记录一次系统性能调优过程
问题回顾
在线上环境,由于业务场景需要,要求程序能够在普通的4G机器中依然正常运行。
而原来的环境配置为8核16G,微服务部署,一共有6个功能模块。而现在要求在一台4核4G的设备上正常运行。
(想自学习编程的小伙伴请搜索圈T社区,更多行业相关资讯更有行业相关免费视频教程。完全免费哦!)
问题清单
-
模块合并过程中各种冲突,各种Bean无法正常加载
-
事件处理性能原来每秒3000~1w左右,现在突然骤降至几百左右;
-
事件存在丢失现象,而且丢失比较严重
-
发现系统cache一直在不断的上涨,free -m 后发现可余内存几乎用没了(剩余100M左右,其实就差不多是用完了,不会再降低)
问题排查
1. 代码冲突
- 包名冲突。不同模块的包名设计上有重复
- 类名冲突。
@Configuration @Bean @Controller @Service @Repository等注解中没有指定Bean实例的名称。
2. 事件处理性能慢
现有的处理流程如下:
项目采用SpringBoot构建,引入 spring-boot-stater-redis
- 通过HTTP接收到异步事件,存储到Redis;
- 存储的同时,将事件通过Redis的发布订阅发送到不同的处理单元进行处理;
- 每个事件处理单元通过Redis订阅,然后处理事件;
- 起一个定时器,每秒钟从Redis中查询一个时间窗口的事件,构建索引,然后bulkIndex到ES
2.1 问题发现
- Redis的订阅发布,内部会维护一个container线程,此线程会一直存在;
- 每次订阅,都会产生一个新的前缀为RedisListeningContainer-的线程处理;
- 通过jvisualvm.exe 查看线程数,该类线程数一直在飙升
2.2 问题定位
2.2.1 Redis订阅发布问题
程序中的实现如下:
@Bean
RedisMessageListenerContainer manageContainer(
RedisConnectionFactory factory, MessageListener listener) {
RedisMessageListenerContainer manageContainer =
new RedisMessageListenerContainer ();
manageContainer.setConnectionFactory(factory);
// manageContainer.setTaskExecutor();
}
代码中被注释掉的那一行,实际代码中是没有该行的,也就是没有设置taskExecutor
- 查询了spring-redis.xsd中关于
listener-container的说明,默认的task-executor和subscription-task-executor使用的是SimpleAsyncTaskExecutor。 - 在源码中的位置
RedisMessageListenerContainer.class
...
protected TaskExecutor createDefaultTaskExecutor() {
String threadNamePrefix = (beanName != null ? beanName + "-" :
DEFAULT_THREAD_NAME_PREFIX) ;
return new SimpleAsyncTaskExecutor(threadNamePrefix);
}
...
SimpleAsyncTaskExecutor.class
...
protected void doExecute(Runnable task) {
Thread thread =
(this.threadFactory != null
? this.threadFactory,newThread(task)
: createThread(task));
thread.start();
}
...
SimpleAsyncTaskExecutor的execute()方法,是很无耻的new Thread(),调用thread.start()来执行任务
2.2.2 事件处理都是耗时操作,造成线程数越来越多,甚至OOM
2.3 问题解决
找到问题的产生原因,主要的解决思路有三种:
-
配置
manageContainer.setTaskExecutor();然后选择自己创建的线程池; -
去掉一部分发布订阅,改用Spring提供的观察者模式,将绝大部分事件处理的场景,通过此方式完成发布。
SpringUtils.getApplicationContext() .publihEvent(newEventOperation(eventList)); -
采用
Rector模式实现事件的异步高效处理;
创建了2个线程组(参考netty的底层实现):
- 一个用于处理事件接收 “event-recv-executor-”
coreSize = N * 2,CPU密集型- 一个用于事件的异步处理 “event-task-executor-”
coreSize = N / 0.1,IO密集型
事件处理逻辑
@Override
public void onApplicationEvent (EventOperation event) {
eventTaskExecutor.execute(() -> {
doDealEventOperation(event);
});
}
3. 事件丢失
现有的处理流程如下:
项目采用SpringBoot构建,引入 spring-boot-stater-redis
- 后台维护了一个定时器,每秒钟从Redis中查询一个时间窗口的事件
3.1 问题发现
在后台定位日志输出,正常情况下,应该是每秒钟执行一次定时,
但实际是,系统并不保证一定能每隔1S执行一次,
由于系统中线程比较多,CPU的切换频繁,
导致定时有可能1S执行几次或者每隔几秒执行一次
3.2 问题定位
3.2.1 定时任务不可靠
由于定时并无法保证执行,而定时任务获取事件时,是按照时间窗口截取,
通过redisTemplate.opsForZSet().rangeByScore(key, minScore, maxScore)实现,
势必会造成有数据无法被加载到程序中,而一直保存在Redis中,无法获取,也无法删除
3.3 问题解决
找到问题的产生原因,主要的解决思路有两种:
-
加大容错率,将时间窗口拉大,原来是相隔1S的时间窗口,修改为相隔1MIN
【治标不治本,极端情况下,仍有可能造成该问题】; -
采用MQ消费,此方法需要额外部署MQ服务器,在集群配置高的情况下,可以采用,在配置低的机器下不合适;
-
采用阻塞队列,利用
Lock.newCondition()或者最普通的网络监听模式while()都可以;
本次问题中采用的是第三种形式。起一个单独的线程,阻塞监听。
- 事件接收后,直接塞到一个BlockingQueue中;
- 当BlockingQueue有数据时,While循环不阻塞,逐条读取队列中的信息;
- 每隔1000条数据,或者每隔1S,将数据写入ES,并分发其他处理流程
4. 系统cache一直在不断的上涨
在4G的机器下,发现经过一段时间的发包处理后,系统cache增长的非常快,最后几近于全部占满:
大概每秒钟10M的涨幅
4.1 问题发现
- 因为对于ES的了解,插入数据时,先写缓存,后fsync到磁盘上,因此怀疑ES可能存在问题;
- 项目中日志使用log4j2不当:
- 日志输出过多,
- 日志没有加判断:if (log.isInfoEnabled())
- 日志文件append过大,没有按照大小切分等(本项目此问题之前已解决)
4.2 问题定位
4.2.1 ES插入机制问题
经过隔段分析,将有可能出现问题的地方,分别屏蔽后,进行测试。 最终定位到,在ES批量写入数据时,才会出现cache大量增长的现象
4.3 问题解决
用命令查看内存free -m,
buffer: 作为buffer cache的内存,是块设备的读写缓冲区cached表示page cache的内存 和文件系统的cache- 如果
cached的值很大,说明cache住的文件数很多
ES操作数据的底层机制:
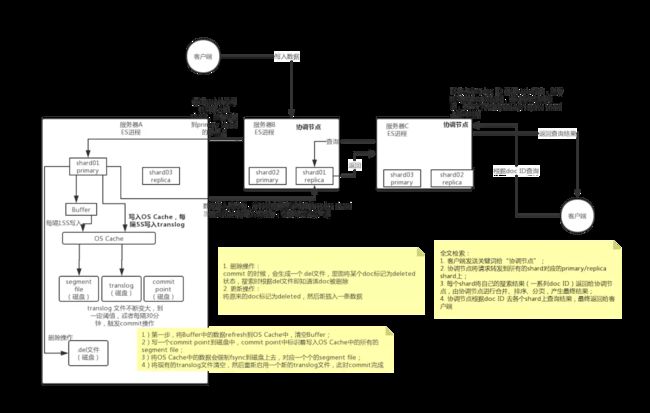

数据写入时,ES内存缓慢上升,是因为小文件过多(ES本身会在index时候建立大量的小文件),linux dentry 和 inode cache会增加。
本问题其实并没有完全解决,只是在一定程度上用性能换取缓存。
- 修改系统参数,提高slab内存释放的优先级:
echo 10000 > /proc/sys/vm/vfs_cache_pressure;
- 修改ES配置参数
## 这些参数是之前优化的
threadpool.bulk.type: fixed
threadpool.bulk.min: 10
threadpool.bulk.max: 10
threadpool.bulk.queue_size: 2000
threadpool.index.type: fixed
threadpool.index.size: 100
threadpool.index.queue_size: 1000
index.max_result_window: 1000000
index.query.bool.max_clause_count: 1024000
# 以下的参数为本次优化中添加的:
# 设置ES最大缓存数据条数和缓存失效时间
index.cache.field.max_size: 20000
index.cache.field.expire: 1m
# 当内存不足时,对查询结果数据缓存进行回收
index.cache.field.type: soft
# 当内存达到一定比例时,触发GC。默认为JVM的70%[内存使用最大值]
#indices.breaker.total.limit: 70%
# 用于fielddata缓存的内存数量,
# 主要用于当使用排序操作时,ES会将一些热点数据加载到内存中来提供客户端访问
indices.fielddata.cache.expire: 20m
indices.fielddata.cache.size: 10%
# 一个节点索引缓冲区的大小[max 默认无限制]
#indices.memory.index_buffer_size: 10%
#indices.memory.min_index_buffer_size: 48M
#indices.memory.max_index_buffer_size: 100M
# 执行数据过滤时的数据缓存,默认为10%
#indices.cache.filter.size: 10%
#indices.cache.filter.expire: 20m
# 当tranlog的大小达到此值时,会进行一次flush操作,默认是512M
index.translog.flush_threshold_size: 100m
# 在指定时间间隔内如果没有进行进行flush操作,会进行一次强制的flush操作,默认是30分钟
index.translog.flush_threshold_period: 1m
# 多长时间进行一次的磁盘操作,默认是5S
index.gateway.local.sync: 1s
历程回顾
- 对于本次调优过程,其主要修改方向还是代码,即代码的使用不当,或者考虑不周导致
- 其次,对于ES的底层实现机制并不很熟悉,定位到具体的问题所在;
- 本次优化过程中,涉及到对GC的定位,对Linux系统底层参数的配置等
- 由于日志传输采用HTTP,故每次传输都是新的线程。IO开销比较大,后续会考虑替换成长连接。
愿大家共同进步,共同成长。