造福C站全体用户,文章漫游者v0.2开放下载
大家好,我是小小明。
近段时间原力计划群,有很多博主都提出了希望备份博客到本地。热心的我第二天立马开发了一个nodejs的富文本转Markdown的服务。对于第一位提这个问题群友,我测试了对他的博客进行批量爬取并转换为Markdown,经测试对于他的1198篇文章仅耗时13分钟:
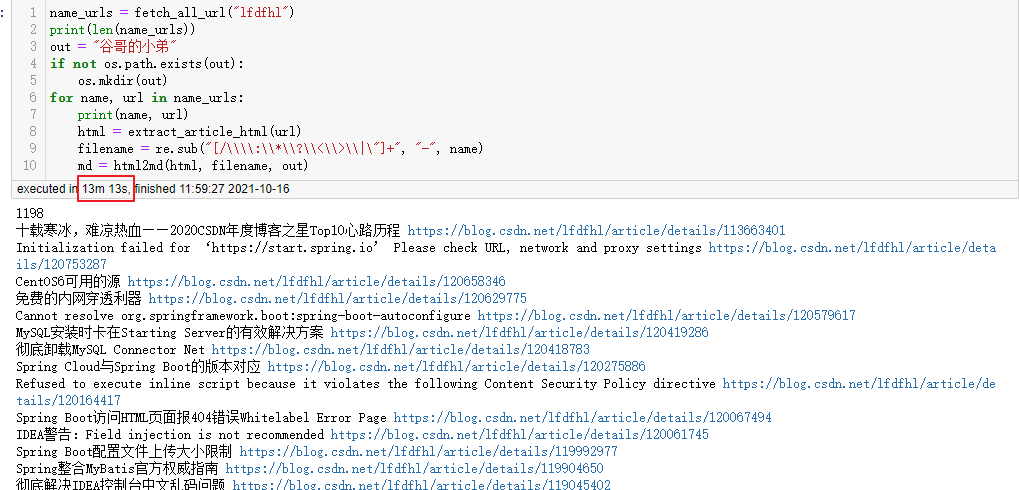
不过考虑到有一些人将别人的博客爬了之后转成PDF上传到csdn的付费文档,这种恶心人的做法,所以这个批量爬别人的文章并转换的代码,我就不公布了。
但是没关系,相信有导出文章需求的人都是需要导出自己的文章,这几天我开发了一个更牛逼的批量下载自己的文章的神器:
- Markdown和富文本均可导出
- 支持对接富文本批量转Markdown服务
- 支持私密文章导出
- 支持按发布年月分组导出
- 支持仅导出搜索结果
- 分组导出包含明细统计
有童鞋提出希望支持按专栏目录分组导出,不过一开始考虑专栏不唯一,所以一开始没做,如果本文足够火的话。嘿嘿,下个版本我就增加分专栏导出的功能。
当然它强大的功能不仅仅是导出,还支持:
- 阅读指定用户的文章
- 对缓存文章列表快速搜索
- 导出文章链接列表
- 快速复制标题和链接
下面是使用教程,好好感受一下吧。
打开后界面如下:

下载地址:
CSDN文章漫游者v0.2:
https://dataking.feishu.cn/docs/doccnf28VzLSopV4zRqS9FGgVie
仅支持windows平台,对于Mac平台推荐开启win7虚拟机。
阅读文章
打开后,输入你想读取的用户的ID,即可查看他的公开文章,例如我们看看总榜第一文章。
在https://blog.csdn.net/rank/list/total即可找到总榜排名,点进涛歌的主页看看:
主页链接是https://blog.csdn.net/stpeace,说明该用户的ID是stpeace。
对于使用了自定义域名的用户,可以查看他任意一篇文章后查看源码,找到开头的link. canonical,例如:
<link rel="canonical" href="https://blog.csdn.net/as604049322/article/details/120855124"/>
即可得到原始链接,从而分析出用户ID为as604049322。
下面我们看看涛歌的文章:
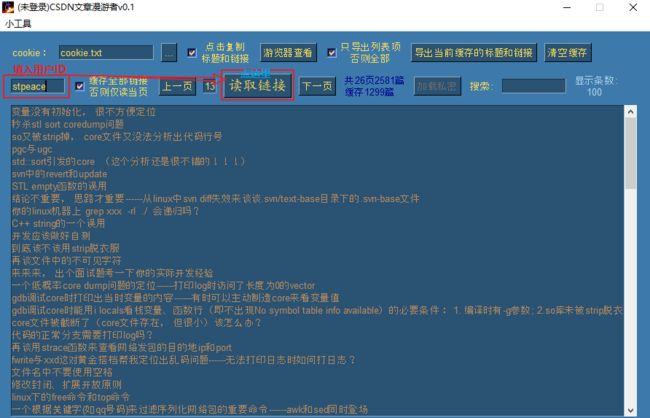
等待10秒左右,已经将2580个链接加载完毕:
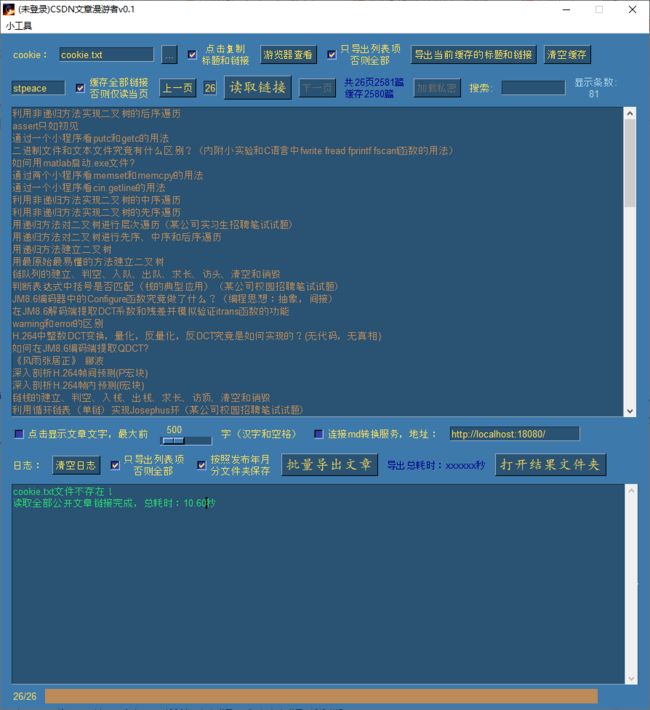
为什么涛歌有2581篇文章却只缓存2580篇呢,这是因为他有两篇文章标题文字完全一致的文章导致了覆盖。
此时涛歌的去重后的全部文章链接已被缓存,我们可以翻上下页进行查看:
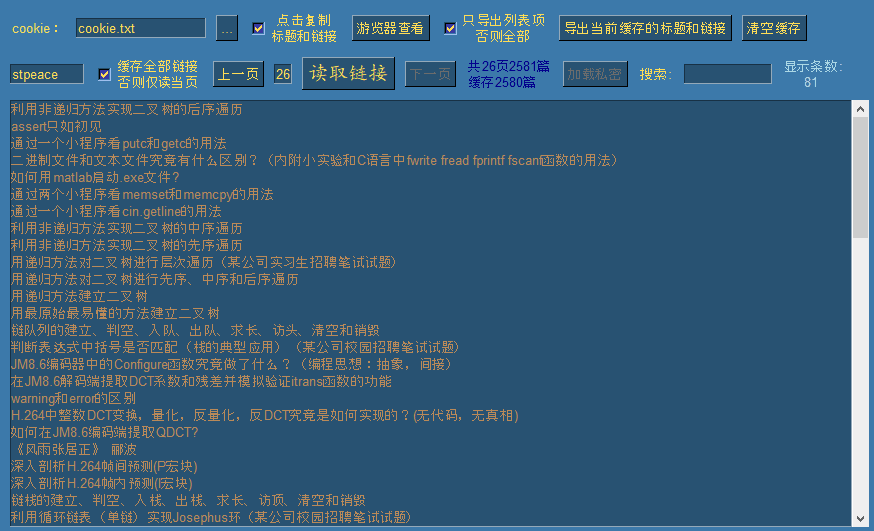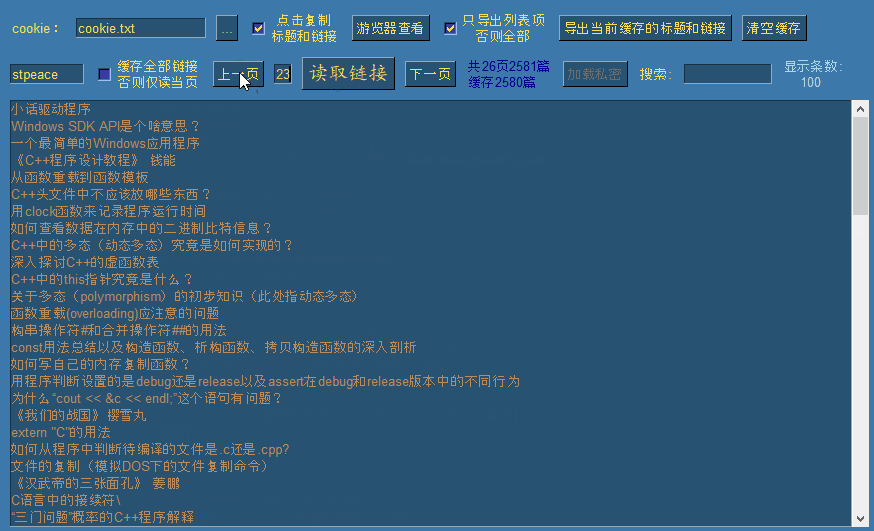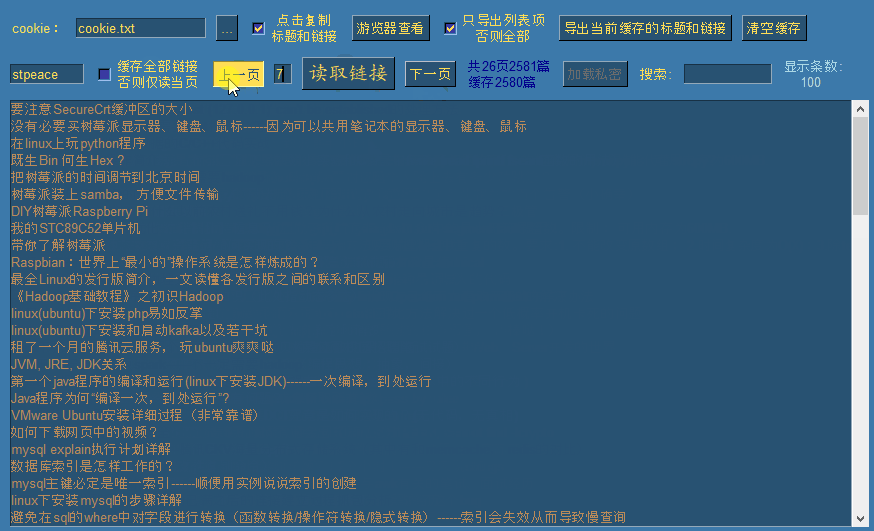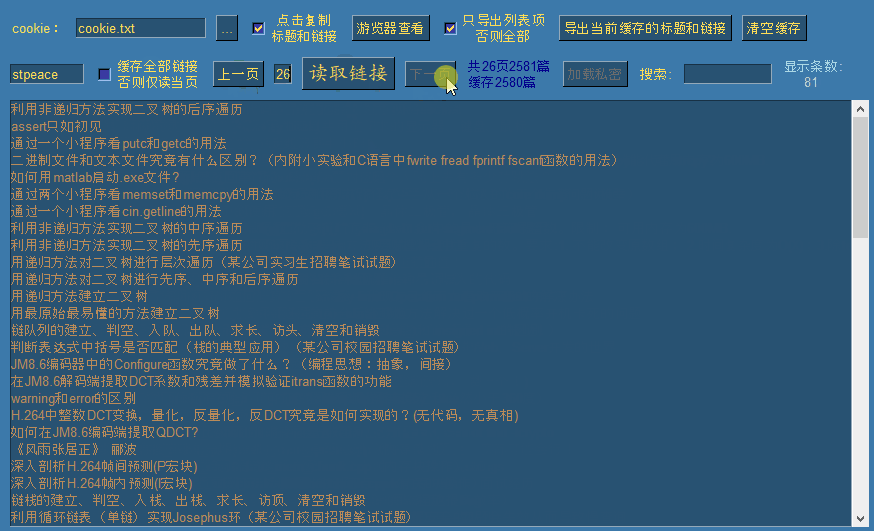
默认情况下勾选了缓存全部链接选项,此时点击读取链接时,会一次性逐页读取全部公开链接,并自动移动到最后一页。如果需要读取指定页,需要先取消勾选,然后输入需要读取的页面后,点击读取链接即可读取指定页。(每页100条链接)
未登录状态下,不输入用户ID,直接读取链接将读取作者的文章链接。登录后,不输入用户ID,则读取登录用户的文章链接。输入ID的情况下,都以输入的ID为准。
快速复制文章标题和链接
默认情况下,启动了 点击复制标题和链接 的选项,此时点击需要复制的标题时:

点击后测试粘贴到下面:
大学生读者让我帮找二分查找的bug
https://blog.csdn.net/stpeace/article/details/120257969
可以看到复制成功,这样我们可以很方便的快速分享需要分享的文章到微信。
同时点击时,控制台会显示当前这篇的文章的用户数据和互动数据以及发布时间。
快速阅读目标文章
勾选 点击显示文章文字 选项后,再次点击目标文章,即可快速阅读文章,右边的滑动条可以调整显示的文字字数:
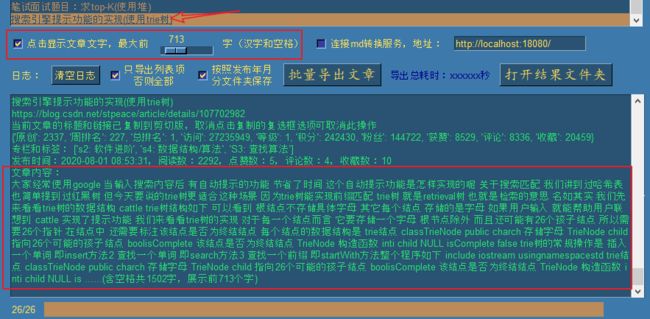
当然,这只是相当于粗略的概要阅读,如果我们对这篇文章感兴趣,想要细度的时候,此时可以点击最上面的游览器查看按钮:

此时已顺利的使用本地的默认游览器打开该网页:
快速搜索功能
例如我们想看下涛哥有多少篇标题带Java的文章,只需在输入框输入要搜索的关键字即可(即时回显):

可以看到涛歌共10篇标题带Java的文章。
注意:只对已缓存的标题进行搜索。
链接导出功能
直接点击 导出当前缓存的标题和链接 ,默认导出当前列表中显示的文章,因为默认勾选了只导出当前正在显示的列表项:
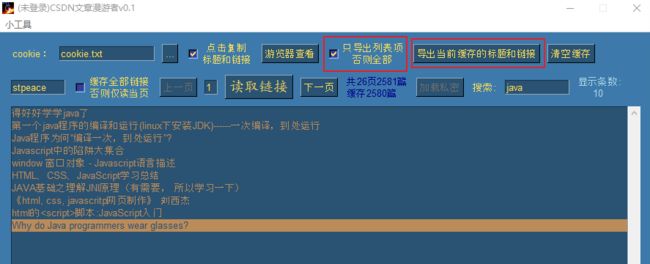
支持txt,csv和tsv三种导出格式:
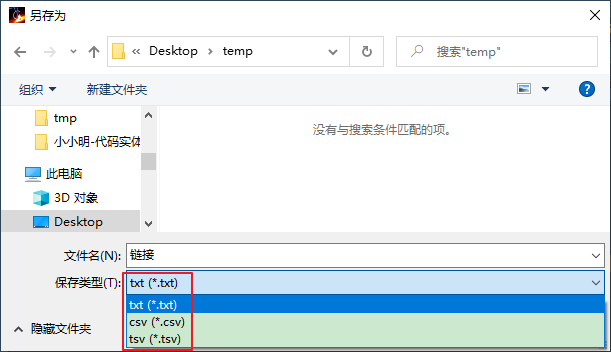
TXT导出效果:
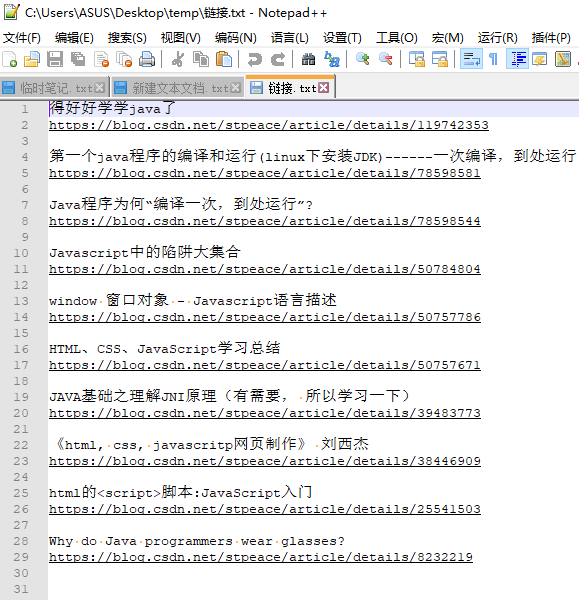
Csv的导出效果:
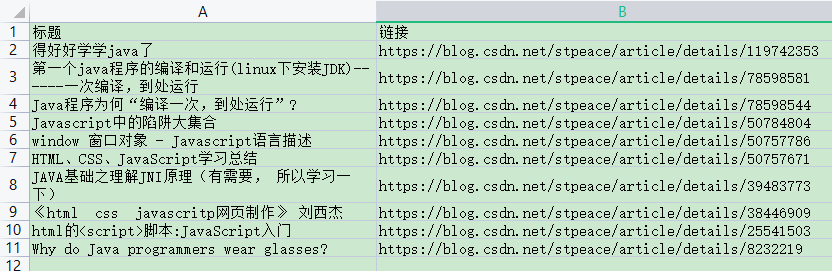
很多朋友都希望一次性获取自己所有文章的链接,那么使用本软件只需要取消对 只导出当前正在显示的列表项 的勾选(可导出全部缓存),然后点击 导出链接 ,格式选择csv,使用wps(结果文件保存为utf-8,office可能乱码)打开后,复制第二列即可。
登录CSDN并加载私密文章
需要将游览器登录的cookie保存到本地。
游览器按下F12打开开发者工具,点开自己主页的请求即可复制cookie字符串:
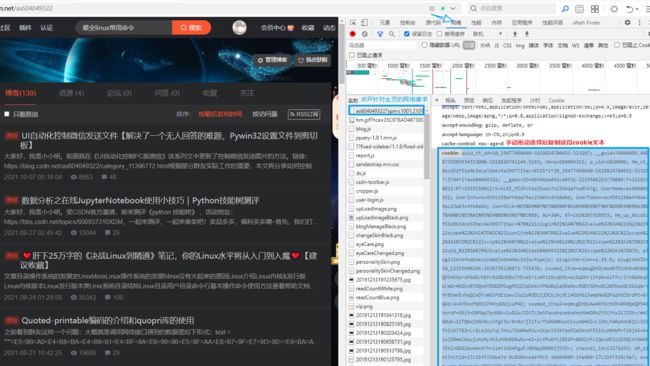
注意:必须是选中这段文本复制才有效。右键菜单复制值,复制的文本与这段不一致。
复制后保存到文件中,可命名为cookie.txt,保存的编码必须为UTF-8:
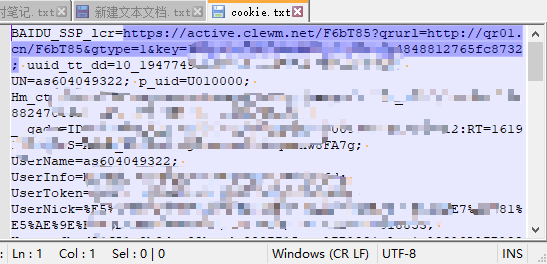
本软件本身也提供了从剪切板的cURL(Bash)命令字符串中解析出cookie进行操作。
首先复制请求对应的cURL(Bash)命令,注意必须是bash版本,不要复制cmd版本:

然后点击菜单栏的小工具:

输入保存的文件名之后便在程序当前目录下保存了cookie文件。
保存后,点击一下检查cookie之后,标题栏已显示当前登录的用户:

此时直接点击读取链接,就是读取自己的文章了:
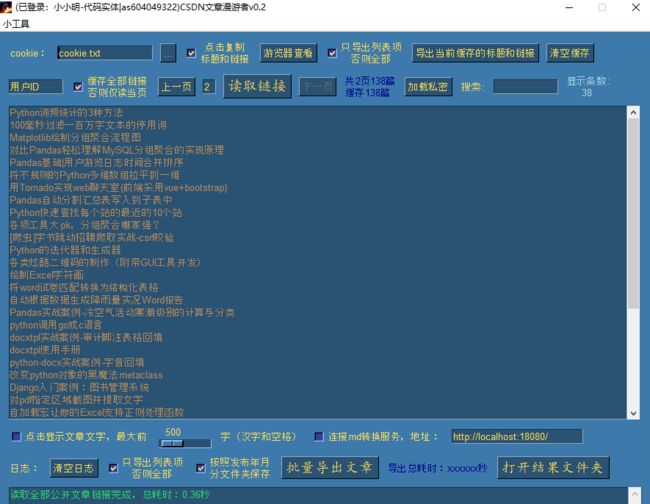
读取链接后,登录状态已激活,加载私密按钮可以使用,点击加载私密读取自己的私密文章:
私密文章也存在于缓存中,可以被搜索。
批量导出自己的文章
首先我们取消下面两个选项的勾选后,再点击批量导出文章(前面已经点击读取链接缓存自己的全部文章链接):

点击 批量导出文章 按钮:
点击 打开结果文件夹 按钮,可查看导出结果:
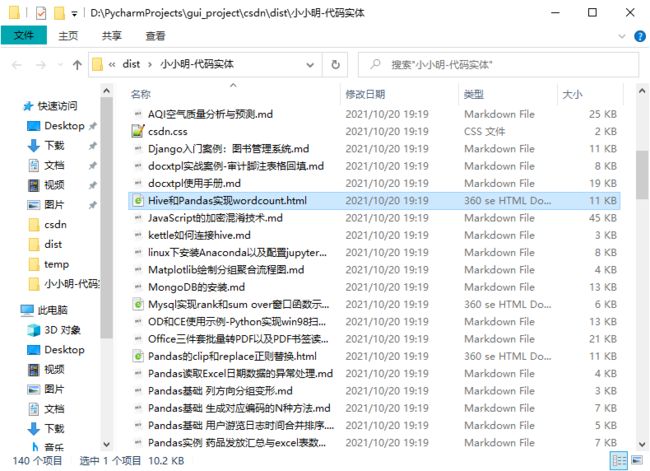
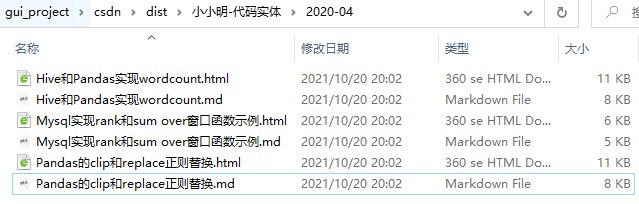
原本使用Markdown编辑器编辑的则导出Markdown,使用富文本编辑器编辑的文章则导出HTML,私密文章只要加载后也会被导出。
后面我将再介绍启动md转换服务,可以将富文本编辑器编辑的文章转换为Markdown。
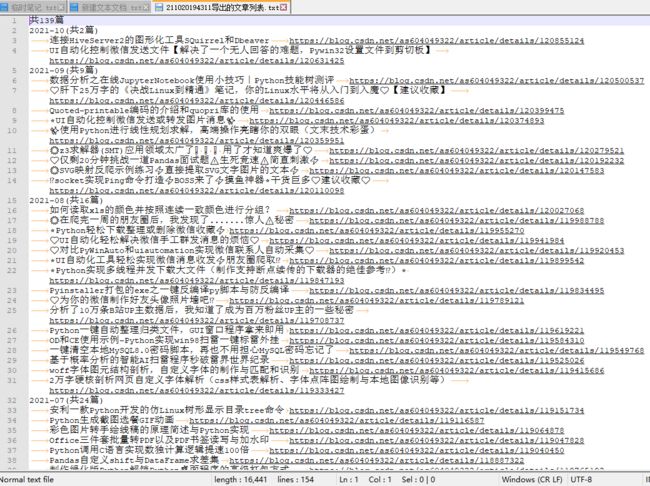
下面我删除上面导出的文件夹之后,再演示按发布年月分组导出,勾选该选项点批量导出:
打开该选项之后导出速度相对会慢一些,因为每次都多了一次网络访问,需要解析发布日期数据,导出结果形式:
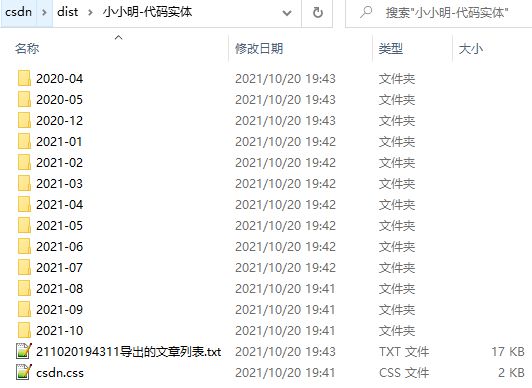
同时通过一个文本文件列出了导出详情:
md转换服务
首先需要安装nodejs,这个可以自行百度一下。
然后在上面的飞书文档中下载下面的服务源码:

解压后,在解压的目录下执行:
node html2md.js

此时,我们的程序中就可以启动链接md转换服务了:

此时再点击批量导出,耗时与没有启动该服务时差不多。

之前富文本编辑的文章都已转换为Markdown:
有新的需求或想法,欢迎留言评论噢!!!