机器学习实战笔记7——逻辑回归
任务安排
1、机器学习导论 8、核方法
2、KNN及其实现 9、稀疏表示
3、K-means聚类 10、高斯混合模型
4、主成分分析 11、嵌入学习
5、线性判别分析 12、强化学习
6、贝叶斯方法 13、PageRank
7、逻辑回归 14、深度学习
逻辑回归(LR)
Ⅰ 最大似然估计
后面的线性回归及逻辑回归均会用到最大似然估计,这里提前讲解,方便后续使用
似然函数:
设 X X X 为离散随机变量, θ = ( θ 1 , . . . , θ k ) θ=(θ_1,...,θ_k) θ=(θ1,...,θk) 为待估计的多维参数向量,若随机变量 x 1 , . . . , x n x_1,...,x_n x1,...,xn 相互独立且与 X X X 同分布,
记 P ( X i = x i ) = p ( x i ; θ ) P(X_i=x_i)=p(x_i;θ) P(Xi=xi)=p(xi;θ),则 P ( X 1 = x 1 , . . . , X n = x n ) = ∏ i = 1 n P ( X i = x i ) = ∏ i = 1 n p ( x i ; θ ) P(X_1=x_1,...,X_n=x_n)=∏^n_{i=1}P(X_i=x_i)=∏^n_{i=1}p(x_i;θ) P(X1=x1,...,Xn=xn)=i=1∏nP(Xi=xi)=i=1∏np(xi;θ) 称 L ( θ ) = ∏ i = 1 n p ( x i ; θ ) L(θ)=∏^n_{i=1}p(x_i;θ) L(θ)=∏i=1np(xi;θ) 为似然函数(Likelihood function)
最大似然估计算法:
①写出似然函数: L ( θ 1 , . . . , θ k ) = L ( x 1 , . . . , x n ; θ 1 , . . . , θ k ) = ∏ i = 1 n f ( x i ; θ 1 , . . . , θ k ) L(θ_1,...,θ_k)=L(x_1,...,x_n;θ_1,...,θ_k)=∏^n_{i=1}f(x_i;θ_1,...,θ_k) L(θ1,...,θk)=L(x1,...,xn;θ1,...,θk)=i=1∏nf(xi;θ1,...,θk) n n n 为样本数量,似然函数表示 n n n 个样本(事件)同时发生的概率
②对似然函数取对数: ln L ( θ 1 , . . . , θ k ) = ∑ i = 1 n ln f ( x i ; θ 1 , . . . , θ k ) \ln L(θ_1,...,θ_k)=∑^n_{i=1}\ln f(x_i;θ_1,...,θ_k) lnL(θ1,...,θk)=i=1∑nlnf(xi;θ1,...,θk) ③将对数似然函数对各参数求偏导并令其为0,得到对数似然方程组
④求解方程组得到各个参数
Ⅱ 线性回归(Linear Regression)
模型介绍
回归分析目的: 设法找出变量间的关联/依存(数量)关系,用函数关系式表达
①一元线性回归: y i = a + b x i + e i y_i=a+bx_i+e_i yi=a+bxi+ei
其中:
a a a 是截距
b b b 是回归系数(回归直线的斜率)
e i e_i ei 是残差/损失(服从高斯分布)
②多元线性回归: y i = b 0 + b 1 x 1 i + … + b n x n i + e i y_i=b_0+b_1x_{1i}+…+b_nx_{ni}+e_i yi=b0+b1x1i+…+bnxni+ei
其中:
b 0 b_0 b0 是常数项,是各变量都等于0时,因变量的估计值,也称本底值
b i b_i bi 是偏回归系数,其统计学意义是在其他所有自变量不变的情况下,某一自变量每变化一个单位,因变量平均变化的单位数
★目标函数
①目标函数求解
线性回归假设特征和结果满足线性关系,得到预测模型(几何意义是一个拟合平面) h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + … … = ∑ i = 1 n θ i x i = h θ ( x ) = θ T x h_θ(x)=θ_0+θ_1x_1+θ_2x_2+……=∑^n_{i=1}θ_ix_i=h_θ(x)=θ^Tx hθ(x)=θ0+θ1x1+θ2x2+……=i=1∑nθixi=hθ(x)=θTx θ θ θ 表示 x x x 对预测值 h θ ( x ) h_θ(x) hθ(x) 的影响权重
代入之前的模型,则得 y i = θ T x i + ε i y_i=θ^Tx_i+ε_i yi=θTxi+εi ε i ε_i εi 是每个样本点与预测值的差值(损失)
现在的问题就变成,要利用最大似然估计,求解最合适的 θ T θ^T θT,使得 ε i ε_i εi 最小,因为线性回归假设损失满足高斯分布,故得似然函数 L ( θ ) = ∏ i = 1 n p ( y i ∣ x i ; θ ) = ∏ i = 1 n 1 2 π σ e − ( y i − θ T x i ) 2 2 σ 2 L(θ)=∏^n_{i=1}p(y_i|x_i;θ)=∏^n_{i=1}\frac{1}{\sqrt{2π}σ}e^{-\frac{(y_i-θ^Tx_i)^2}{2σ^2}} L(θ)=i=1∏np(yi∣xi;θ)=i=1∏n2πσ1e−2σ2(yi−θTxi)2 对数似然函数 ln L ( θ ) = ln ∏ i = 1 n 1 2 π σ e − ( y i − θ T x i ) 2 2 σ 2 \ln L(θ)=\ln ∏^n_{i=1}\frac{1}{\sqrt{2π}σ}e^{-\frac{(y_i-θ^Tx_i)^2}{2σ^2}} lnL(θ)=lni=1∏n2πσ1e−2σ2(yi−θTxi)2 展开化简 ∑ i = 1 n ln 1 2 π σ e − ( y i − θ T x i ) 2 2 σ 2 = n ln 1 2 π σ − 1 σ 2 ⋅ 1 2 ∑ i = 1 n ( y i − θ T x i ) 2 ∑^n_{i=1}\ln \frac{1}{\sqrt{2π}σ}e^{-\frac{(y_i-θ^Tx_i)^2}{2σ^2}}=n\ln \frac{1}{\sqrt{2π}σ}-\frac{1}{σ^2}·\frac{1}{2}∑^n_{i=1}(y_i-θ^Tx_i)^2 i=1∑nln2πσ1e−2σ2(yi−θTxi)2=nln2πσ1−σ21⋅21i=1∑n(yi−θTxi)2
把可以求得的常数去掉,得到目标函数(保留 1 2 \frac{1}{2} 21为了得到最小二乘法公式) min J ( θ ) = 1 2 ∑ i = 1 n ( y i − θ T x i ) 2 \min J(θ)=\frac{1}{2}∑^n_{i=1}(y_i-θ^Tx_i)^2 minJ(θ)=21i=1∑n(yi−θTxi)2
②目标函数优化(最小二乘法)
J ( θ ) = 1 2 ∑ i = 1 n ( y i − θ T x i ) 2 = 1 2 ( X θ − y ) T ( X θ − y ) J(θ)=\frac{1}{2}∑^n_{i=1}(y_i-θ^Tx_i)^2=\frac{1}{2}(Xθ-y)^T(Xθ-y) J(θ)=21∑i=1n(yi−θTxi)2=21(Xθ−y)T(Xθ−y)
▽ θ J ( θ ) = ▽ θ ( 1 2 ( X θ − y ) T ( X θ − y ) ) \triangledown_{θ}J(θ)=\triangledown_{θ}(\frac{1}{2}(Xθ-y)^T(Xθ-y)) ▽θJ(θ)=▽θ(21(Xθ−y)T(Xθ−y))
= ▽ θ ( 1 2 ( θ T X T − y T ) ( X θ − y ) ) =\triangledown_{θ}(\frac{1}{2}(θ^TX^T-y^T)(Xθ-y)) =▽θ(21(θTXT−yT)(Xθ−y))
= ▽ θ ( 1 2 ( θ T X T X θ − θ T X T y − y T X θ + y T y ) ) =\triangledown_{θ}(\frac{1}{2}(θ^TX^TXθ-θ^TX^Ty-y^TXθ+y^Ty)) =▽θ(21(θTXTXθ−θTXTy−yTXθ+yTy))
= 1 2 ( 2 X T X θ − X T y − ( y T X ) T ) =\frac{1}{2}(2X^TXθ-X^Ty-(y^TX)^T) =21(2XTXθ−XTy−(yTX)T)
= X T X θ − X T y =X^TXθ-X^Ty =XTXθ−XTy
令偏导 ▽ θ J ( θ ) = 0 \triangledown_{θ}J(θ)=0 ▽θJ(θ)=0,则 θ = ( X T X ) − 1 X T y θ=(X^TX)^{-1}X^Ty θ=(XTX)−1XTy
最终,我们成功找到了使样本点到回归模型距离最短的线(面)

Ⅲ 逻辑回归(Logistic Regression)
线性回归与非线性回归
学习了线性回归,我们已经能较好地解决符合线性特征的样本了,但是,如果样本是如下图一样非线性的,又该如何解决呢?——逻辑回归
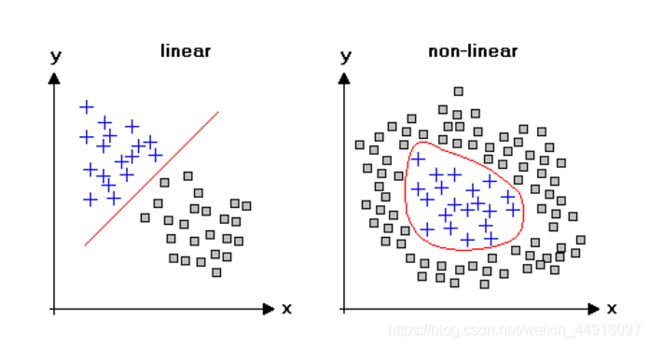
虽然线性回归和逻辑回归都属于监督学习范畴,但不同于线性回归的是,名字带有“回归”的逻辑回归,不属于回归,而属于分类,根本原因在于它以对数几率函数(Logistic function)作为激活函数(在人工神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端),使其取值范围被限定在了 [ 0 , 1 ] [0,1] [0,1],因此逻辑回归常常用来解决二分类、非线性问题(当然也可以通过设定多阈值来解决多分类问题)
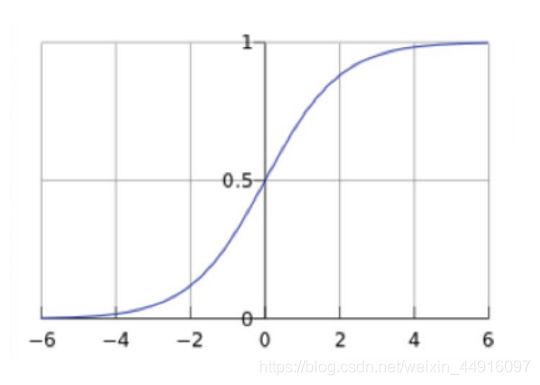
对数几率函数(Logistic function)
如图是 L o g i s t i c Logistic Logistic 函数,是 S i g m o i d Sigmoid Sigmoid 函数(形状S型函数)的代表,其特点是自变量在0的附近时,因变量会迅速分离开来,因此对于二分类问题非常方便,其函数表达式为 g ( z ) = 1 1 + e − z g(z)=\frac{1}{1+e^{-z}} g(z)=1+e−z1
故可以得到逻辑回归预测函数 h θ ( x ) = g ( θ T x ) = 1 1 + e − θ T x h_θ(x)=g(θ^Tx)=\frac{1}{1+e^-θ^Tx} hθ(x)=g(θTx)=1+e−θTx1
对上式变换,得到 ln h θ ( x ) 1 − h θ ( x ) = θ T x \ln \frac{h_θ(x)}{1-h_θ(x)}=θ^Tx ln1−hθ(x)hθ(x)=θTx,即对于输入 x x x,预测的分类结果有: P ( y = 1 ∣ x ; θ ) = h θ ( x ) P(y=1|x;θ)=h_θ(x) P(y=1∣x;θ)=hθ(x) P ( y = 0 ∣ x ; θ ) = 1 − h θ ( x ) P(y=0|x;θ)=1-h_θ(x) P(y=0∣x;θ)=1−hθ(x)
损失函数
不同于线性回归假设损失满足高斯分布,逻辑回归假设损失满足伯努利分布(二项分布在试验次数n=1时的特例)
类比之前用最大似然估计的求法,似然函数: L ( θ ) = ∏ i = 1 m p ( y ∣ x ; θ ) = ∏ i = 1 m h θ ( x i ) y i ( 1 − h θ ( x i ) ) 1 − y i L(θ)=∏^m_{i=1}p(y|x;θ)=∏^m_{i=1}h_θ(x_i)^{y_i}(1-h_θ(x_i))^{1-y_i} L(θ)=i=1∏mp(y∣x;θ)=i=1∏mhθ(xi)yi(1−hθ(xi))1−yi 取对数,对数似然函数: ln L ( θ ) = ∑ i = 1 m y i ln h θ ( x i ) + ( 1 − y i ) ln ( 1 − h θ ( x i ) ) \ln L(θ)=∑^m_{i=1}y_i\ln h_θ(x_i)+(1-y_i)\ln (1-h_θ(x_i)) lnL(θ)=i=1∑myilnhθ(xi)+(1−yi)ln(1−hθ(xi)) 定义目标函数为: min J ( θ ) = − 1 m [ ∑ i = 1 m y i ln h θ ( x i ) + ( 1 − y i ) ln ( 1 − h θ ( x i ) ) ] \min J(θ)=-\frac{1}{m}[∑^m_{i=1}y_i\ln h_θ(x_i)+(1-y_i)\ln (1-h_θ(x_i))] minJ(θ)=−m1[i=1∑myilnhθ(xi)+(1−yi)ln(1−hθ(xi))] 该函数也叫交叉熵损失函数,在通信原理中常用
梯度下降法
对于非线性问题,最小二乘法也可以使用,但是比起线性会复杂不少,故这里采用梯度下降(迭代)来求解参数
参数更新公式: θ j : = θ j − α ∂ ∂ θ j J ( θ ) = θ j − α 1 m ∑ i = 1 m ( h θ ( x ( i ) − y ( i ) ) x j ( i ) ) θ_j:=θ_j-α\frac{\partial}{\partialθ_j}J(θ)=θ_j-α\frac{1}{m}∑^m_{i=1}(h_θ(x^{(i)}-y^{(i)})x_j^{(i)}) θj:=θj−α∂θj∂J(θ)=θj−αm1i=1∑m(hθ(x(i)−y(i))xj(i))
参考 线性回归
逻辑回归(Logistic Regression, LR)简介
今日任务
1.给定图像数据集,比较分类性能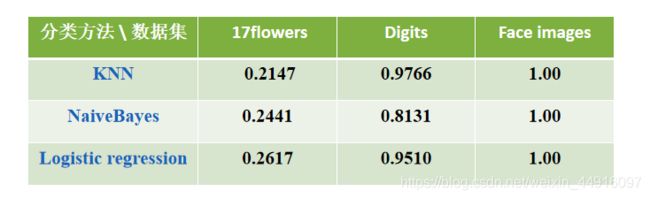
2.给定图像数据集CIFAR10,比较分类性能

任务解决
1、老师还让我们也跑一下线性回归的,不难,写法和之前差不多
from sklearn.datasets import load_digits
from sklearn.linear_model import LogisticRegression, LinearRegression
from sklearn.model_selection import train_test_split
import numpy as np
import os
import cv2 as cv
def createDatabase(path):
# 查看路径下所有文件
TrainFiles = os.listdir(path) # 遍历每个子文件夹
# 计算有几个文件(图片命名都是以 序号.jpg方式)
Train_Number = len(TrainFiles) # 子文件夹个数
X_train = []
y_train = []
# 把所有图片转为1维并存入X_train中
for k in range(0, Train_Number):
Trainneed = os.listdir(path + '/' + TrainFiles[k]) # 遍历每个子文件夹里的每张图片
Trainneednumber = len(Trainneed) # 每个子文件里的图片个数
for i in range(0, Trainneednumber):
image = cv.imread(path + '/' + TrainFiles[k] + '/' + Trainneed[i]).astype(np.float32) # 数据类型转换
image = cv.cvtColor(image, cv.COLOR_RGB2GRAY) # RGB变成灰度图
X_train.append(image)
y_train.append(k)
X_train = np.array(X_train)
y_train = np.array(y_train)
return X_train, y_train
# 逻辑回归分类器
def test_LR(*data):
X_train, X_test, y_train, y_test = data
lr = LogisticRegression(max_iter=10000)
lr.fit(X_train, y_train)
print('逻辑回归分类器')
print('Testing Score: %.4f' % lr.score(X_test, y_test))
return lr.score(X_test, y_test)
def test_Linear(*data):
X_train, X_test, y_train, y_test = data
linear = LinearRegression()
linear.fit(X_train, y_train)
print('线性回归分类器')
print('Testing Score: %.4f' % linear.score(X_test, y_test))
path_face = 'C:/Users/1233/Desktop/Machine Learning/face_images/'
path_flower = 'C:/Users/1233/Desktop/Machine Learning/17flowers/'
X_train_flower, y_train_flower = createDatabase(path_flower)
X_train_flower = X_train_flower.reshape(X_train_flower.shape[0], 180*200)
X_train_flower, X_test_flower, y_train_flower, y_test_flower = \
train_test_split(X_train_flower, y_train_flower, test_size=0.2, random_state=22)
digits = load_digits()
X_train_digits, X_test_digits, y_train_digits, y_test_digits = \
train_test_split(digits.data, digits.target, test_size=0.2, random_state=22)
X_train_face, y_train_face = createDatabase(path_face)
X_train_face = X_train_face.reshape(X_train_face.shape[0], 180*200)
X_train_face, X_test_face, y_train_face, y_test_face = \
train_test_split(X_train_face, y_train_face, test_size=0.2, random_state=22)
print('17flowers分类')
test_LR(X_train_flower, X_test_flower, y_train_flower, y_test_flower)
test_Linear(X_train_flower, X_test_flower, y_train_flower, y_test_flower)
print('Digits分类')
test_LR(X_train_digits, X_test_digits, y_train_digits, y_test_digits)
test_Linear(X_train_digits, X_test_digits, y_train_digits, y_test_digits)
print('Face images分类')
test_LR(X_train_face, X_test_face, y_train_face, y_test_face)
test_Linear(X_train_face, X_test_face, y_train_face, y_test_face)效果图(可以看到,在比较复杂的数据集里,逻辑回归的性能会略好于别的分类方法,且线性回归性能随数据集复杂程度上升迅速下降)

根据官方给的该 s c o r e score score 函数返回值,是以决定系数(coefficient of determination)来判断回归方程拟合程度的
①平均值 y ˉ = 1 n ∑ i = 1 n y i \bar y=\frac{1}{n}∑^n_{i=1}y_i yˉ=n1i=1∑nyi②总平方和(The total sum of squares) S S t o t = ∑ ( y i − y ˉ ) 2 SS_{tot}=∑(y_i-\bar y)^2 SStot=∑(yi−yˉ)2③回归平方和(The regression sum of squares) S S r e g = ∑ ( f i − y ˉ ) 2 SS_{reg}=∑(f_i-\bar y)^2 SSreg=∑(fi−yˉ)2④决定系数(Coefficient of determination) R 2 = 1 − S S r e g S S t o t R^2=1-\frac{SS_{reg}}{SS_{tot}} R2=1−SStotSSreg
所以 s c o r e score score 函数返回值越接近1表示拟合程度越好,且有可能负数(这里和统计学里的可决系数定义不一样,统计学里的可决系数 R 2 ∈ [ 0 , 1 ] R^2∈[0, 1] R2∈[0,1])
2、CIFAR10在很多地方都有提供,老师让我们用 P y T o r c h PyTorch PyTorch 里的,可以直接导入( P y T o r c h PyTorch PyTorch 是一个开源的 Python 机器学习库(也有 C++,Java的库),基于 T o r c h Torch Torch,用于自然语言处理等应用程序)
然而安装 p y t o r c h pytorch pytorch 前, p i p pip pip又又又又又更新了,结果这次不知道什么原因,用机器学习实战笔记1——机器学习导论里原来记的命令行没更新成功,看了 s i t e − p a c k a g e site-package site−package 里面有新版20.1的包,但是安装 p y t o r c h pytorch pytorch 就是叫我升级,升级了就报错,无奈之下,又找到了一个新的升级方法——在 p y c h a r m pycharm pycharm 的 s e t t i n g setting setting里手动更新
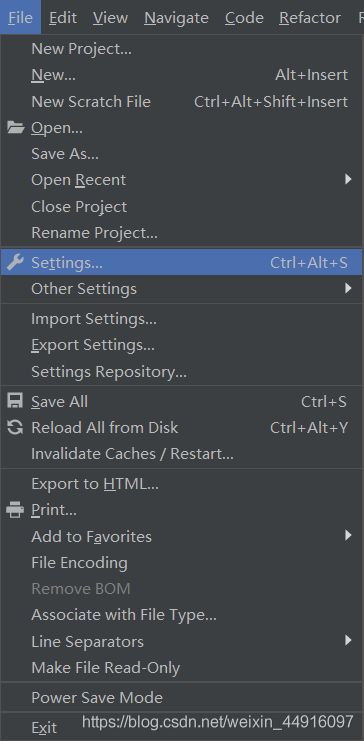

双击 L a t e s t Latest Latest v e r s i o n version version 一栏下方要更新的那个包
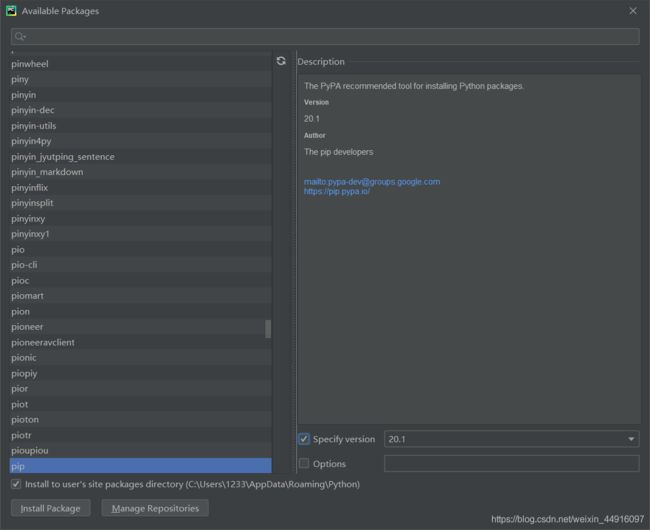
注意 左边 I n s t a l l t o … … Install to …… Installto…… 和右边 S p e c i f y Specify Specify v e r s i o n version version 都要勾选
更新完成再用下面命令行安装 p y t o r c h pytorch pytorch
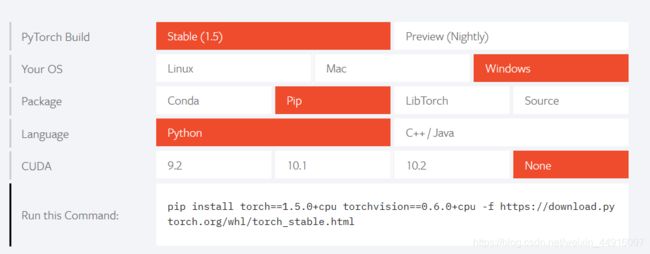
pip install torch==1.3.1 -f https://download.pytorch.org/whl/torch_stable.html
pip install torchvision==0.4.1
上PyTorch官网根据他们给的命令行下载也可以,但是通常速度非常慢
安装完以后,终于是可以开始跑了,用PyTorch中文文档里给的python代码把数据集CIFAR10载下来即可
from torchvision.datasets import CIFAR10
CIFAR10(root=path, download=True)当然,它是从官网上载的,非常慢,找到了一个前辈分享的CIFAR10百度云链接,下载以后解压出来,根据文档说的,把解压后的文件夹改成 “cifar-10-batches-py”,或者再用上面代码跑一遍,就会自动解压,输出
Files already downloaded and verified
即可

接下来是真的可以开始测试CIFAR10的分类性能了
import pickle
import numpy as np
from sklearn.linear_model import LogisticRegression
from myModule import clustering_performance
from sklearn.neighbors import KNeighborsClassifier
from sklearn import naive_bayes
path = 'C:/Users/1233/Desktop/Machine Learning/CIFAR10/cifar-10-batches-py/'
def unpickle(file): # 官方给的例程
with open(file, 'rb') as fo:
cifar = pickle.load(fo, encoding='bytes')
return cifar
def test_LR(*data):
X_train, X_test, y_train, y_test = data
lr = LogisticRegression(max_iter=10000)
lr.fit(X_train, y_train)
# ACC = lr.score(X_test, y_test)
print('逻辑回归分类器')
print('Testing Score: %.4f' % lr.score(X_test, y_test))
# print('Testing Score: %.4f' % ACC)
return lr.score(X_test, y_test)
def test_GaussianNB(*data):
X_train, X_test, y_train, y_test = data
cls = naive_bayes.GaussianNB() # ['BernoulliNB', 'GaussianNB', 'MultinomialNB', 'ComplementNB','CategoricalNB']
cls.fit(X_train, y_train)
# print('高斯贝叶斯分类器')
print('贝叶斯分类器')
print('Testing Score: %.4f' % cls.score(X_test, y_test))
return cls.score(X_test, y_test)
def test_KNN(*data):
X_train, X_test, y_train, y_test = data
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
y_sample = knn.predict(X_test)
print('KNN分类器')
ACC = clustering_performance.clusteringMetrics1(y_test, y_sample)
print('Testing Score: %.4f' % ACC)
return ACC
test_data = unpickle(path + 'test_batch')
for i in range(1, 4):
train_data = unpickle(path + 'data_batch_' + str(i))
X_train, y_train = train_data[b'data'][0:1234], np.array(train_data[b'labels'][0:1234])
X_test, y_test = test_data[b'data'][0:1234], np.array(test_data[b'labels'][0:1234])
print('data_batch_' + str(i))
test_KNN(X_train, X_test, y_train, y_test)
test_GaussianNB(X_train, X_test, y_train, y_test)
test_LR(X_train, X_test, y_train, y_test)效果图(训练集:测试集 = 1:1 只分别跑了batch1~3的前1234张,量实在是太大了,跑全部的时候电脑热得可怕,有电脑好的感兴趣的可以试试跑全部的效果,还可以试试线性回归分类,效果应该是非常不好的)
