IoT带屏设备的图文内联混排富文本方案探索

图文混排在带屏UI场景里,尤其是一些偏运营的动态UI场景里,是非常常用的一个功能,拟在通过图文混排向用户展示更加丰富、更加具体、更加有吸引力的UI界面。在Web技术领域,浏览器是天然支持图文内联混排能力的,而在一些中低端的IoT带屏设备上,浏览器是一个非常奢侈的技术,很难在中低端设备上运行完整的浏览器程序。所以在这里想要研究下在已有GUI或者图形系统的IoT带屏设备上,实现一个图文内联混排的富文本(小型HTML引擎)的技术方案的探讨。

1、Web上的图文内联
首先看下,图文内联在Web浏览器上的一个效果和写法,先看效果:

看以上效果,行内有图片,以及多种样式文字的布局效果,而这样的复杂布局的UI效果在浏览器中可以用HTML文档非常简单的搭建出来:
 酸辣无骨鸡爪柠檬脱骨去骨泡椒凤爪小零食推荐即熟食网红小吃批发
【每盒仅7元】【领券立减10元】
点击购买
酸辣无骨鸡爪柠檬脱骨去骨泡椒凤爪小零食推荐即熟食网红小吃批发
【每盒仅7元】【领券立减10元】
点击购买
价格
¥99.00
国庆狂欢价
¥17.00-62.88

2、HTML与XHTML
HTML的全称为超文本标记语言,是一种标记语言,是英文HyperText Markup Language的简称。它包括一系列标签.通过这些标签可以将网络上的文档格式统一,使分散的Internet资源连接为一个逻辑整体。它是一种松散约束的规范。
XHTML的全称是可扩展超文本标记语言,英文全称Extensible HyperText Markup Language。表现方式与超文本标记语言(HTML)类似,不过语法上更加严格。从继承关系上讲,XHTML则基于可扩展标记语言(XML)。XHTML是一种增强了的HTML,XHTML 是更严谨更纯净的 HTML 版本。它的可扩展性和灵活性将适应未来网络应用更多的需求。
从HTML到XHTML过渡的变化比较小,主要是为了适应XML。最大的变化在于文档必须是良构的,所有标签必须闭合,也就是说开始标签要有相应的结束标签。另外,XHTML中所有的标签必须小写。而按照HTML 2.0以来的传统,很多人都是将标签大写,这点两者的差异显著。在XHTML中,所有的参数值,包括数字,必须用双引号括起来(而在SGML和HTML中,引号不是必须的,当内容只是数字、字母及其它允许的特殊字符时,可以不用引号)。所有元素,包括空元素,比如img、br等,也都必须闭合,实现的方式是在开始标签末尾加入斜扛,比如 、
。省略参数,比如。两者的详细差别,可通过W3C XHTML说明来查阅。
HTML的松散约束,意味着程序需要更加复杂的功能和算法去兼容各种不严格的写法,也意味着更多的资源损耗。而采用基于XML的严格约束的XHTML,会使得程序更简单,专注在处理文档的核心功能上。所以,这里我们主要基于XML格式的文档来探讨IoT场景的富文本引擎。
3、富文本引擎
本文目标只为探讨富文本引擎本身的核心能力,不展开GUI和图形引擎,所以这里的基本前提是,系统已经具备了有一个较强能力的GUI或者图形引擎,如QT或者Skia等。
首先,对于Web领域而言,有三大最基础的核心能力,HTML、CSS以及JS,在这里,不考虑JS动态脚本能力,专注在HTML(倾向于XML)、以及CSS,并且CSS也只考虑内联样式(直接在标签内部引入),不考虑页级CSS和外联CSS。
就像上面那段国庆季的HTML文档,就是这类遵循XML,并且只有内联样式表以及Inline布局的一个文档结构,这里就是要探索将这样一个文档通过一个小型的HTML引擎解析并且排版出来。
3.1、HTML解析
构建富文本引擎的首要步骤,就是需要解析HTML文档,生成特定的数据结构,在这里称之为dom树。一个HTML文档,可以对应一个树状结构的节点树,所以首先要定义一个dom节点的数据结构,可以类似以下结构来设计:
class HtmlNode
{
protected:
// 节点类型,span、text、br等
std::string type;
// 样式表
std::map< std::string, std::string > styles;
// 属性表
std::map< std::string, std::string > attrs;
// 普通样式(margin、background-color等)
NormalStyle normalStyle;
// 可继承样式(font-size、color等)
InheritedStyle inheritedStyle;
// 父节点
HtmlNode* parent;
// 子节点
std::vector children;
} 可以通过以上的数据结构来存储HTML文档解析出来的dom节点树,并派生出SpanNode、ImageNode、BRNode以及Document类(通过span、image和br就可以排出丰富的富文本效果了,其中span为inline布局,image为inline-block布局),来处理不同节点类型的功能逻辑。
另外,上面以及说过可以采用XHTML来约束HTML的松散规范,而XHTML是基于XML格式的标记语言,所以可以使用一些开源的XML解析库,直接帮助我们来解析HTML文档,如tinyxml或者expat等,可以选择最适合自己应用场景的。
最终,HTML文档会被解析成类似以下的节点树:
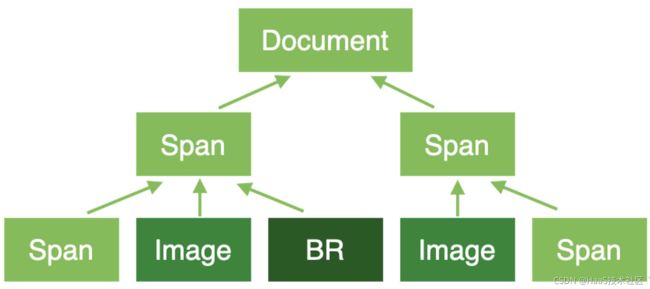
3.2、样式处理
HTML解析完成之后,还需要对节点样式进行解析处理。在浏览器里,样式表有多重形态,包括1、内联样式,定义在节点的style属性上的样式信息;2、页级样式,定义在HTML的head中的样式;3、外联样式,通过link方式引入的外部CSS文件。
这里先只考虑内联样式,也就是定义在节点的style属性里的值。在解析dom树的同时,可以同步将style属性解析为字典类型的样式表保存起来,解析规则也比较简单,就是按照分号分割样式,再通过冒号分离key-value。
另外,在CSS样式中,有部分样式是支持继承的,也就是子节点会自动继承父节点的部分样式信息,除非子节点自己定义了该样式。所以在HtmlNode类里面,声明了两种样式表,NormalStyle和InheritedStyle:
// 暂时支持解析以下样式
struct NormalStyle
{
uint32_t bgColor; // background-color 背景色
float marginLeft; // margin-left
float marginTop; // margin-top
float marginRight; // margin-right
float marginBottom; // margin-bottom
float width; // width 宽度(img节点inline-block使用)
float height; // height 高度(img节点inline-block使用)
}
struct InheritedStyle
{
uint32_t color; // color 颜色
std::string fontFamily; // font-family 字体
float fontSize; // font-size 字号
bool italic; // font-style 斜体
bool bold; // font-weight 先只支持加粗和普通字重
int32_t lineHeight; // line-height 行高
int32_t textDecoration; // text-decoration 1:underline, 2:line-through, 0:none
}对于普通样式,处理逻辑比较简单,也就是遍历所有节点,然后解析自己的样式信息即可;而对于可继承的样式,需要先从根节点开始解析样式,然后子节点先复制父节点的InheritedStyle,再解析自己的样式:
void HtmlNode::parse()
{
// 1、初始化可继承样式表
if (parent != NULL) {
inheritedStyle = parent->inheritedStyle;
} else {
// 根组件设置默认样式
memset(&inheritedStyle, 0, sizeof(InheritedStyle));
inheritedStyle.color = 0xFF000000;
inheritedStyle.fontSize = 24;
}
// 2、解析样式
parseStyle();
// 3、解析子组件样式
if (!children.empty()) {
for (std::vector< HtmlNode* >::iterator it = children.begin(); it != children.end(); it++) {
(*it)->parse();
}
}
}这样经过HTML解析以及样式处理之后,带有样式信息的dom树就已经搭建起来了,接下来就需要为该dom树进行布局计算了。
3.3、Inline布局
布局计算的目的就是将上述的dom节点树,进行一系列的测量和布局,确定每个元素所处的位置以及所占大小,在Web浏览器里,主要的排版模式是按行来布局,所以可以布局出行内图文混排的UI效果,所以这里也考虑使用行布局来设计。
首先先简单看一下,在浏览器里面,节点元素是分为几种类型的,inline元素、inline-block元素以及block元素,这几种类型的主要差别为:
inline
- 使元素变成行内元素,拥有行内元素的特性,即可以与其他行内元素共享一行,不会独占一行.
- 不能更改元素的height,width的值,大小由内容撑开.
- 可以使用padding,margin的left和right产生边距效果,但是top和bottom就不行.
block
- 使元素变成块级元素,独占一行,在不设置自己的宽度的情况下,块级元素会默认填满父级元素的宽度.
- 能够改变元素的height,width的值.
- 可以设置padding,margin的各个属性值,top,left,bottom,right都能够产生边距效果.
inline-block
- 结合了inline与block的一些特点,结合了上述inline的第1个特点和block的第2,3个特点.
- 用通俗的话讲,就是不独占一行的块级元素。
常用的inline元素有:span, i, b, label, a等;
常用的block元素有:div,ul,li,dl,p,h等;
inline-block元素有img。
目前,暂时只考虑span、img等几个标签,所以只需要考虑inline布局和inline-block布局。
最终布局计算的目标如下图所示:
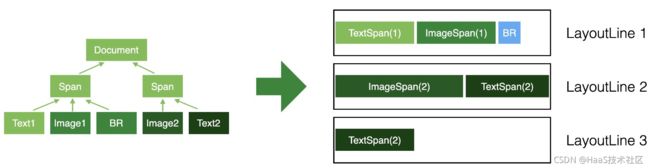
将左边的dom节点树,经过布局计算,最终生成右边的多行的结果。它的基本算法逻辑可以概括为:1、开始布局,创建新行;2、遍历节点树,添加布局元素到当前行;3、当前行满了,添加新行,重复步骤2和3。
当然,其中的文本测量布局计算需要对接到基础GUI系统或者图形系统中。
LayoutContext::LayoutStep HtmlNode::layout(LayoutContext *context)
{
LayoutLine* line = NULL;
if (isBlock()) {
// 如果为block元素,先添加新行,再在新行进行布局计算
line = context->appendNewLine();
} else {
// 非block元素,在当前行进行布局计算
line = context->currentLine();
}
if (line == NULL) {
// 布局结束
return LayoutContext::STOP;
}
// 进行真正的布局计算,不同类型的节点可继承后处理自己的布局计算逻辑
LayoutContext::LayoutStep step = onLayout(context, line);
if (step == LayoutContext::STOP) {
return step;
}
// 布局子节点
for (std::vector< HtmlNode* >::iterator it = children.begin(); it != children.end(); it++) {
HtmlNode* child = *it;
if (child->layout(context) == LayoutContext::STOP) {
return LayoutContext::STOP;
}
}
return LayoutContext::CONTINUE;
}
// img元素布局逻辑
LayoutContext::LayoutStep ImageNode::onLayout(LayoutContext *context, LayoutLine *line)
{
if (width > 0 || height > 0) {
float remainWidth = line->remainWidth();
float maxWidth = context->getMaxWidth();
if (width <= remainWidth) {
// 当前行还有空余大小,直接添加到当前行
ImageItem* item = new ImageItem(image, width, height);
line->appendItem(item);
} else {
// 当前行空余大小不够,创建新行再进行布局
line = context->appendNewLine();
if (line == NULL) {
return LayoutContext::STOP;
}
ImageItem* item = new ImageItem(image, width, height);
line->appendItem(item);
}
}
return LayoutContext::CONTINUE;
}
// span文本元素布局逻辑,伪代码如下
LayoutContext::LayoutStep SpanNode::onLayout(LayoutContext *context, LayoutLine *line)
{
// 通过样式设置文本测量环境(需要对接到基础GUI或者图形系统上)
int32_t index = 0;
while (index < 文本长度) {
int32_t measuredCount = 0;
float measuredWidth = 0.f;
float remainWidth = line->remainWidth();
调用文本测量&断行
if (remainWidth >= measuredWidth) {
1、添加TextSpan到当前line
2、index += measuredCount;
3、remainWidth -= measuredWidth;
} else {
// 添加新行
line = context->appendNewLine();
1、添加TextSpan到当前line
2、index += measuredCount;
3、remainWidth -= measuredWidth;
}
}
return LayoutContext::CONTINUE;
}经过以上布局计算,就可以得到布局后的行元素,再对接到GUI或图形系统的绘制体系中,就可以得到富文本的UI显示效果了,因为这里没有涉及具体的GUI或者图形系统,所以暂时不展开说了。
3.4、效果示例

结语
本文主要内容是在IoT带屏场景中,探讨一个轻量的、小型的HTML引擎的设计思路,仅涉及一些基本的、偏静态HTML的展示,在很多资源受限的IoT设备上,如果有显示富文本形态的UI场景需求,因为大型的浏览器并不适合运行在这类设备上,一个轻量的小型引擎就会非常重要了。
这里富文本引擎通过HTML解析、CSS样式处理、以及最重要的轻量Inline布局功能来支撑图文混排的排版能力。另外如果需要支持div等block布局的功能,还需要再增强一下该layout功能。
通过本文分享这边的设计思路,希望对大家有所帮助。
开发者支持
如需更多技术支持,可加入钉钉开发者群,或者关注微信公众号。
更多技术与解决方案介绍,请访问HaaS官方网站https://haas.iot.aliyun.com。