Darknet——yolo3训练自己的数据集+在ros环境下实现目标检测实战教程(二)——训练自己的权重文件
文章目录
- 前言
- 一、安装darknet包和编译
- 工程包下载
- 编译
- 下载预训练模型并简单测试
- 二、制作自己的训练集并训练
- 准备数据集
- 数据标注
- 生成训练集和测试集
- 修改必要的文件
- 开始训练
- 总结
前言
经过之前的准备,基本已经具备了darknet运行的环境条件了,接下来是安装和编译darknet包和简单测试,准备自己的数据集训练自己的权重文件。
一、安装darknet包和编译
(一)代码下载:
可以直接参考github主页:https://github.com/leggedrobotics/darknet_ros
$mkdir -p catkin_workspace/src
$cd catkin_workspace/src
$git clone --recursive [email protected]:leggedrobotics/darknet_ros.git
$cd ../注意:不用这种方式下载下来可能文件不完整,也不能直接到github网站上去下载,那样下载下来的darknet文件夹里面是空的,只能通过git clone下载,且必须要加上--recursive才能够下载完全。但是这样克隆可能会报错误。因为需要配置ssh以及生成密匙,添加github ssh密钥,可以参考:
https://blog.csdn.net/qq_34706266/article/details/93228721
本人也将该工程包上到的自己的github,但是略有修改,需要的可以自取:
https://github.com/zhuzhengming/darknet_ros_yolo3
(二)编译
在工作空间下,执行命令:
$catkin_make -DCMAKE_BUILD_TYPE=Release此时会开始编译整个项目,编译完成后会检查{catkin_ws}/darknet_ros/darknet_ros/yolo_network_config/weights文件下有没有yolov2-tiny.weights和yolov3.weights两个模型文件,默认下载好的代码里面为了节省体积是不带这两个模型文件的。因此编译之后会自动开始下载模型文件,此时又是一段漫长的等待时间。
如果出现报错:NVCC src/caffe/layers/reduction_layer.cu nvcc fatal : Unsupported gpu architecture 'compute_30' Makefile:588: recipe for target '.build_release/cuda/src/caffe/layers/reduction_layer.o' failed make: *** [.build_release/cuda/src/caffe/layers/reduction_layer.o] Error 1
这里是算力不匹配,则需要在/workspace/src/darknet_ros/darknet_ros中的Cmakelist.txt文件或者是Makefile文件中根据自己显卡和cuda版本注释掉不要的选项。

如果安装了CUDA和CUDNN,可以在Makefile文件里修改参数:
GPU=0
CUDNN=0
OPENCV=1
OPENMP=0
DEBUG=1修改为:
GPU=1
CUDNN=1
OPENCV=1
OPENMP=0
DEBUG=1然后执行以下命令编译(每次修改Makefile后都要重新编译):
$ cd darknet
$ make(三)下载预训练模型和简单测试
这里lov3-tiny.weights,在根目录下下载:
$wget https://pjreddie.com/media/files/yolov3-tiny.weights简单测试:
在darknet根目录下:
1.图片测试:
$./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg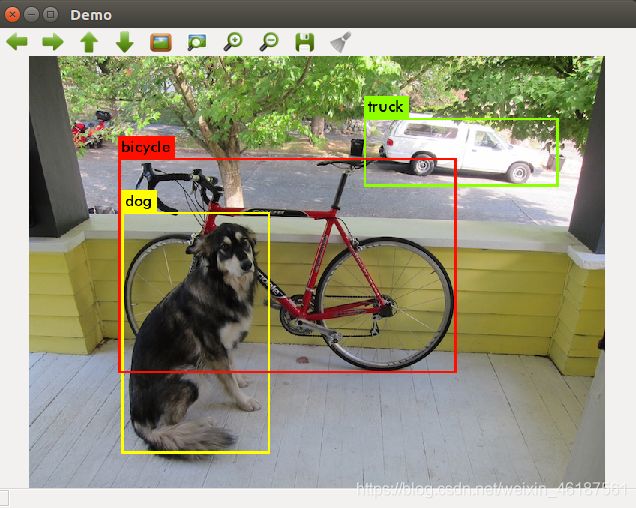
2.实时视频测试:
$./darknet detector demo cfg/voc.data cfg/yolov3-tiny.cfg yolov3-tiny.weights这里就完成了darknet的安装和编译和测试,接下来是训练自己的数据集。
二、制作自己的数据集并训练
(一)准备数据集
在darknet的根目录下,建立标准的voc数据集:
$ cd scripts
$ mkdir -p VOCdevkit && cd VOCdevkit
$ mkdir -p VOC2021 && cd VOC2021
$ mkdir -p Annotations && mkdir -p ImageSets && mkdir -p JPEGImages && mkdir -p labelsAnnotations:存放标注后生成的.xml文件
JPEGImages:存放自己的图片素材
labels:存放对于yolo需要的数据格式的标签文件
(二)数据标注
这里主要使用labelImg工具,这个在windows和linux都有版本,这里提供linux的安装方法:
$ sudo apt-get install pyqt5-dev-tools
$ sudo pip3 install lxml
$ git clone https://github.com/tzutalin/labelImg.git
$ cd labelImg
$ make all
$ python3 labelImg.py #打开labelImg“open file ” -----"create rectbox " -----"输入类别名称 "-----“change save dir ”-----"Save" open dir选择JPEGImages,change save dir选择Annotations。
(三)生成训练集和测试集
ImageSets目录中,新建Main目录,然后在Main目录中新建两个文本文档train.txt和val.txt.分别用于存放训练集的文件名列表和测试集的文件名列表:
$ cd ImageSets
$ mkdir -p Main && cd Main
$ touch train.txt test.txt yolov3提供了将VOC数据集转为YOLO训练所需要的格式的脚本,在scripts/voc_label.py文件中,做一些修改:
sets改为自己的训练集
classes为自己训练的类型

执行该脚本:
$ python scrips/voc_label.py在main文件下会生成train.txt和var.txt文件在darknet根目录下也会生成2021_train.txt和2021_var.txt文件,后面两个文件是带路径的,是训练需要的文件路径。
(四)修改必要的文件
1.修改data目录下的voc.names,修改为自己要训练的类型标签:

2.修改cfg目录下的voc.data文件:
主要是修改为自己的训练集路径和训练好的权重文件的保存路径,我这里用的绝对路径:
classes= 2
train = /home/zhuzhengming/workspace/src/darknet_ros/darknet/2019_train.txt
valid =/home/zhuzhengming/workspace/src/darknet_ros/darknet/2019_test.txt
names = /home/zhuzhengming/workspace/src/darknet_ros/darknet/data/voc.names
backup = /home/zhuzhengming/workspace/src/darknet_ros/darknet/backup3.修改cfg目录下的yolov3-tiny.cfg文件:
将里面的classes和fliters修改,有两处,filiters的计算方法为:3*(classes + 5):
如下为其中一处,修改参照此:
[convolutional]
size=1
stride=1
pad=1
filters=21
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=2
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=0(五)开始训练
1.生成预训练模型:
$ ./darknet partial cfg/yolov3-tiny.cfg yolov3-tiny.weights yolov3-tiny.conv.15 152.训练:
$ ./darknet detector train cfg/voc.data cfg/yolov3-tiny.cfg yolov3-tiny.conv.15 | tee person_train_log.txt在这个过程中在backup文件夹下会保存对应迭代次数的中间结果,前1000次内每100次保存一个,超过1000次,每1000保存一次。
3.用训练好的权重文件来测试:
图片测试:
这里选择一张自己数据集里的一张图片作为测试
$ ./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny_900.weights VOCdevkit\VOC2019\JPEGImages\1.png
视频实时测试:
$ ./darknet detector demo cfg/voc.data cfg/yolov3-tiny.cfg yolov3-tiny_900.weights总结
通过对darknet官方包的下载编译和重新配置,实现了其基本使用功能,在这基础上还完成了自己数据集的制作,并使用这个数据集来训练自己的权重文件,因为我训练的类别和次数较少,但是从测试结果来看,目标检测效果还不错。接下来是将这个深度学习网络在ros平台下使用实践。