毕业设计之 - 题目:基于大数据的电商销售预测分析
文章目录
- 1 前言
- 2 开始分析
-
- 2.1 数据特征
- 2.2 各项投入与销售额之间的关系
- 2.3 建立销售额的预测模型
- 3 最后-毕设帮助
1 前言
Hi,大家好,这里是丹成学长,今天做一个电商销售预测分析,这只是一个demo,尝试在现有数据集上对销售数据进行预测
毕设帮助,开题指导,技术解答
746876041
2 开始分析
2.1 数据特征
# 导入包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set(style='whitegrid',palette="Set2")
plt.rcParams['font.sans-serif']=['Microsoft YaHei']
from warnings import filterwarnings
filterwarnings('ignore')
df = pd.read_csv('/home/kesci/input/data_baojie1642/baojie.csv')
查看缺失值
df.isnull().sum()/df.shape[0]

删除空值
df.dropna(inplace=True)
df.isnull().sum()

查看数据分布
df.hist(bins=40,figsize=(12,8))
plt.show()
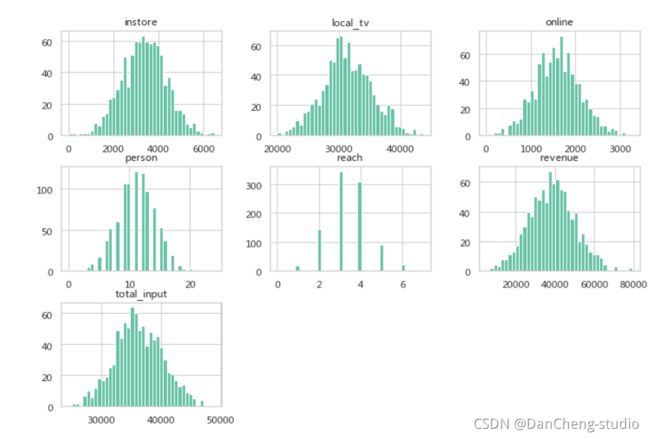
数据相对符合正太分布
2.2 各项投入与销售额之间的关系
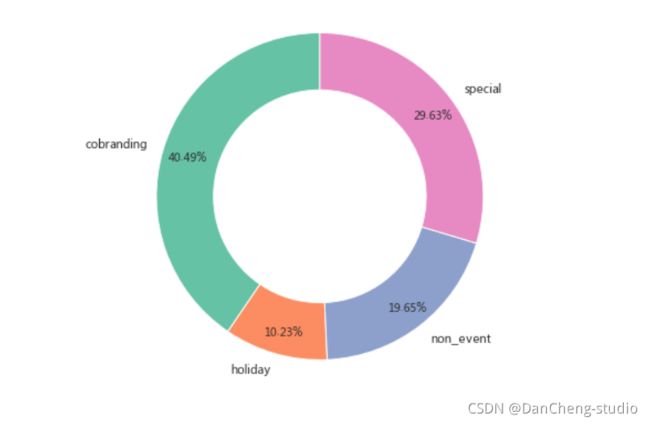
该时间段内不同活动期间所投入的费用占比
plt.figure(figsize=(8,6))
size = df.groupby('event').total_input.sum()
plt.pie(size.values,labels = size.index,wedgeprops={
'width':0.35,'edgecolor':'w'},
autopct='%.2f%%',pctdistance=0.85,startangle = 90)
plt.axis('equal')
plt.show()
推送次数
sns.jointplot(x='reach',y='revenue',data=df)
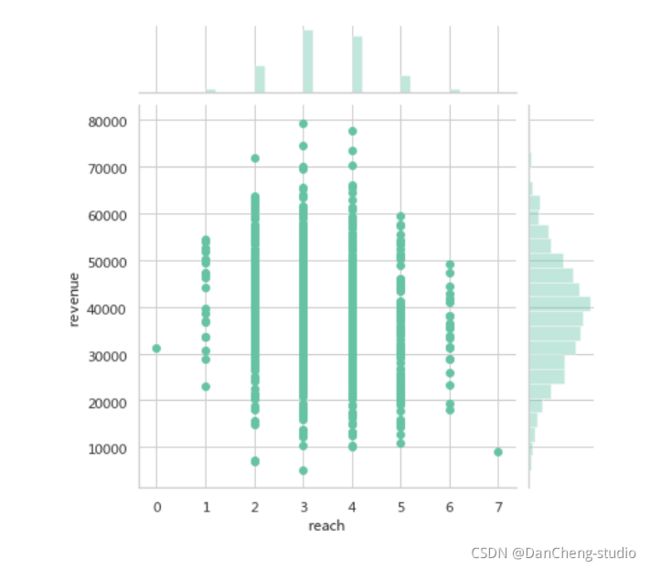
电视广告
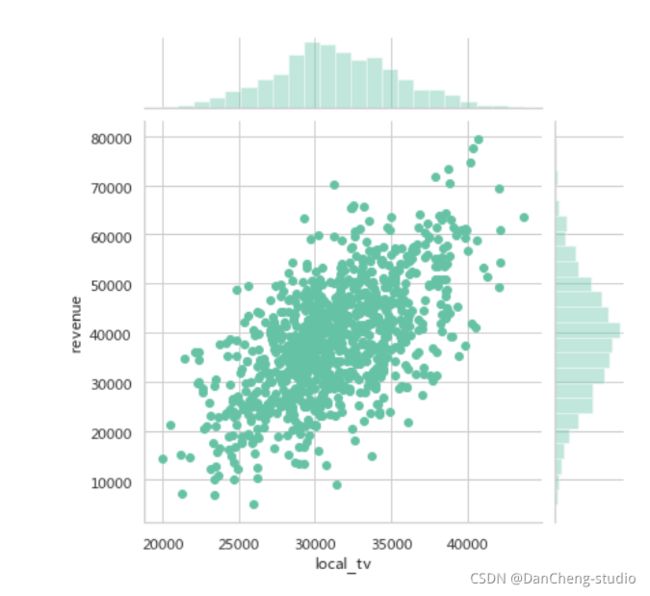
线上广告投入
sns.jointplot(x='online',y='revenue',data=df)
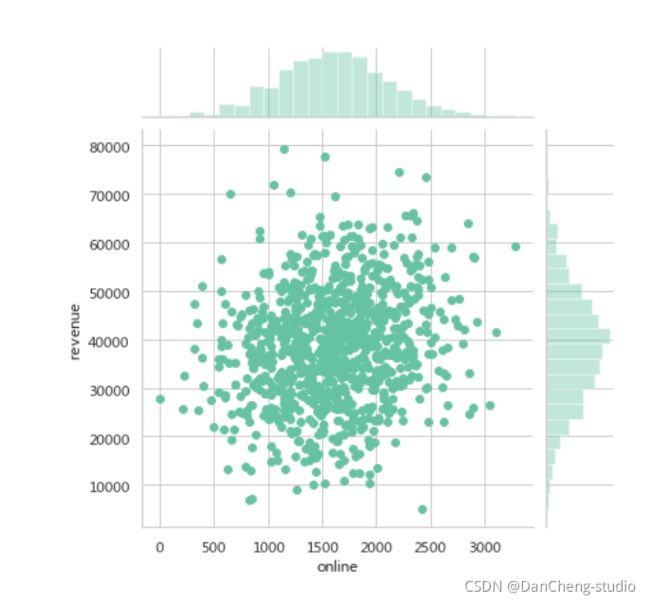
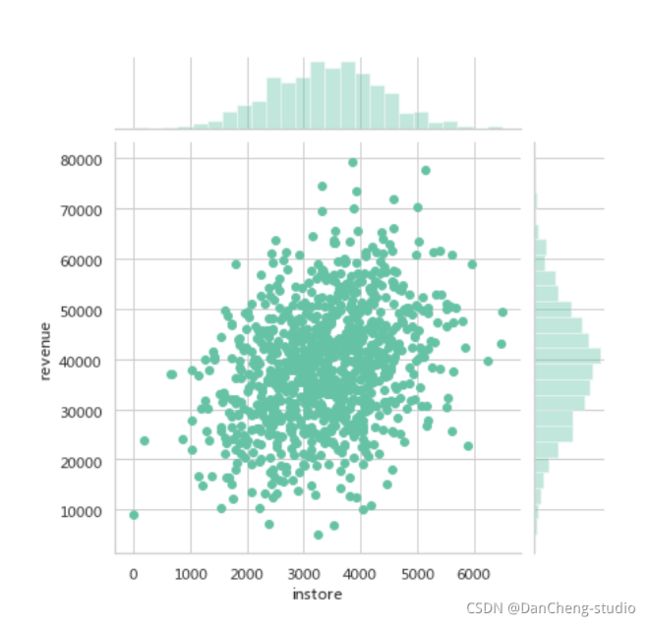
门店宣传投入
sns.jointplot(x='instore',y='revenue',data=df)
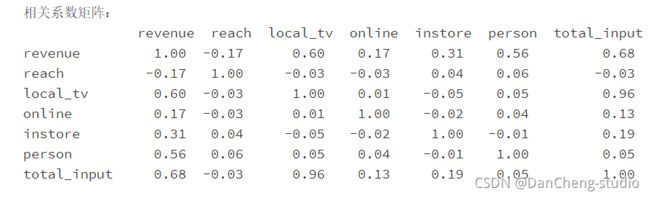
相关系数
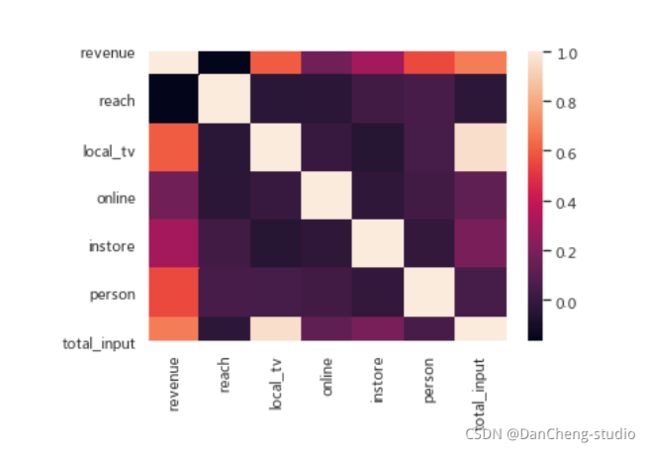
2.3 建立销售额的预测模型
选择最小二乘回归试试
# 部分代码
y = df['revenue']
x = df.drop(['revenue','event'],axis = 1)
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=20)
from sklearn.linear_model import LinearRegression
lr_model = LinearRegression()
lr_model.fit(x_train,y_train)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
print('预测测试集前5个结果为:\n',lr_model.predict(x_test)[:5])
print('测试集R^2值为:',lr_model.score(x_test,y_test))
from matplotlib import rcParams
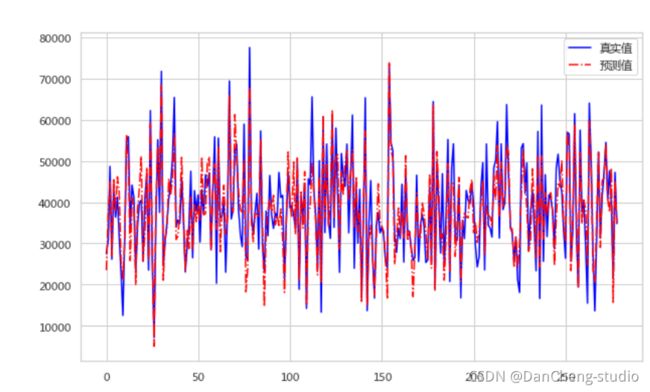
fig = plt.figure(figsize = (10,6))
y_pred = lr_model.predict(x_test)
plt.plot(range(y_test.shape[0]),y_test,color='blue',linewidth = 1.5,linestyle = '-')
plt.plot(range(y_test.shape[0]),y_pred,color='red',linewidth = 1.5,linestyle = '-.')
plt.legend(['真实值','预测值'])
plt.show()
3 最后-毕设帮助
毕设帮助,开题指导,技术解答
746876041
