python爬虫系列(二)—— weibo用户粉丝爬取
1. 前言
想爬取weibo的数据,首先想到的应该是微博开放平台,然后就开始创建一个移动应用,选择网页应用即可:

最后不需要提交审核,点击进入该应用:
然后,我们在接口管理中可以看见我们可以使用的接口,比如关系读取接口:

在爬取数据的时候需要获取粉丝的数据,我们需要得到粉丝,不妨看看:here
但是,在后面的注意事项中,很不幸:
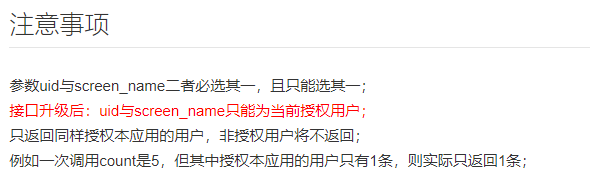
也就是只能得到当前自己的这些信息。故而却不能用。这里记一笔:登录授权
所以直接考虑使用原始的方式,访问:https://weibo.cn/,然后根据网页结构进行xpath、beautifulsoup、正则等解析即可。
但是在网页版中一个user_id最多可以获得200个user_id,不过多爬爬应该也就够用了。
2. mongodb的简单使用
安装下载地址:https://www.mongodb.com/try/download/community
安装教程:here
安装目录:D:\softwares\mongodb4.4.3
创建数据库的路径文件夹:D:\data\mongodb
然后,用D:\softwares\mongodb4.4.3\bin\mongod --dbpath D:\data\mongodb运行服务,可在浏览器中输入:http://localhost:27017/来访问:

不妨再创建一个日志目录:D:\data\log\mongodb.log
然后,安装到计算机的服务中去:
mongod.exe --dbpath D:\data\mongodb --logpath D:\data\log\mongodb.log --install --serviceName mongodb

管理员身份启动cmd运行:net start mongodb即可
由于启动需要使用mongo那个程序,不妨将之添加到环境变量中,即添加:D:\softwares\mongodb4.4.3\bin
然后,我们cmd,输入mongo即可进入数据库。
管理员创建成功,现在拥有了用户管理员
用户名:root
密码:123456
数据库:admin
use admin
db.createUser(
{
user: "root",
pwd: "123456",
roles: [ { role: "userAdminAnyDatabase", db: "admin" } ]
}
)
为了查看数据方便,还是希望使用一个图形界面工具来查看,官网正好提供了。here

3. 使用scrapy来爬取数据,连接数据库
先安装mongodb:
pip install pymongo -i https://pypi.douban.com/simple
pip install scrapy -i https://pypi.douban.com/simple
但是,在我的python3.7.0的环境中,发现了tensorflow和scrapy不能同时兼容的情况,tensorflow没问题,那么scrapy就用不了,而scrapy装好了,tensorflow就用不了。所以考虑再创建一个虚拟环境来进行操作,也就是scrapy不再安装再base环境下。
4.创建项目
scrapy startproject myspider
cd myspider
scrapy genspider weibo weibo.cn
使用pycharm打开该项目,然后在setting.py文件中配置下面的东西:
ROBOTSTXT_OBEY = False;- 设置
cookie;

cookie来源,就是自己在电脑登录后,然后使用浏览器自带的抓包工具进行分析查找即可。 - 开启
pipeline;
ITEM_PIPELINES = {
'day01.pipelines.Day01Pipeline': 300,
}
- 添加下
mongodb的配置;
# 数据库相关的配置信息
# MONGODB 主机环回地址127.0.0.1
MONGODB_HOST = 'localhost'
# 端口号,默认是27017
MONGODB_PORT = 27017
# 设置数据库名称
MONGODB_DBNAME = 'admin'
# 存放本次数据的表名称,分别是用户基本信息,用户粉丝,用户关注
USERINFO_TABLENAME = 'userinfo'
USERFANS_TABELNAME = 'fans'
USERFOLLOWS_TABLENAME = 'follows'
1. items.py定义爬虫程序中yield对象的数据字段
import scrapy
class Day01Item(scrapy.Item):
# define the fields for your item here like:
# 用户基本信息
uid = scrapy.Field()
nickname = scrapy.Field()
renzheng = scrapy.Field()
sex = scrapy.Field()
region = scrapy.Field()
brithday = scrapy.Field()
renzhenginfo = scrapy.Field()
abstract = scrapy.Field()
tags = scrapy.Field()
#微博数,关注数、粉丝数
weibonumber = scrapy.Field()
guanzhunumber = scrapy.Field()
fansnumber = scrapy.Field()
# 用户粉丝信息
fans = scrapy.Field()
# 用户粉丝信息
follows = scrapy.Field()
2. pipelines.py定义数据库的存储
import pymongo
import re
from scrapy.utils.project import get_project_settings
class Day01Pipeline:
def __init__(self):
settings = get_project_settings()
self.host = settings['MONGODB_HOST']
self.port = settings['MONGODB_PORT']
self.dbname = settings['MONGODB_DBNAME']
self.userinfo_tablename = settings['USERINFO_TABLENAME']
self.userfans_tablename = settings['USERFANS_TABELNAME']
self.userfollows_tablename = settings['USERFOLLOWS_TABLENAME']
self.client = pymongo.MongoClient(host=self.host, port=self.port)
self.db = self.client[self.dbname]
def process_item(self, item, spider):
self.userinfo_collection = self.db[self.userinfo_tablename]
self.fans_collection = self.db[self.userfans_tablename]
self.follows_collection = self.db[self.userfollows_tablename]
item = dict(item)
fans = item.pop("fans")
follows = item.pop("follows")
# 将用户的信息存入数据库中
self.userinfo_collection.insert(item)
for ele in fans:
# 在爬取到的用户主页的URL中,有两种格式,① https://weibo.cn/u/5578209720, ② https://weibo.cn/skipbeatz
# 由于我们需要从链接中提取uid,故而我们需要过滤掉第二种记录
if len(re.findall("https://weibo.cn/u/[0-9]{10}", ele['userlink'])) == 1:
ele['uid'] = item['uid']
ele['visited'] = 0
self.fans_collection.insert(ele)
for ele in follows:
if len(re.findall("https://weibo.cn/u/[0-9]{10}", ele['userlink'])) == 1:
ele['uid'] = item['uid']
ele['visited'] = 0
self.follows_collection.insert(ele)
return item
def spider_closed(self, spider):
pass
3. weibo.py爬虫程序
import scrapy
from ..items import Day01Item
import re
class WeiboSpider(scrapy.Spider):
# 固定格式
name = 'weibo'
allowed_domains = ['weibo.cn']
baseURL = "https://weibo.cn/u/"
wait_crawl_uids = ["1973566625"]
current_crawl_index = 0
uid = wait_crawl_uids[current_crawl_index]
url = baseURL + uid
start_urls = [url]
def parse(self, response):
# 1.得到微博数、关注数、粉丝数
items = Day01Item()
weibonumber = response.xpath("//div[@class='tip2']/span/text()").extract()[0]
focusandfans = response.xpath("//div[@class='tip2']/a/text()").extract()[:2]
items['weibonumber'] = weibonumber
items['guanzhunumber'] = focusandfans[0]
items['fansnumber'] = focusandfans[0]
# 2.获取用户基本信息
yield scrapy.Request(url="https://weibo.cn/" + str(self.uid) + "/info",
meta={
"items": items, 'uid': self.uid, "fans_offset": 1, "follows_offset": 1},
callback=self.parseUserInfo)
# 2.得到用户基本信息
def parseUserInfo(self, response):
basicInfo = response.xpath("/html/body/div[7]/text()").extract()[:7]
items = response.meta['items']
uid = response.meta['uid']
fans_offset = response.meta['fans_offset']
follows_offset = response.meta['follows_offset']
key = ['nickname', 'renzheng', 'sex', 'region', 'brithday', 'renzhenginfo', 'abstract']
for _, ele in enumerate(basicInfo):
if _ == 0:
items['uid'] = self.uid
items[key[_]] = ele # ele = re.split("[\:\:]+", ele)
# 3.获取用户标签
yield scrapy.Request(url="https://weibo.cn/account/privacy/tags/?uid=" + str(uid),
meta={
"items": items, 'uid': uid, "fans_offset": fans_offset,
"follows_offset": follows_offset}, callback=self.parseUserTag)
# 3.得到用户标签
def parseUserTag(self, response):
a_text = response.xpath("/html/body/div[7]//a/text()").extract()
tags = ""
for text in a_text:
if len(tags) == 0:
tags += text
else:
tags += ("," + text)
items = response.meta['items']
uid = response.meta['uid']
fans_offset = response.meta['fans_offset']
follows_offset = response.meta['follows_offset']
items['tags'] = tags
# 4.用户粉丝列表
yield scrapy.Request(url="https://weibo.cn/" + str(uid) + "/fans?page=" + str(1),
meta={
"items": items, 'uid': uid, "fans": [], "fans_offset": fans_offset,
"follows_offset": follows_offset},
callback=self.parseFans) # /1973566625/fans?page=1
# 4.得到用户粉丝列表
def parseFans(self, response):
items = response.meta['items']
fans = response.meta['fans']
uid = response.meta['uid']
fans_offset = response.meta['fans_offset']
follows_offset = response.meta['follows_offset']
# 获取能翻页的页数【20】
pageinfo = response.xpath("//div[@id='pagelist']/form/div/text()").extract()[-1][:-1]
total_number = re.split("[\/]", pageinfo)[-1]
if fans_offset < int(total_number):
fans_offset += 1
else:
items["fans"] = fans
# 5.得到用户关注列表
yield scrapy.Request(url="https://weibo.cn/" + str(uid) + "/follow?page=" + str(follows_offset),
meta={
"items": items, 'uid': uid, "follows": [], "fans_offset": fans_offset,
"follows_offset": follows_offset}, callback=self.parseFollow)
userlinks = response.xpath("//tr/td[2]/a[1]/@href").extract()
usernames = response.xpath("//tr/td[2]/a[1]/text()").extract()
userfansnumber = response.xpath("//tr/td[2]/text()").extract()
for i in range(len(userlinks)):
# 判断下这个用户主页链接中是否有uid
if len(re.findall("https://weibo.cn/u/[0-9]{10}", userlinks[i])) == 1:
if len(self.wait_crawl_uids) < 40000:
_current_uid = re.findall("[0-9]+", userlinks[i])[0]
self.wait_crawl_uids.append(_current_uid)
fans.append({
"userlink":userlinks[i], "username":usernames[i], "userfansnumber":userfansnumber[i]})
yield scrapy.Request(url="https://weibo.cn/" + str(uid) + "/fans?page=" + str(fans_offset),
meta={
"items": items, 'uid': uid, "fans": fans, "fans_offset": fans_offset,
"follows_offset": follows_offset}, callback=self.parseFans)
# 5.得到关注列表
def parseFollow(self, response):
items = response.meta['items']
follows = response.meta['follows']
uid = response.meta['uid']
fans_offset = response.meta['fans_offset']
follows_offset = response.meta['follows_offset']
# 获取能翻页的页数【20】
pageinfo = response.xpath("//div[@id='pagelist']/form/div/text()").extract()[-1][:-1]
total_number = re.split("[\/]", pageinfo)[-1]
if follows_offset < int(total_number):
follows_offset += 1
else:
items["follows"] = follows
# 6.返回最后的数据对象
yield items
userlinks = response.xpath("//tr/td[2]/a[1]/@href").extract()
usernames = response.xpath("//tr/td[2]/a[1]/text()").extract()
userfansnumber = response.xpath("//tr/td[2]/text()").extract()
for i in range(len(userlinks)):
# 判断下这个用户主页链接中是否有uid
# 判断下这个用户主页链接中是否有uid
if len(re.findall("https://weibo.cn/u/[0-9]{10}", userlinks[i])) == 1:
if len(self.wait_crawl_uids) < 40000:
_current_uid = re.findall("[0-9]+", userlinks[i])[0]
self.wait_crawl_uids.append(_current_uid)
follows.append(
{
"userlink": userlinks[i], "username": usernames[i], "userfansnumber": userfansnumber[i]})
yield scrapy.Request(url="https://weibo.cn/" + str(uid) + "/follow?page=" + str(follows_offset),
meta={
"items": items, 'uid': uid, "follows": follows, "fans_offset": fans_offset,
"follows_offset": follows_offset}, callback=self.parseFollow)
然后在mongodb的可视化工具中可看见抓取的数据。