【分布式】load balance 02-consistent hash algorithm 一致性哈希算法原理详解
负载均衡系列专题
01-负载均衡基础知识
02-一致性 hash 原理
03-一致性哈希算法 java 实现
04-负载均衡算法 java 实现
概念
一致哈希是一种特殊的哈希算法。
在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对 K/n个关键字重新映射,其中K是关键字的数量, n是槽位数量。
然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
有什么用
现在想来,很多分布式中间件,在增删节点的时候都需要进行 re-balance。
借助一致性 hash,感觉可以避免这一步坑。
业务场景
假设有1000w个数据项,100个存储节点,请设计一种算法合理地将他们存储在这些节点上。
强哈希
考虑到单服务器不能承载,因此使用了分布式架构,最初的算法为 hash() mod n, hash()通常取用户ID,n为节点数。
此方法容易实现且能够满足运营要求。缺点是当单点发生故障时,系统无法自动恢复。同样不也不能进行动态增加节点。
原理图
看一看普通 Hash 算法的原理:

核心计算如下
for item in range(ITEMS):
k = md5(str(item)).digest()
h = unpack_from(">I", k)[0]
# 通过取余的方式进行映射
n = h % NODES
node_stat[n] += 1
输出
Ave: 100000
Max: 100695 (0.69%)
Min: 99073 (0.93%)
从上述结果可以发现,普通的Hash算法均匀地将这些数据项打散到了这些节点上,并且分布最少和最多的存储节点数据项数目小于1%。
之所以分布均匀,主要是依赖Hash算法(实现使用的MD5算法)能够比较随机的分布。
缺点
然而,我们看看存在一个问题,由于该算法使用节点数取余的方法,强依赖node的数目。
因此,当是node数发生变化的时候,item所对应的node发生剧烈变化,而发生变化的成本就是我们需要在node数发生变化的时候,数据需要迁移,这对存储产品来说显然是不能忍的,我们观察一下增加node后,数据项移动的情况:
for item in range(ITEMS):
k = md5(str(item)).digest()
h = unpack_from(">I", k)[0]
# 原映射结果
n = h % NODES
# 现映射结果
n_new = h % NEW_NODES
if n_new != n:
change += 1
输出
Change: 9900989 (99.01%)
翻译一下就是,如果有100个item,当增加一个node,之前99%的数据都需要重新移动。
这显然是不能忍的,普通哈希算法的问题我们已经发现了,如何对其进行改进呢?
没错,我们的一致性哈希算法闪亮登场。
弱哈希
为了解决单点故障,使用 hash() mod (n/m),
这样任意一个用户都有 m 个服务器备选,可由 client 随机选取。
由于不同服务器之间的用户需要彼此交互,所以所有的服务器需要确切的知道用户所在的位置。
因此用户位置被保存到 memcached 中。当一台发生故障,client 可以自动切换到对应 backup,由于切换前另外 1 台没有用户的 session,因此需要 client 自行重新登录。
- 好处
他比强哈希的好处是:解决了单点问题。
- 缺点
但存在以下问题:负载不均衡,尤其是单台发生故障后剩下一台会压力过大;不能动态增删节点;节点发生故障时需要 client 重新登录
一致性 hash 算法
一致性 hash 算法提出了在动态变化的 Cache 环境中,判定哈希算法好坏的四个定义:
平衡性(Balance)
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
单调性(Monotonicity)
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
分散性(Spread)
在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。
当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。
这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
负载(Load)
负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。
与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
普通的哈希算法(也称硬哈希)采用简单取模的方式,将机器进行散列,这在cache环境不变的情况下能取得让人满意的结果,但是当cache环境动态变化时,
这种静态取模的方式显然就不满足单调性的要求(当增加或减少一台机子时,几乎所有的存储内容都要被重新散列到别的缓冲区中)。
代码实现
实现逻辑
一致性哈希算法有多种具体的实现,包括 Chord 算法,KAD 算法等实现,以上的算法的实现都比较复杂。
这里介绍一种网上广为流传的一致性哈希算法的基本实现原理,感兴趣的同学可以根据上面的链接或者去网上查询更详细的资料。
一致性哈希算法的基本实现原理是将机器节点和key值都按照一样的hash算法映射到一个0~2^32的圆环上。
当有一个写入缓存的请求到来时,计算 Key 值 k 对应的哈希值 Hash(k),如果该值正好对应之前某个机器节点的 Hash 值,则直接写入该机器节点,
如果没有对应的机器节点,则顺时针查找下一个节点,进行写入,如果超过 2^32 还没找到对应节点,则从0开始查找(因为是环状结构)。
如图 1 所示:
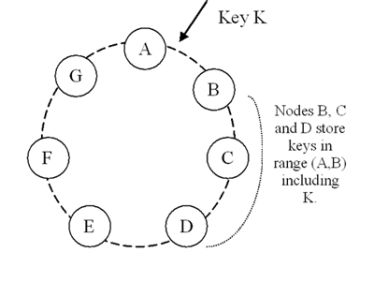
图 1 中 Key K 的哈希值在 A 与 B 之间,于是 K 就由节点B来处理。
另外具体机器映射时,还可以根据处理能力不同,将一个实体节点映射到多个虚拟节点。
经过一致性哈希算法散列之后,当有新的机器加入时,将只影响一台机器的存储情况,
例如新加入的节点H的散列在 B 与 C 之间,则原先由 C 处理的一些数据可能将移至 H 处理,
而其他所有节点的处理情况都将保持不变,因此表现出很好的单调性。
而如果删除一台机器,例如删除 C 节点,此时原来由 C 处理的数据将移至 D 节点,而其它节点的处理情况仍然不变。
而由于在机器节点散列和缓冲内容散列时都采用了同一种散列算法,因此也很好得降低了分散性和负载。
而通过引入虚拟节点的方式,也大大提高了平衡性。
实现代码
consitent-hashing
原理图
[图片上传失败…(image-43a9f8-1592620804879)]
核心代码
for n in range(NODES):
h = _hash(n)
ring.append(h)
ring.sort()
hash2node[h] = n
for item in range(ITEMS):
h = _hash(item)
n = bisect_left(ring, h) % NODES
node_stat[hash2node[ring[n]]] += 1
均匀性
虽然一致性Hash算法解决了节点变化导致的数据迁移问题,但是,我们回过头来再看看数据项分布的均匀性,进行了一致性Hash算法的实现
Ave: 100000
Max: 596413 (496.41%)
Min: 103 (99.90%)
这结果简直是简直了,确实非常结果差,分配的很不均匀。
我们思考一下,一致性哈希算法分布不均匀的原因是什么?
从最初的1000w个数据项经过一般的哈希算法的模拟来看,这些数据项“打散”后,是可以比较均匀分布的。
但是引入一致性哈希算法后,为什么就不均匀呢?
数据项本身的哈希值并未发生变化,变化的是判断数据项哈希应该落到哪个节点的算法变了。

因此,主要是因为这100个节点Hash后,在环上分布不均匀,导致了每个节点实际占据环上的区间大小不一造成的。
改进-虚节点
当我们将node进行哈希后,这些值并没有均匀地落在环上,因此,最终会导致,这些节点所管辖的范围并不均匀,最终导致了数据分布的不均匀。
原理图
[图片上传失败…(image-3fd62c-1592620804879)]
实现代码
for n in range(NODES):
for v in range(VNODES):
h = _hash(str(n) + str(v))
# 构造ring
ring.append(h)
# 记录hash所对应节点
hash2node[h] = n
ring.sort()
for item in range(ITEMS):
h = _hash(str(item))
# 搜索ring上最近的hash
n = bisect_left(ring, h) % (NODES*VNODES)
node_stat[hash2node[ring[n]]] += 1
增加节点
因此,通过增加虚节点的方法,使得每个节点在环上所“管辖”更加均匀。
这样就既保证了在节点变化时,尽可能小的影响数据分布的变化,而同时又保证了数据分布的均匀。
也就是靠增加“节点数量”加强管辖区间的均匀。
同时,观察增加节点后数据变动情况
for item in range(ITEMS):
h = _hash(str(item))
n = bisect_left(ring, h) % (NODES*VNODES)
n2 = bisect_left(ring2, h) % (NODES2*VNODES)
if hash2node[ring[n]] != hash2node2[ring2[n2]]:
change += 1
另一种改进
然而,虚节点这种靠数量取胜的策略增加了存储这些虚节点信息所需要的空间。
在OpenStack的Swift组件中,使用了一种比较特殊的方法来解决分布不均的问题,改进了这些数据分布的算法,将环上的空间均匀的映射到一个线性空间,这样,就保证分布的均匀性。
原理图

核心代码
for part in range(2 ** LOG_NODE):
ring.append(part)
part2node[part] = part % NODES
for item in range(ITEMS):
h = _hash(item) >> PARTITION
part = bisect_left(ring, h)
n = part % NODES
node_stat[n] += 1
可以看到,数据分布是比较理想的。如果节点数刚好和分区数相等,理论上是可以均匀分布的。
增加节点
而观察下增加节点后的数据移动比例
for part in range(2 ** LOG_NODE):
ring.append(part)
part2node[part] = part % NODES
part2node2[part] = part % NODES2
change = 0
for item in range(ITEMS):
h = _hash(item) >> PARTITION
p = bisect_left(ring, h)
p2 = bisect_left(ring, h)
n = part2node[p] % NODES
n2 = part2node2[p] % NODES2
if n2 != n:
change += 1
小结
本节详细讲述了一致性hash的原理,后续我们将学习如何使用 java 实现一个工具。

参考资料
https://blog.csdn.net/lihao21/article/details/54193868
https://yikun.github.io/2016/06/09/%E4%B8%80%E8%87%B4%E6%80%A7%E5%93%88%E5%B8%8C%E7%AE%97%E6%B3%95%E7%9A%84%E7%90%86%E8%A7%A3%E4%B8%8E%E5%AE%9E%E8%B7%B5/
http://afghl.github.io/2016/07/04/consistent-hashing.html
https://zh.wikipedia.org/wiki/%E4%B8%80%E8%87%B4%E5%93%88%E5%B8%8C
https://blog.csdn.net/sunxinhere/article/details/7981093
http://blog.huanghao.me/?p=14
- 代码实现
Consistent-hashing C 语言实现
- chord
http://101.96.10.64/db.cs.duke.edu/courses/cps212/spring15/15-744/S07/papers/chord.pdf
https://github.com/ChuanXia/Chord
https://en.wikipedia.org/wiki/Chord_(peer-to-peer)
http://www.yeolar.com/note/2010/04/06/p2p-chord/
https://github.com/ChuanXia/Chord
https://github.com/netharis/Chord-Implementation/blob/master/Chord/Chord.java
https://github.com/TitasNandi/Chord-JAVA
- kademlia
http://www.yeolar.com/note/2010/03/21/kademlia/
https://en.wikipedia.org/wiki/Kademlia