Pytorch深度学习实践 第九讲 多分类问题
使用SoftMax分类器进行多分类问题(其输入不需要Relu激活,而是直接连接线性层),经过SoftMax分类器后满足:1.大于等于0,2.所有类别概率和为1.
Softmax函数:


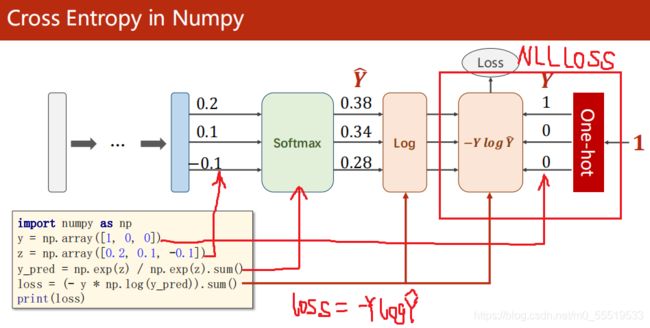
使用Numpy计算交叉熵损失的过程:(One-hot是一行或一列只有一位是1的矩阵)
使用Pytorch计算交叉熵损失:(torch.LongTensor([0])对应的one-hot是[1 0 0],即只有索引0对应的位置是1)

CrossEntropyLoss()就是将softmax-loss-NLLLoss合并成一步。
MNIST数据集代码示例(训练集60000,测试集10000):
import torch
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import torch.nn.functional as F
import torch.optim as optim
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307, ),(0.3081, ))
])
batch_size = 64
train_dataset = datasets.MNIST(root='E:\image-dataset\MNIST',train = True, transform = transform, download=True)
test_dataset = datasets.MNIST(root='E:\image-dataset\MNIST',train = False, transform = transform, download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size = batch_size, shuffle=True)
test_loader = DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=False)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.linear1 = torch.nn.Linear(784,512)
self.linear2 = torch.nn.Linear(512,256)
self.linear3 = torch.nn.Linear(256,128)
self.linear4 = torch.nn.Linear(128,64)
self.linear5 = torch.nn.Linear(64,10)
def forward(self,x):
x = x.view(-1,784)
x = F.relu(self.linear1(x))
x = F.relu(self.linear2(x))
x = F.relu(self.linear3(x))
x = F.relu(self.linear4(x))
return self.linear5(x) #注意最后一层不做激活
model = Net()
critarion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
def train(epoch):
running_loss = 0
for batch_idx, (inputs, target) in enumerate(train_loader):
optimizer.zero_grad()
outputs = model(inputs)
loss = critarion(outputs, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 ==299:
print('[%d,%5d] loss:%.3f' % (epoch+1,batch_idx+1,running_loss/300))
running_loss = 0
def test():
correct = 0
totel = 0
with torch.no_grad():
for data in test_loader: #data就代表测试集中的一组图像
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
totel += labels.size(0) #测试集中总的样本数目
correct += (predicted==labels).sum().item() #预测值=标签值就累加,得到预测正确的样本数目
print('测试集中预测正确率:%d %%' % (100*correct / totel))
if __name__== '__main__':
for epoch in range(10):
train(epoch)
test()
说明:
1. [-1,1]之间的输入对神经网络来说是最优的。
2.PIL读入的图像维度和Pytorch要求的tensor(C×W×H):

因此通过transforms.ToTensor()将读入图像转成pytorch需要的input Tensor。
3.transforms.Normalize((mean, ), (std, )),mean是均值,std是标准差(一般是通过计算数据集的所有像素值得出的),利用正态分布将像素值映射到[0, 1]。

4.模型设计:

x.view(-1, 784) 将原来的4阶Tensor转成2阶Tensor,N是几-1就是几。一个Mini-batch的图像集(N, 1, 28, 28)是四阶张量,得先处理成矩阵,即把28×28的图一行行拼起来,拼成784维的向量,一个Mini-batch就得到(N,784)的矩阵,一行是一幅图像,一组有N幅图。
5.root改成自己数据集的路径,或者默认下载。
6.with torch no_grad(): 下面都不会计算梯度
7.outputs是N×10的矩阵,一行是一个样本的输出结果,取一行中最大值的下标就是预测的分类结果。
_, predicted = torch.max(outputs.data, dim=1) dim=1代表横向检索
8.labels是M×1的矩阵,M是测试集的图像数,即测试集中图像对应的标签真实值。
输出结果:
[1, 300] loss:2.224
[1, 600] loss:1.015
[1, 900] loss:0.457
测试集中预测正确率:88 %
[2, 300] loss:0.342
[2, 600] loss:0.285
[2, 900] loss:0.238
测试集中预测正确率:94 %
[3, 300] loss:0.194
[3, 600] loss:0.179
[3, 900] loss:0.159
测试集中预测正确率:95 %
[4, 300] loss:0.140
[4, 600] loss:0.130
[4, 900] loss:0.121
测试集中预测正确率:96 %......