java面试总结(1)
Mybatis一级缓存和二级缓存,作用范围
一级缓存是sqlSession级别的缓存 ,这个是默认开启的,一级缓存查询存在于每一个的sqlsession类的实例对象中当查询的时候,在同一个sqlSession中,去查询,第一次走数据库,第二次就会去查缓存,这个缓存对象也是个map 的接口,他的key 是由:hashcode+***statementId *** +sql 组成,value 就是查询的数据,当第二次查询的时候,发现这个map里面有值,就取缓存
sqlSession 在做insert,update,delete 的时候,会清除掉缓存;
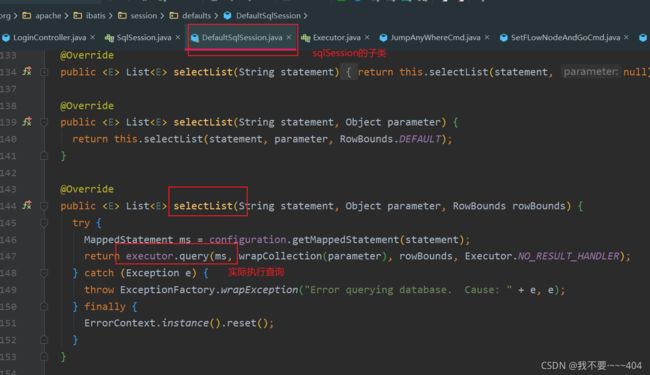

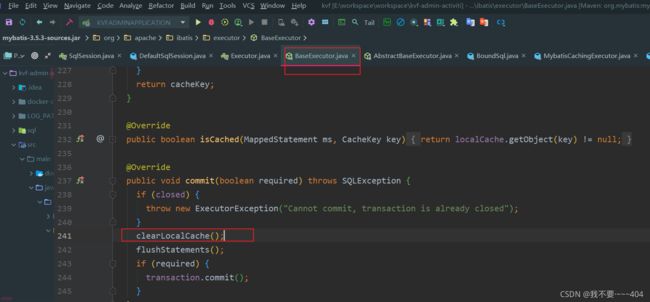
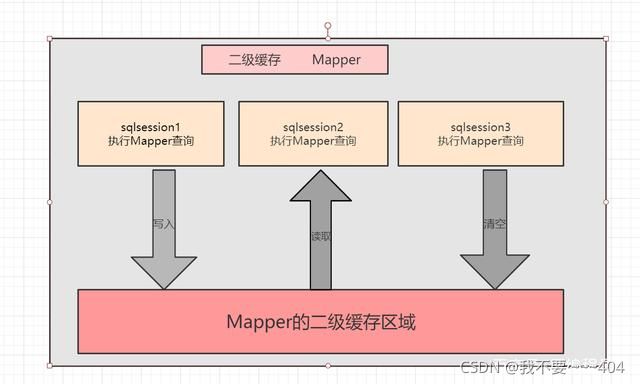
二级缓存是mapper级别的,Mybatis默认是没有开启二级缓存的。 第一次调用mapper下的SQL去查询用户的信息,查询到的信息会存放代该mapper对应的二级缓存区域二级缓存的范围就是mapper级别,也就是mapper以命名空间为单位创建缓存数据结构,也是map结构。二级缓存和 一级缓存一样的是,二级缓存的多个sqlsession去操作同一个mapper映射的sql语句,然后多个sqlsession可以共用二级缓存这样的一个思想,它是跨sqlsession的。
二级缓存的缺点:
Mybatis二级缓存作用域是sessionfactory,该缓存是以namespace为单位的(也就是一个Mapper.xml文件),不同namespace下的操作互不影响。所有对数据表的改变操作都会刷新缓存。但是一般不要用二级缓存,例如在UserMapper.xml中有大多数针对user表的操作。但是在另一个XXXMapper.xml中,还有针对user单表的操作。这会导致user在两个命名空间下的数据不一致。如果在UserMapper.xml中做了刷新缓存的操作,在XXXMapper.xml中缓存仍然有效,如果有针对user的单表查询,使用缓存的结果可能会不正确,读到脏数据。
synchronized与Lock的区别
synchronized 是java 关键字,是jvm层面
Lock 是个java类
synchronized 自动释放锁,在同步代码走完,或者出现异常都会自动释放锁,
lock ,需要调用unlock方法释放,一般写在finnaly里面,防止异常情况,造成死锁,
.用synchronized关键字的两个线程1和线程2,如果当前线程1获得锁,线程2线程等待。如果线程1阻塞,线程2则会一直等待下去,而Lock锁就不一定会等待下去,如果尝试获取不到锁,线程可以不用一直等待就结束了;
Lock锁,不一定等待?可以通过tryLock判断有没有锁)??????
ReentrantLock提供了多样化的同步,比如有时间限制的同步,可以被Interrupt的同步(synchronized的同步是不能Interrupt的)等。在资源竞争不激烈的情形下,性能稍微比synchronized差点点。但是当同步非常激烈的时候,synchronized的性能一下子能下降好几十倍。而ReentrantLock确还能维持常态。
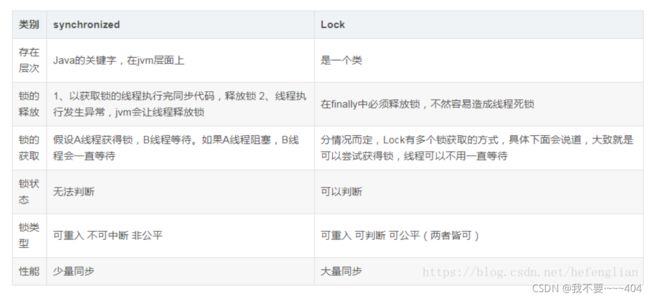
redis有哪几种数据类型?使用场景
string
hash hash 特别适合用于存储对象
set 集合,去重,无序的,随机事件
list
sorted set 有序集合,不重复的集合

https://blog.csdn.net/yanfei464486/article/details/113718941?spm=1001.2014.3001.5501
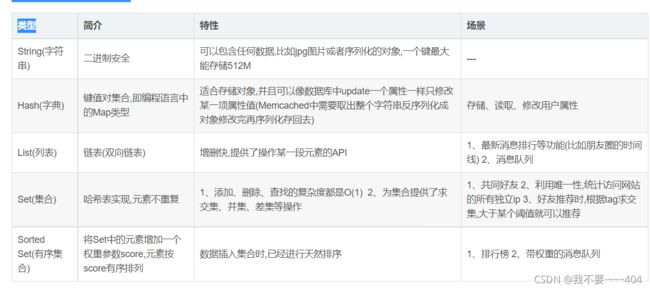
java的深拷贝和浅拷贝
浅拷贝要求继承Cloneable接口,并且实现父类的clone方法,
如果只是当前类实现了,那么如果当前类里有属性也是个对象,则拷贝的是地址,
如果要实现深拷贝。那么这个属性的这个类也要继承Cloneable接口,并且实现父类的clone方法,
https://blog.csdn.net/yanfei464486/article/details/112304117?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163405097716780271594194%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=163405097716780271594194&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogfirst_rank_v2~rank_v29-1-112304117.pc_v2_rank_blog_default&utm_term=%E6%8B%B7%E8%B4%9D&spm=1018.2226.3001.4450
线程池,使用的是什么线程池,使用的场景是怎样的?线程池有了解使用有什么注意事项
其他线程池?
ThreadPoolExecutor 的几大参数的含义
//顺序:先执行 核心线程-任务队列-最大线程-拒绝策略
ThreadPoolExecutor tpe = new ThreadPoolExecutor(
2, //核心线程数
4, //最大线程数
60, //生存时间,线程很长时间没干活,请归还给操作系统
TimeUnit.SECONDS, //生存时间的单位
new ArrayBlockingQueue<>(4), //任务队列
Executors.defaultThreadFactory(),//线程工厂
new ThreadPoolExecutor.CallerRunsPolicy()); //拒绝策略
for (int i = 0; i < 7; i++) {
tpe.execute(new Mytask(i));
}
System.out.println("任务队列:" + tpe.getQueue());
// tpe.execute(new Mytask(100));
//System.out.println(tpe.getQueue());
tpe.shutdown();
StringBuffer和StringBuilder,String区别
StringBuffer多线程安全,但是加了synchronized,其效率低
有了解java的哪几种设计模式?实际开发有用过哪些,使用场景
单例,责任链,策略模式,装饰者模式,代理模式,工厂模式,生产者消费者模式
Tomact类加载机制,说下双向委派,
双亲委派的作用:
避免类的重复加载
防止核心程序被篡改
https://blog.csdn.net/nsx_truth/article/details/109145080
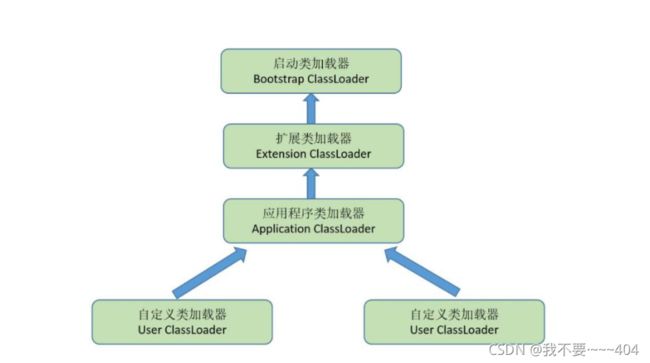
tomcat 的类加载机制:
tomcat 是反双亲委派的:
https://www.pianshen.com/article/9992213237/
redis缓存失效策略,淘汰算法有哪些
⑴定时删除: redis遍历所有设置了过期时间的key,来检测数据是否已经达到过期时间,然后对它进行删除.这种方式会对CPU产生额外压力,造成大量性能消耗,还会影响数据的读取操作. 对CPU不友好,用处理器性能换取存储空间(拿时间换空间)
⑵惰性删除: 数据到达过期时间,不作处理,等下次访问改数据时,如果数据未过期,返回数据;如果过期,删除,返回不存在.这种方式会导致大量无用数据占用内存,造成内存浪费. 对内存不友好,用存储空间换取处理器性能(拿空间换时间)
⑶定期删除: 定期删除是定时删除和惰性删除的折中.定期删除策略每隔一段时间执行一次删除过期键的操作,并通过限制删除操作执行的时长和频率来减少删除操作对CPU的影响. 周期性轮询redis中的数据,采用随机抽取的策略,利用过期数据占比的方式控制删除频度.定期删除策略的难点是确定删除操作执行的时长和频率.这种方式也会过期的key堆积在内存中,造成内存资源浪费.

索引创建规则
- 表的主键,外键必须有索引
- 多表查询,经常和其他表连接的表,在连接字段上建索引
- 数据量比较大的表
- 索引的字段最好是不重复的,重复太高的字段建索引就没意思
- 索引应该建在小字段上
索引的分类:主键索引,普通索引,唯一索引,组合索引
_第12张图片](http://img.e-com-net.com/image/info8/fbc0bb562023409b82c15e09d34fdfce.jpg)
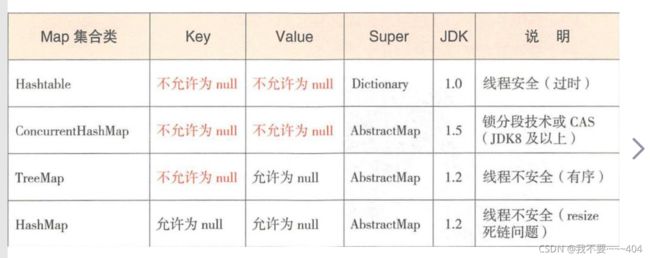
HashMap和Hashtable区别,treeMap,concurrentHashMap
- hashmap不安全,hashtable 安全
- hashtable 几乎把所有的方法都加了synchronized 同步锁,所以效率低,安全性好,
- hashMap ,key和value 都可以为null ,hashTable 都不可以为null
- 虽然hashtable 的安全性好,但是效率太低,所以在高并发的场景下还是推荐使用concurrentHashMap ,
下面是hashmap 的原理:
其实最底层还是一个数组接口,获取到一个key 值通过hash 算法得到一个地址的下标,然后把值存到这个地址里?
但是存在一个问题,hash冲突,冲突的时候用链表,
但是链表太长,性能也会变差,所以在1.8之后做了优化,在链表长度大于8的时候,链表结构转为红黑树
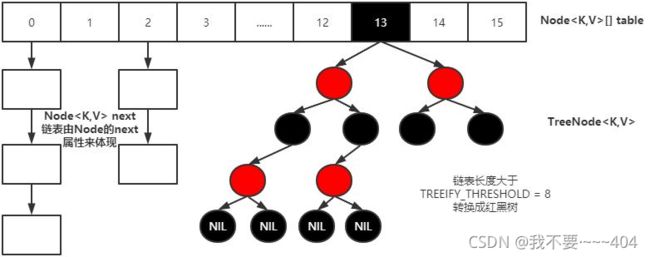
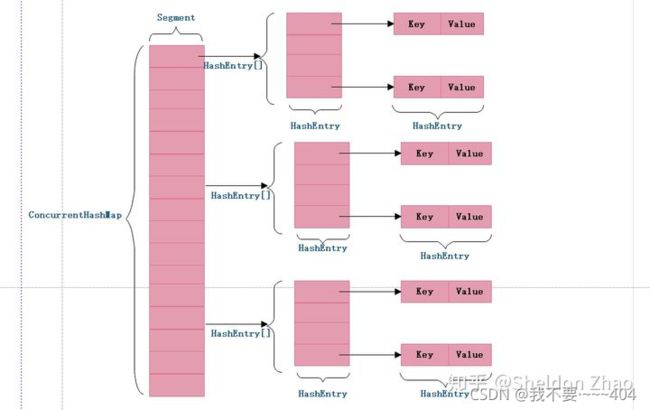
concurrentHashMap 原理
从ConcurrentHashMap代码中可以看出,它引入了一个“分段锁”的概念,具体可以理解为把一个大的Map拆分成N个小的HashTable,根据key.hashCode()来决定把key放到哪个HashTable中。
,它也有一些对线程友好方法:
https://zhuanlan.zhihu.com/p/104515829
构造分离锁,使得对于map的修改不会锁住整个容器,提高并发能力。
但是它需要 二次hash带来的问题是整个hash的过程比hashmap单次hash要长
JAVA7之前ConcurrentHashMap主要采用锁机制,在对某个Segment进行操作时,将该Segment锁定,不允许对其进行非查询操作,而在JAVA8之后采用CAS无锁算法,这种乐观操作在完成前进行判断,如果符合预期结果才给予执行,对并发操作提供良好的优化.
@Resource和@Autoware区别
Resource ,这个也是jdk 自带的注解,根据名称寻找,如果找不到会根据类型寻找
Autowire 只能根据类型查找
https://www.zhihu.com/question/39356740