨论,收工~
【公众号传送】
《【模型推理】谈谈 darknet yolo 的 route 算子》
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !
