一致性哈希算法详解
前言
最近学习一致性哈希算法时,在网络上看到一位大神的文章 一致性哈希(hash)算法 惊为天人,故在前人的基础上完成本篇文章。
1 问题导入
相信大家日常的开发都离不开 Redis 以及数据库吧,为了提高 Redis 的性能,我们要么实行主从复制,要么搭建集群,读写分离;为了提高数据库的性能,在数据量到达一定程度之后,我们对其进行分库分表操作。
在分布式系统中,由于我们部署的是集群,那么,我们应该采取怎样的规则来将请求路由到服务器上呢?如果规则是随机的,数据可能存储在任何一组服务器上,我们查询时不知道数据到底存储在集群的哪一个服务器,这就需要遍历所有服务器才能得到结果,这对于服务器的性能是一个巨大的伤害。因此,随机规则是说不过去的,既然如此,我们可以采取一些能够准确定位的规则,比如,哈希。
2 使用哈希
使用哈希的方式如下,其中 N 为服务器台数:
hash(资源) % N
资源通过哈希的方式被分到特定的服务器,由于资源的名称一般不可能重复,我们对其进行哈希时,得到的结果不变,故其存放的位置亦不变。下面我们通过一个示例来帮助大家更好明白哈希的规则:
假设我们拥有4台缓存服务器,存放的数据是书籍。对书籍的名称取哈希并取余,得到的结果必为0,1,2,3,如得到的结果为0,我们将其存放在0号服务器上,其他的以此类推即可。这样,我们可以将所有数据准确存储到不同缓存服务器上,在访问时,我们也可以通过同样的操作判断数据位于哪一台缓存服务器上,我们的需求得到了最基本的满足 – 可以准确定位存放资源的服务器,而不是遍历所有服务器。
3 使用哈希带来的问题
上面哈希的做法看起来美滋滋啊,直接解决了性能的问题,以前查询需要遍历所有服务器的,现在只需要查询其中一台就行了,真开心啊!但是,哈希的算法是否是完美的呢?我看未必吧,由于该算法需要对服务器个数进行取余,那么,如果服务器的数量变动,那么所有数据的存储位置都要发生变动!
好的,现在3台缓存服务器已经不能满足我们的需求,领导决定增加一台缓存服务器,那么如果我们使用之前的哈希算法查询数据,指向的缓存服务器大概率与原来不同,因为我们的 N 发生了改变,被除数相同,除数不同,余数大概率不同。换句话说,就是在我们增加一台缓存服务器之后,所有数据的存储位置都要改变。在一段时间内,所有缓存的访问失效,造成了缓存的雪崩。访问直接到达后端服务器查询数据库,令其承受极大的压力,可能导致整个系统崩溃。同理,如果某台服务器发生故障而导致服务器数量减少,其结果与增加服务器大致相同。
总结一下,当缓存服务器数量改变,大部分缓存位置均需要发生变化,容易引起缓存雪崩,系统亦可能随之崩溃,这个问题我们应该如何解决呢?好的,一致性哈希算法该出场了。
4 一致性哈希算法标准
一致性哈希提出了在动态变化的缓存环境中,哈希算法应该满足的4个适应条件:
- 平衡性(Balance):平衡性也就是说负载均衡,是指客户端 hash 后的请求应该能够分散到不同的服务器上去。一致性 hash 可以做到每个服务器都进行处理请求,但是不能保证每个服务器处理的请求的数量大致相同。
- 单调性(Monotonicity):单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应该能够保证已分配的内容可以被映射到新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。比如,之前有三台服务器A、B、C,某个 key 被映射到B当中,当新增服务器D后,这个 key 要么被映射到之前的B中,要么被映射到新增的D中,而不应该映射到A或者C当中。简单的哈希算法往往不能满足单调性的要求,如最简单的线性哈希:x → ax + b mod P。在上式中,P表示全部缓冲的大小。不难看出,当缓冲大小发生变化时(从P1到P2),原来所有的哈希结果均会发生变化,从而不满足单调性的要求。哈希结果的变化意味着当缓冲空间发生变化时,所有的映射关系需要在系统内全部更新。
- 分散性(Spread):分布式环境中,客户端请求时候可能不知道所有服务器的存在,可能只知道其中一部分服务器,在客户端看来他看到的部分服务器会形成一个完整的 hash 环。如果多个客户端都把部分服务器作为一个完整 hash 环,那么可能会导致,同一个用户的请求被路由到不同的服务器进行处理。这种情况显然是应该避免的,因为它不能保证同一个用户的请求落到同一个服务器。所谓分散性是指上述情况发生的严重程度。
- 负载(Load):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
5 初识一致性哈希算法
一致性哈希算法也需要执行取模运算,与上文提到的哈希算法对服务器数取模不同,这个所谓的一致性哈希算法更高大上一点,它直接对2^32取模。
我们该怎样理解一致性哈希算法呢?这么说吧,我们可以把哈希值空间想象成一个圆环,其范围为0-2^32-1,则该哈希环如下:(以下图片均来自网络,非原创)

那服务器如何映射到哈希环上呢?我们知道,服务器必定有自己的 IP 地址或主机名,使用 IP 地址或主机名作为关键字进行哈希运算,结果再对2^32取模,运算公式如下:
hash(服务器的IP地址) % 2^32
得到的结果必然是一个0到2^32-1之间的一个整数,这个整数就代表了这台服务器,根据我们之前对哈希环的定义,在哈希环上必然存在这个整数,又因为整数代表着服务器,故服务器实际上可以映射到哈希环上。依次类推,集群上的每一台服务器在哈希环上都有着属于自己的位置。
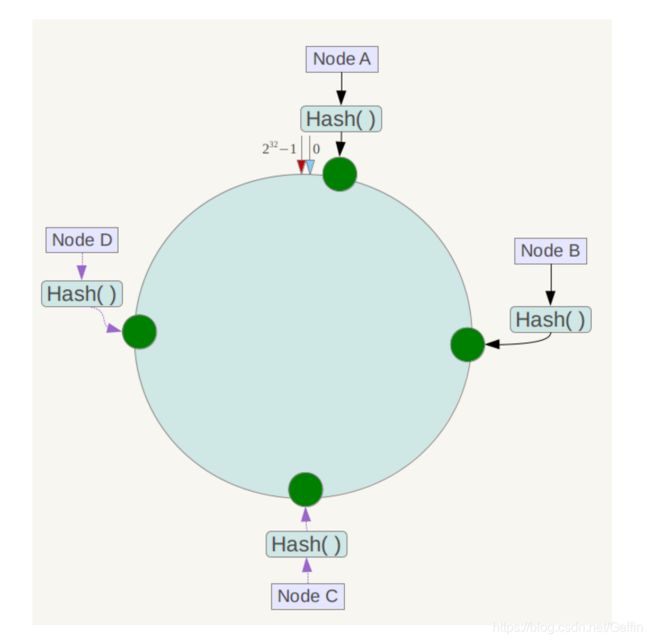
然后在我们查询数据时,采用如下算法定位数据存放的服务器:对数据的 key 使用相同的哈希函数,得到一个结果,根据结果在哈希环上的位置,然后沿该位置顺时针转动,遇上的第一台服务器就是需要定位到的服务器。
我们假设有A,B,C,D四个数据,经过哈希算法后,在哈希环上的位置如下:
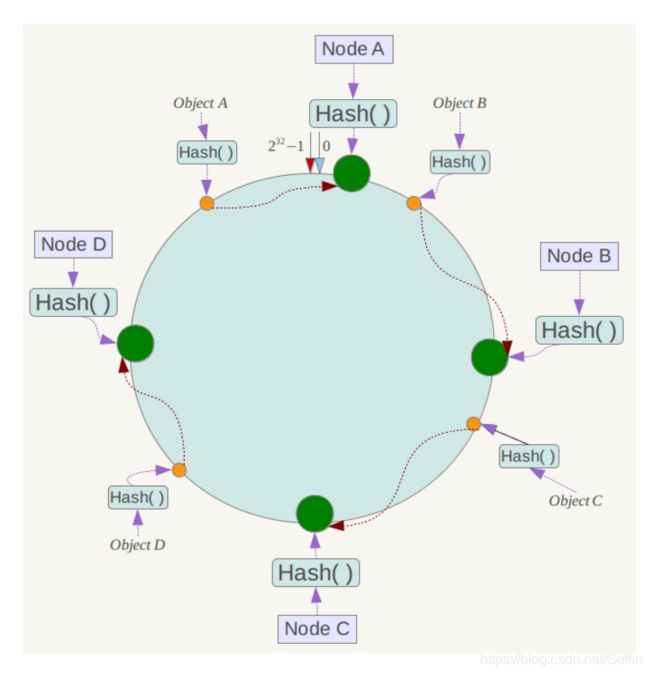
根据我们的一致性哈希算法,Object A 将会被定位到 Node A 上,其余的依次类推即可。
6 一致性哈希算法的容错性和可扩展性
若某台服务器出现故障,仅仅会影响到该服务器在哈希环空间的前一台服务器,其余服务器不受影响(数据定位的位置顺时针转动,遇上的第一台服务器是需要定位到的服务器)。
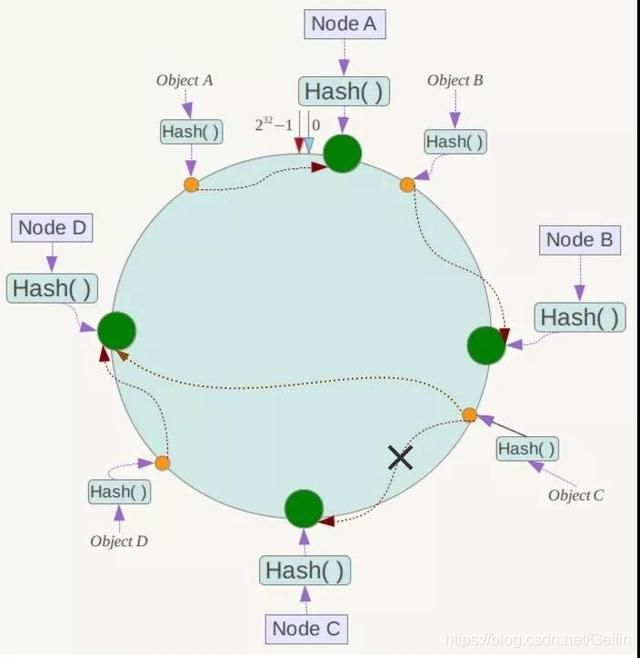
若集群需要增加一台服务器 Node X,我们发现,Object A、B、D 均不受影响,只有 Object C 需要重新定位到 Node X 中,即也仅仅会影响到该服务器在哈希环空间的前一台服务器,其余服务器不受影响(数据定位的位置顺时针转动,遇上的第一台服务器是需要定位到的服务器)。

总结一下,对于一致性哈希算法来说,增减节点都只需要重新定位一小部分数据,可见其具有较好的容错性和可扩展性。
7 一致性哈希算法的倾斜问题
在服务节点太少时,节点分布容易不均匀,从而导致数据倾斜,即数据大部分存储在某一台服务器,例子如下:
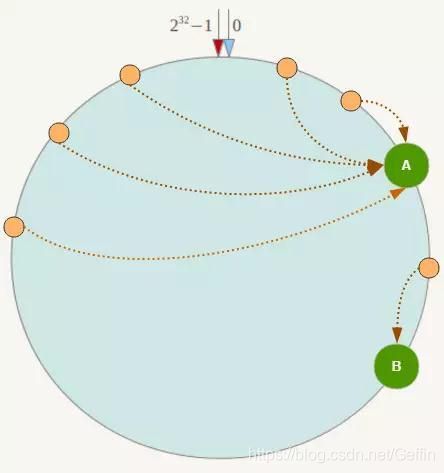
我们思考一下,为什么会出现数据倾斜呢?究其原因,还是服务器的数量太少了,若服务器数量足够多,数据自然会均匀分布到每台服务器上去。既然如此,我们得增加节点的数量,没有真正的物理服务器节点,我们还可以增加虚拟的服务器节点嘛。这些节点又被称为虚拟节点,原理便是对每一个服务节点计算多个哈希,然后在每个计算结果位置放置一个虚拟节点,具体做法可以通过在服务器 IP 地址或主机名后面增加编号来实现。
例如,我们需要对 Node A 计算三个虚拟节点,即可分别计算 Node A#1,Node A#2,Node A#3 的哈希值,进而形成三个虚拟节点。在需要数据定位时,只需要将三个虚拟节点的数据定位到实际节点即可。在实际应用中,我们常常将虚拟节点数设置为32甚至更大,使很少的服务节点也能做到相对均匀的数据分布。
8 总结
一致性哈希算法一般用于分布式缓存,用于处理缓存的数据和多个缓存服务器之间的对应关系。
参考:一致性哈希(hash)算法