潜在语义分析 (LSA),概率潜在语义分析 (PLSA)
目录
- 潜在语义分析 (latent semantic analysis, LSA)
-
- 单词向量空间与话题向量空间
-
- 单词向量空间 (word vector space)
- 话题向量空间 (topic vector space)
- 潜在语义分析算法 (矩阵奇异值分解算法)
- 非负矩阵分解算法 (non-negative matrix factorization, NMF)
-
- 非负矩阵分解
- 非负矩阵分解的形式化
- 非负矩阵分解算法
- 概率潜在语义分析 (probabilistic latent semantic analysis, PLSA)
-
- 生成模型
-
- 基本思想
- 生成模型的定义
- 生成模型学习的 EM 算法
- 共现模型
-
- 基本思想
- 共现模型的定义
- 共现模型与生成模型
潜在语义分析 (latent semantic analysis, LSA)
- 潜在语义分析是一种无监督学习方法,主要用于文本的话题分析,其特点是通过矩阵分解发现文本与单词之间的基于话题的语义关系
单词向量空间与话题向量空间
单词向量空间 (word vector space)
- 文本信息处理的一个核心问题是对文本的语义内容进行表示,并进行文本之间的语义相似度计算 (e.g. 文本信息检索、文本数据挖掘)。最简单的方法是利用单词向量空间模型
基本思想
- 给定一个文本,用一个向量表示该文本的 “语义”,向量的每一维对应一个单词,其数值为该单词在该文本中出现的频数或权值。文本集合中的每个文本都表示为一个向量,存在于一个向量空间。向量空间的度量,如**内积或标准化内积 (余弦相似度)**表示文本之间的 “语义相似度”
- 严格定义: 给定一个含有 n n n 个文本的集合 D = { d 1 , . . . , d n } D= \{d_1,...,d_n\} D={ d1,...,dn},以及在所有文本中出现的 m m m 个单词的集合 W = { w 1 , . . . , w m } W= \{w_1,...,w_m\} W={ w1,...,wm}。将单词在文本中出现的数据用一个单词-文本矩阵 (word-document matrix) 表示,记作 X X X

- 权值通常用单词频率-逆文本频率 (term frequency-inverse document frequency, TF-IDF) 表示,其定义是
 式中 tf i j \text{tf}_{ij} tfij 是单词 w i w_i wi 出现在文本 d j d_j dj 中的频数, tf ⋅ j \text{tf}_{\boldsymbol \cdot j} tf⋅j 是文本 j j j 中出现的所有单词的频数之和, df i \text{df}_i dfi 是含有单词 w i w_i wi 的文本数, df \text{df} df 是文本集合 D D D 的全部文本数
式中 tf i j \text{tf}_{ij} tfij 是单词 w i w_i wi 出现在文本 d j d_j dj 中的频数, tf ⋅ j \text{tf}_{\boldsymbol \cdot j} tf⋅j 是文本 j j j 中出现的所有单词的频数之和, df i \text{df}_i dfi 是含有单词 w i w_i wi 的文本数, df \text{df} df 是文本集合 D D D 的全部文本数
- 权值通常用单词频率-逆文本频率 (term frequency-inverse document frequency, TF-IDF) 表示,其定义是
- 优点:单词向量空间模型的优点是模型简单,计算效率高。由于单词的种类很多,而每个文本中出现单词的种类通常较少,所以单词-文本矩阵是一个稀疏矩阵,两个向量的内积计算只需要在其同不为零的维度上进行即可,需要的计算很少,可以高效地完成
- 缺点:内积相似度未必能够准确表达两个文本的语义相似度上。因为自然语言的单词具有一词多义性 (polysemy) 及多词一义性 (synonymy),即同一个单词可以表示多个语义,多个单词可以表示同一个语义,所以基于单词向量的相似度计算存在不精确的问题
- 例如在下面的单词-文本矩阵中,文本 d 1 d_1 d1 与 d 2 d_2 d2 相似度并不高,尽管两个文本的内容相似,这是因为同义词 “airplane” 与 “aircraft” 被当作了两个独立的单词,单词向量空间模型不考虑单词的同义性,在此情况下无法进行准确的相似度计算。另一方面,文本 d 3 d_3 d3 与 d 4 d_4 d4 有一定的相似度,尽管两个文本的内容并不相似,这是因为单词 “apple” 具有多义,可以表示 “apple computer” 和 “fruit”,单词向量空间模型不考虑单词的多义性,在此情况下也无法进行准确的相似度计算

- 例如在下面的单词-文本矩阵中,文本 d 1 d_1 d1 与 d 2 d_2 d2 相似度并不高,尽管两个文本的内容相似,这是因为同义词 “airplane” 与 “aircraft” 被当作了两个独立的单词,单词向量空间模型不考虑单词的同义性,在此情况下无法进行准确的相似度计算。另一方面,文本 d 3 d_3 d3 与 d 4 d_4 d4 有一定的相似度,尽管两个文本的内容并不相似,这是因为单词 “apple” 具有多义,可以表示 “apple computer” 和 “fruit”,单词向量空间模型不考虑单词的多义性,在此情况下也无法进行准确的相似度计算
话题向量空间 (topic vector space)
- 两个文本的语义相似度可以体现在两者的话题相似度上。一个文本一般含有若干个话题,如果两个文本的话题相似,那么两者的语义应该也相似。话题可以由若干个语义相
关的单词表示,同义词可以表示同一个话题,而多义词可以表示不同的话题。这样,基于话题的模型就可以解决上述基于单词的模型存在的问题
话题向量空间
- 假设所有文本共含有 k k k 个话题。假设每个话题由一个定义在单词集合 W W W 上的 m m m 维向量表示,称为话题向量,即
 其中 t i l t_{il} til 是单词 w i w_i wi 在话题 t l t_l tl 的权值,权值越大,该单词在该话题中的重要度就越高。这 k k k 个话题向量 t 1 , . . . , t k t_1,..., t_k t1,...,tk 张成一个话题向量空间 (topic vector space),维数为 k k k。注意话题向量空间 T T T 是单词向量空间 X X X 的一个子空间
其中 t i l t_{il} til 是单词 w i w_i wi 在话题 t l t_l tl 的权值,权值越大,该单词在该话题中的重要度就越高。这 k k k 个话题向量 t 1 , . . . , t k t_1,..., t_k t1,...,tk 张成一个话题向量空间 (topic vector space),维数为 k k k。注意话题向量空间 T T T 是单词向量空间 X X X 的一个子空间 - 话题向量空间 T T T 也可以表示为一个矩阵,称为单词-话题矩阵 (word-topic matrix),记作

文本在话题向量空间的表示
- 现在考虑文本集合 D D D 的文本 d j d_j dj,在单词向量空间中由一个向量 x j x_j xj 表示,将 x j x_j xj 投影到话题向量空间 T T T 中,得到在话题向量空间的一个向量 y j y_j yj, y j y_j yj 是一个 k k k 维向量。也就是说
x j ≈ T y j x_j\approx Ty_j xj≈Tyj可以看出, y j y_j yj 的 k k k 个分量就代表文本 d j d_j dj 在 k k k 个话题上的权值,权值越大,该话题在该文本中的重要度就越高 - 将 Y = [ y 1 y 2 . . . y n ] Y=\begin{bmatrix}y_1&y_2&...&y_n\end{bmatrix} Y=[y1y2...yn] 称为话题-文本矩阵 (topic-document matrix),表示话题在文本中出现的情况. 所以,单词-文本矩阵 X X X 可以近似的表示为单词-话题矩阵 T T T 与话题-文本矩阵 Y Y Y 的乘积形式
X ≈ T Y X\approx TY X≈TY
潜在语义分析
- 潜在语义分析就是确定话题向量空间 T T T 以及文本在话题空间的表示 Y Y Y, 使两者的乘积是单词-文本矩阵 X X X 的近似
- 经过潜在语义分析后,在话题向量空间中,两个文本 d i d_i di 与 d j d_j dj 的相似度可以由对应的向量的内积即 y i ⋅ y j y_i\cdot y_j yi⋅yj 表示 (注意话题的个数通常远远小于单词的个数,话题向量空间模型更加抽象)
潜在语义分析算法 (矩阵奇异值分解算法)
- 潜在语义分析根据确定的话题个数 k k k 对单词-文本矩阵 X X X 进行截断奇异值分解,将其左矩阵 U k U_k Uk 作为话题向量空间,将其对角矩阵与右矩阵的乘积 Σ k V k T z W \Sigma_kV_k^TzW ΣkVkTzW 作为文本在话题向量空间的表示
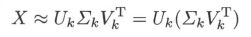
LSA 如果碰到新的文本还要连同之前的所有文本一起重新进行矩阵分解,感觉还是不太方便
非负矩阵分解算法 (non-negative matrix factorization, NMF)
非负矩阵分解
- 若一个矩阵 X X X 的所有元素非负,则称该矩阵为非负矩阵,记作 X ≥ 0 X\geq0 X≥0
- 给定一个非负矩阵 X ≥ 0 X\geq 0 X≥0,找到两个非负矩阵 W ≥ 0 W\geq0 W≥0 和 H ≥ 0 H\geq0 H≥0,使得
X ≈ W H X\approx WH X≈WH称为非负矩阵分解 - 可见,非负矩阵分解也可以用于话题分析。由于通常单词-文本矩阵 X X X 是非负的,因此可以对 X X X 进行非负矩阵分解,将其左矩阵 W W W 作为话题向量空间,将其右矩阵 H H H 作为文本在话题向量空间的表示。称 W W W 为基矩阵, H H H 为系数矩阵; 相比使用奇异值分解的潜在语义分析算法,非负矩阵分解具有很直观的解释,话题向量和文本向量都非负,对应着 “伪概率分布”,向量的线性组合表示局部叠加构成整体
非负矩阵分解的形式化
- 非负矩阵分解可以形式化为最优化问题求解
首先定义损失函数:
- (1) 平方损失: 其下界是 0,当且仅当 A = B A=B A=B 时达到下界

- (2) 散度损失函数:其下界也是 0,当且仅当 A = B A=B A=B 时达到下界。 A A A 和 B B B 不对称。当 ∑ i , j a i j = ∑ i j b i j = 1 \sum_{i,j}a_{ij}=\sum_{ij}b_{ij}=1 ∑i,jaij=∑ijbij=1 时散度损失函数退化为 Kullback-Leiber 散度或相对熵,这时 A A A 和 B B B 是概率分布

那么这个散度损失函数是怎么来的呢?
首先假设我们使用一阶泰勒展开 f ( y ) ≈ f ( x ) + ∇ f ( x ) ( y − x ) f(y)\approx f(x)+\nabla f(x)(y-x) f(y)≈f(x)+∇f(x)(y−x) 去近似估计函数值,那么估计误差为 f ( x ) − f ( y ) + ∇ f ( x ) ( y − x ) f(x)-f(y)+\nabla f(x)(y-x) f(x)−f(y)+∇f(x)(y−x)可以将其进行推广得到 Bregman 距离:
B ϕ ( x ∣ ∣ y ) = ϕ ( x ) − ϕ ( y ) − ⟨ ∇ ϕ ( x ) , x − y ⟩ B_\phi(x||y)=\phi(x)-\phi(y)-\langle\nabla \phi(x),x-y\rangle Bϕ(x∣∣y)=ϕ(x)−ϕ(y)−⟨∇ϕ(x),x−y⟩其中, ϕ \phi ϕ 为定义在闭合凸集的连续可微凸函数, ⟨ ⋅ , ⋅ ⟩ \langle\cdot,\cdot\rangle ⟨⋅,⋅⟩ 表示向量内积;如果 ϕ \phi ϕ 取信息熵的形式:
ϕ ( x ) = ∑ i = 1 n x i ln x i \phi(x)=\sum_{i=1}^nx_i\ln x_i ϕ(x)=i=1∑nxilnxi则
B ϕ ( x ∣ ∣ y ) = ∑ i = 1 n ( y i ln y i x i − y i + x i ) B_\phi(x||y)=\sum_{i=1}^n\left(y_i\ln\frac{y_i}{x_i}-y_i+x_i\right) Bϕ(x∣∣y)=i=1∑n(yilnxiyi−yi+xi)这样就可以得出散度损失函数
D ( A ∣ ∣ B ) = B ϕ ( b ∣ ∣ a ) = = ∑ i j ( a i j ln a i j b i j − a i j + b i j ) D(A||B)=B_\phi(b||a)==\sum_{ij}\left(a_{ij}\ln\frac{a_{ij}}{b_{ij}}-a_{ij}+b_{ij}\right) D(A∣∣B)=Bϕ(b∣∣a)==ij∑(aijlnbijaij−aij+bij)也就是说,散度损失函数就可以看作以 b b b 为基准点对 a a a 的信息熵进行一阶泰勒估计时的误差,直观上看,误差越小说明它们越接近
接着定义以下的最优化问题:

或

非负矩阵分解算法
- 考虑求解上面的两个最优化问题。由于目标函数 ∣ ∣ X − W H ∣ ∣ 2 ||X-WH||^2 ∣∣X−WH∣∣2 和 D ( X ∣ ∣ W H ) D(X||WH) D(X∣∣WH) 只是对变量 W W W 和 H H H 之一的凸函数,而不是同时对两个变量的凸函数,因此找到全局最优 (最小值) 比较困难,可以通过数值最优化方法求局部最优 (极小值)
- 梯度下降法比较容易实现,但是收敛速度慢。共轭梯度法收敛速度快,但实现比较复杂。Lee 和 Seung 提出了新的基于 “乘法更新规则” 的优化算法,交替地对 W W W 和 H H H 进行更新,其理论依据是下面的定理:

定理证明见 Algorithms for Non-negative Matrix Factorization (论文翻译)
非负矩阵分解算法 (只介绍损失函数为平方损失的算法)
- 最优化目标函数:

- 应用梯度下降法求解。首先求目标函数的梯度
 然后求得梯度下降法的更新规则,有
然后求得梯度下降法的更新规则,有
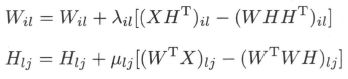 选取更新步长为
选取更新步长为
 即得乘法更新规则
即得乘法更新规则

- (1) 选取初始矩阵 W W W 和 H H H 为非负矩阵,可以保证迭代过程及结果的矩阵 W W W 和 H H H 均为非负
- (2) 每次迭代对 W W W 的列向量归一化,使基向量为单位向量
可见,乘法更新规则的迭代算法本质是梯度下降法,通过定义特殊的步长和非负的初始值,保证迭代过程及结果的矩阵 W W W 和 H H H 均为非负

概率潜在语义分析 (probabilistic latent semantic analysis, PLSA)
- 概率潜在语义分析受潜在语义分析的启发,1999 年由 Hofmann 提出,前者基于概率模型,后者基于非概率模型
- 概率潜在语义分析模型有生成模型,以及等价的共现模型。下面先介绍生成模型,然后介绍共现模型
生成模型
基本思想
- 生成模型将话题看作隐变量 z z z,文本和单词对看作观测变量 ( w , d ) (w,d) (w,d);整个模型表示文本生成话题,话题生成单词,从而得到单词-文本共现数据的过程。对文本集合进行概率潜在语义分析,就能够发现每个文本的话题,以及每个话题的单词
- 这里看到隐变量是不是一下就想到了 EM 算法?没错,生成模型也是 EM 算法的一个应用。这里的观测变量即为单词-文本对 ( w , d ) (w,d) (w,d),隐变量即为话题 z z z,目标是最大化单词-文本矩阵 T T T 的生成概率 (也就是极大化似然函数)
生成模型的定义
- 假设有单词集合 w = { w 1 , w 2 , . . , w M } w= \{w_1,w_2 ,..,w_M\} w={ w1,w2,..,wM},其中 M M M 是单词个数;文本 (指标) 集合 D = { d 1 , . . . , d N } D = \{d_1,...,d_N\} D={ d1,...,dN},其中 N N N 是文本个数;话题集合 Z = { z 1 , . . . , z k } Z = \{ z_1,...,z_k\} Z={ z1,...,zk},其中 K K K 是预先设定的话题个数
- 随机变量 w w w 取值于单词集合; 随机变量 d d d 取值于文本集合,随机变量 z z z 取值于话题集合; P ( d ) P(d) P(d) 表示生成文本 d d d 的概率, P ( z ∣ d ) P(z|d) P(z∣d) 表示文本 d d d 生成话题 z z z 的概率, P ( w ∣ z ) P(w|z) P(w∣z) 表示话题 z z z 生成单词 w w w 的概率 (也就是说,一个文本的内容由其相关话题决定, 一个话题的内容由其相关单词决定)
生成模型定义
- 生成模型通过以下步骤生成文本-单词共现数据:
- (1) 依据概率分布 P ( d ) P(d) P(d),从文本集合中随机选取一个文本 d d d,共生成 N N N 个文本; 针对每个文本,执行以下操作:
- (2) 在文本 d d d 给定条件下,依据条件概率分布 P ( z ∣ d ) P(z|d) P(z∣d),从话题集合随机选取一个话题 z z z,共生成 L L L 个话题,这里 L L L 是文本长度
- (3) 在话题 z z z 给定条件下,依据条件概率分布 P ( w ∣ z ) P(w|z) P(w∣z),从单词集合中随机选取一个单词 w w w
- 生成模型中,单词变量 w w w 与文本变量 d d d 是观测变量,话题变量 z z z 是隐变量。文本-单词共现数据 T T T 的生成概率为所有单词-文本对的生成概率的乘积,
 其中 n ( w , d ) n(w,d) n(w,d) 表示 ( w , d ) (w,d) (w,d) 的出现次数,每个单词-文本对 ( w , d ) (w,d) (w,d) 的生成概率由以下公式决定 (在生成模型中, w w w 与 d d d 是条件独立的):
其中 n ( w , d ) n(w,d) n(w,d) 表示 ( w , d ) (w,d) (w,d) 的出现次数,每个单词-文本对 ( w , d ) (w,d) (w,d) 的生成概率由以下公式决定 (在生成模型中, w w w 与 d d d 是条件独立的):
P ( w , d ) = P ( d ) P ( w ∣ d ) = P ( d ) ∑ z P ( w , z ∣ d ) = P ( d ) ∑ z P ( w ∣ z , d ) P ( z ∣ d ) = P ( d ) ∑ z P ( w ∣ z ) P ( z ∣ d ) \begin{aligned} P(w, d) &=P(d) P(w \mid d) \\ &=P(d) \sum_{z} P(w, z \mid d) \\ &=P(d) \sum_{z} P(w \mid z,d)P(z\mid d) \\ &=P(d) \sum_{z} P(w \mid z)P(z \mid d) \end{aligned} P(w,d)=P(d)P(w∣d)=P(d)z∑P(w,z∣d)=P(d)z∑P(w∣z,d)P(z∣d)=P(d)z∑P(w∣z)P(z∣d)
我们的目标是极大化文本-单词共现数据 T T T 的生成概率。如果直接定义单词与文本的共现概率 P ( w , d ) P(w,d) P(w,d),模型参数的个数是 O ( M ⋅ N ) O(M \cdot N) O(M⋅N)。而生成模型的参数个数只有 O ( M ⋅ K + N ⋅ K ) O(M\cdot K + N\cdot K) O(M⋅K+N⋅K)。现实中 K ≪ M K\ll M K≪M, 所以概率潜在语义分析通过话题对数据进行了更简洁地表示,减少了学习过程中过拟合的可能性
概率有向图模型
- 生成模型属于概率有向图模型,如图 18.2 所示。图中实心圆表示观测变量,空心圆表示隐变量,箭头表示概率依存关系,方框表示多次重复,方框内数字表示重复次数

生成模型学习的 EM 算法
- 我们的目标是最大化如下似然函数:
E 步:计算 Q Q Q 函数
- 模型参数 θ = { P ( w ∣ z ) , P ( z ∣ d ) } \theta=\{P(w \mid z),P(z \mid d)\} θ={ P(w∣z),P(z∣d)};设隐变量为
γ i j k = { 1 给 定 ( w i , d j ) , 话 题 为 k 0 e l s e \gamma_{ijk}=\begin{cases}1\quad\quad给定\ (w_i,d_j),话题为\ k \\0\quad\quad\ else \end{cases} γijk={ 1给定 (wi,dj),话题为 k0 else - 为方便起见,记 n ( w i , d j ) = n i j n(w_i,d_j)=n_{ij} n(wi,dj)=nij,则完全数据的似然为
P ( w , d , γ ∣ θ ) = ∏ i , j P ( w i , d j , γ ∣ θ ) n i j = ∏ i , j , k [ P ( d j ) P ( z k ∣ d j ) P ( w i ∣ z k ) ] n i j ⋅ γ i j k \begin{aligned} P(w,d,\gamma\mid \theta) &=\prod_{i,j}P(w_i,d_j,\gamma\mid \theta)^{n_{ij}} \\&=\prod_{i,j,k}\left[P(d_j)P(z_k \mid d_j)P(w_i \mid z_k) \right]^{n_{ij}\cdot\gamma_{ijk}} \end{aligned} P(w,d,γ∣θ)=i,j∏P(wi,dj,γ∣θ)nij=i,j,k∏[P(dj)P(zk∣dj)P(wi∣zk)]nij⋅γijk完全数据的对数似然为
log P ( w , d , γ ∣ θ ) = ∑ i , j , k n i j ⋅ γ i j k [ log P ( d j ) + log P ( z k ∣ d j ) + log P ( w i ∣ z k ) ] \begin{aligned} \log P(w,d,\gamma\mid \theta) &=\sum_{i,j,k}n_{ij}\cdot\gamma_{ijk}\left[\log P(d_j)+\log P(z_k \mid d_j)+\log P(w_i \mid z_k) \right] \end{aligned} logP(w,d,γ∣θ)=i,j,k∑nij⋅γijk[logP(dj)+logP(zk∣dj)+logP(wi∣zk)]为了计算上式在给定不完全数据下的对隐变量的期望,只需计算 γ i j k \gamma_{ijk} γijk 的条件期望 γ ^ i j k \hat\gamma_{ijk} γ^ijk
γ ^ i j k = E [ γ i j k ∣ w , d , θ − ] = P ( γ i j k = 1 ∣ w i , d j , θ − ) = P ( z k ∣ w i , d j , θ − ) = P ( z k , w i ∣ d j , θ − ) ∑ k P ( z k , w i ∣ d j , θ − ) = P ( z k ∣ d j ) P ( w i ∣ z k , d j , θ − ) ∑ k P ( z k ∣ d j ) P ( w i ∣ z k , d j , θ − ) = P ( z k ∣ d j ) P ( w i ∣ z k ) ∑ k P ( z k ∣ d j ) P ( w i ∣ z k ) \begin{aligned} \hat\gamma_{ijk}&=E[\gamma_{ijk}\mid w,d,\theta^-] \\&=P(\gamma_{ijk}=1\mid w_i,d_j,\theta^-) \\&=P(z_k\mid w_i,d_j,\theta^-) \\&=\frac{P(z_k,w_i\mid d_j,\theta^-)}{\sum_kP(z_k,w_i\mid d_j,\theta^-)} \\&=\frac{P(z_k\mid d_j)P(w_i\mid z_k,d_j,\theta^-)}{\sum_kP(z_k\mid d_j)P(w_i\mid z_k,d_j,\theta^-)} \\&=\frac{P(z_k\mid d_j)P(w_i\mid z_k)}{\sum_kP(z_k\mid d_j)P(w_i\mid z_k)} \end{aligned} γ^ijk=E[γijk∣w,d,θ−]=P(γijk=1∣wi,dj,θ−)=P(zk∣wi,dj,θ−)=∑kP(zk,wi∣dj,θ−)P(zk,wi∣dj,θ−)=∑kP(zk∣dj)P(wi∣zk,dj,θ−)P(zk∣dj)P(wi∣zk,dj,θ−)=∑kP(zk∣dj)P(wi∣zk)P(zk∣dj)P(wi∣zk)因此 Q Q Q 函数为
Q = ∑ i , j , k n i j ⋅ γ ^ i j k [ log P ( d j ) + log P ( z k ∣ d j ) + log P ( w i ∣ z k ) ] \begin{aligned} Q=\sum_{i,j,k}n_{ij}\cdot\hat\gamma_{ijk}\left[\log P(d_j)+\log P(z_k \mid d_j)+\log P(w_i \mid z_k) \right] \end{aligned} Q=i,j,k∑nij⋅γ^ijk[logP(dj)+logP(zk∣dj)+logP(wi∣zk)]省去常数项,可将 Q Q Q 函数简化为函数 Q ′ Q' Q′
Q ′ = ∑ i , j , k n i j ⋅ γ ^ i j k [ log P ( z k ∣ d j ) + log P ( w i ∣ z k ) ] \begin{aligned} Q'=\sum_{i,j,k}n_{ij}\cdot\hat\gamma_{ijk}\left[\log P(z_k \mid d_j)+\log P(w_i \mid z_k) \right] \end{aligned} Q′=i,j,k∑nij⋅γ^ijk[logP(zk∣dj)+logP(wi∣zk)]
M 步: 极大化 Q Q Q 函数
- 通过约束最优化求解 Q Q Q 函数的极大值,这时 P ( z k ∣ d j ) P(z_k\mid d_j) P(zk∣dj) 和 P ( w i ∣ z k ) P(w_i\mid z_k) P(wi∣zk) 是变量,满足约束条件
 应用拉格朗日法,引入拉格朗日乘子 τ k \tau_k τk 和 ρ j \rho_j ρj,定义拉格朗日函数 Λ \Lambda Λ
应用拉格朗日法,引入拉格朗日乘子 τ k \tau_k τk 和 ρ j \rho_j ρj,定义拉格朗日函数 Λ \Lambda Λ
 将拉格朗日函数 Λ \Lambda Λ 分别对 P ( z k ∣ d j ) P(z_k\mid d_j) P(zk∣dj) 和 P ( w i ∣ z k ) P(w_i\mid z_k) P(wi∣zk) 求偏导数,井令其等于 0,得到下面的方程组
将拉格朗日函数 Λ \Lambda Λ 分别对 P ( z k ∣ d j ) P(z_k\mid d_j) P(zk∣dj) 和 P ( w i ∣ z k ) P(w_i\mid z_k) P(wi∣zk) 求偏导数,井令其等于 0,得到下面的方程组
 解方程组得到 M M M 步的参数估计公式:
解方程组得到 M M M 步的参数估计公式:


共现模型
基本思想
- 共现模型将话题看作隐变量 z z z,文本和单词对看作观测变量 ( w , d ) (w,d) (w,d);整个模型表示话题生成文本,话题生成单词,从而得到单词-文本共现数据的过程
共现模型的定义
- 共现模型中,文本-单词共现数据 T T T 的生成概率为所有单词-文本对的生成概率的乘积,其中每个单词-文本对 ( w , d ) (w,d) (w,d) 的生成概率由以下公式决定 (在生成模型中, w w w 与 d d d 是条件独立的):
P ( w , d ) = ∑ z ∈ Z P ( z ) P ( w , d ∣ z ) = ∑ z ∈ Z P ( z ) P ( w ∣ z ) P ( d ∣ z ) \begin{aligned} P(w, d) &=\sum_{z\in\mathcal Z}P(z)P(w,d\mid z) \\&=\sum_{z\in\mathcal Z}P(z)P(w\mid z)P(d\mid z) \end{aligned} P(w,d)=z∈Z∑P(z)P(w,d∣z)=z∈Z∑P(z)P(w∣z)P(d∣z) - 共现模型也可以表示为三个矩阵乘积的形式。这样,概率潜在语义分析与潜在语义分析的对应关系可以从中看得很清楚。下面是共现模型的矩阵乘积形式:
 概率潜在语义分析模型中的矩阵 U ′ U' U′ 和 V ′ V' V′ 是非负的、规范化的,表示条件概率分布,而潜在语义分析模型中的矩阵 U U U 和 V V V 是正交的,未必非负,并不表示概率分布
概率潜在语义分析模型中的矩阵 U ′ U' U′ 和 V ′ V' V′ 是非负的、规范化的,表示条件概率分布,而潜在语义分析模型中的矩阵 U U U 和 V V V 是正交的,未必非负,并不表示概率分布
概率有向图模型
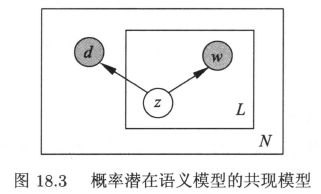
共现模型的学习算法推导类似于生成模型,这里略去
共现模型与生成模型
- 虽然生成模型与共现模型在概率公式意义上是等价的,但是拥有不同的性质。生成模型刻画文本-单词共现数据生成的过程,共现模型描述文本-单词共现数据拥有的模式
- 生成模型式 P ( w , d ) = P ( d ) ∑ z P ( w ∣ z ) P ( z ∣ d ) \begin{aligned} P(w, d) &=P(d) \sum_{z} P(w \mid z)P(z \mid d) \end{aligned} P(w,d)=P(d)z∑P(w∣z)P(z∣d) 中单词变量 w w w 与文本变量 d d d 是非对称的,而共现模型式 P ( w , d ) = ∑ z ∈ Z P ( z ) P ( w ∣ z ) P ( d ∣ z ) \begin{aligned} P(w, d) &=\sum_{z\in\mathcal Z}P(z)P(w\mid z)P(d\mid z) \end{aligned} P(w,d)=z∈Z∑P(z)P(w∣z)P(d∣z)中单词变量 w w w 与文本变量 d d d 是对称的。所以前者也称为非对称模型,后者也称为对称模型
Ref
- 《统计学习方法》
- 非负矩阵分解 (1):准则函数及 KL 散度