Python爬虫(二)——多线程下载壁纸图片(星月设计网)
文章目录
-
-
- Python爬虫——多线程下载图片(星月设计网)
-
- 目的:
- redis存储结构:
- 使用到的python库:
- 1. 导入相关库
- 2. 连接redis
- 3.爬虫主要类及函数
- 4.爬取结果:
-
Python爬虫——多线程下载图片(星月设计网)
星月设计网
星月设计网的反爬虫机制较薄弱,我甚至没有加上headers就直接爬取成功了,懒人学习多线程非常合适。当然在之后我会尝试更复杂和有意义的数据爬取及数据分析。爬取星月设计网的图片一是可以做一些兴趣分析、而是可以做自己的壁纸用(见文末结果中的魔童降世敖丙的图片就很帅,爬取一堆图片方便选择)
目的:
学习多线程爬虫与练习图片缓存,熟悉redis应用(此处redis应用非常浅显)
redis存储结构:
使用hash存储,name为图片的名称,内部键值对包括了图片名称、图片url地址、图片作者、图片评分等信息
使用到的python库:
os、requests、redis、lxml、urllib.request、threading、queue等
1. 导入相关库
import os
import requests
import redis
from lxml import etree
import urllib.request
import time
import threading
from queue import Queue
2. 连接redis
pool = redis.ConnectionPool(host='localhost',port=6379,decode_responses=True)
r = redis.Redis(connection_pool=pool)
print(r.ping()) #验证连接
3.爬虫主要类及函数
代码中没有很多的注释,因为就是一个很简单的多线程。为了更清楚爬虫的结构做以下解释:
- Producer——生产者,通过页面地址不断遍历得到每个图片的地址
- page_queue 用来保存页面的url
- img_queue 用来保存图片的url及图片名称
- Consumer——消费者,通过图片的地址进行下载图片
class Producer(threading.Thread):
def __init__(self,page_queue,img_queue,*args,**kwargs):
super(Producer, self).__init__(*args, **kwargs)
self.page_queue = page_queue
self.img_queue = img_queue
self.wallpaper_urls=[]
def run(self):
while True:
if self.page_queue.empty():
break
page_url = self.page_queue.get()
page_text = self.deal_url(page_url)
self.parse_indexPage(page_text)
for wallpaper_url in self.wallpaper_urls:
wallpaper_text = self.deal_url(wallpaper_url)
self.parse_detailPage(wallpaper_text)
def deal_url(self,url):
response = requests.get(url)
response.encoding= response.apparent_encoding
return response.text
def parse_indexPage(self,text):
html = etree.HTML(text)
wallpaper_urls = html.xpath("//li[@class='wzbt']/a/@href")
for url in wallpaper_urls:
url = "https://www.vipxingyue.com/"+url
self.wallpaper_urls.append(url)
def parse_detailPage(self,text):
try:
html = etree.HTML(text)
wallpaper_name = "".join(html.xpath("//div[@class='h hm']/h1/text()")).strip()
wallpaper_author = "".join(html.xpath("//p[@class='xg1']/a/text()")).strip()
wallpaper_viewnum = "".join(html.xpath("//p[@class='xg1']/em/text()")).strip()
wallpaper_imgUrl = html.xpath("//td[@id='article_content']//a/@href")
r.hset(wallpaper_name,'name',wallpaper_name)
r.hset(wallpaper_name,'author',wallpaper_author)
r.hset(wallpaper_name,'viewnum',wallpaper_viewnum)
for i,img_url in enumerate(wallpaper_imgUrl):
img_name = wallpaper_name+'_'+str(i+1)+'.jpg'
img_url = "https://www.vipxingyue.com/"+img_url
r.hset(wallpaper_name,img_name,img_url)
self.img_queue.put((img_name,img_url))
except:
print("没有该页信息")
class Consumer(threading.Thread):
def __init__(self,page_queue,img_queue,*args,**kwargs):
super(Consumer,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.img_queue.empty() and self.page_queue.empty():
break
img_name,img_url = self.img_queue.get()
self.save_img(img_name,img_url)
def save_img(self,img_name,img_url):
root= './2_figure/'
path = root+img_name
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
read_figure = requests.get(img_url)
with open(path,'wb')as f:
f.write(read_figure.content)
f.close()
print(path+" save ok!")
else:
print('文件已保存')
except:
print("文件爬取失败")
def main():
base_url = 'https://www.vipxingyue.com/wallpaper/index.php?page={}'
page_queue = Queue(20)
img_queue = Queue(200)
page_num = 10
for x in range(1,page_num+1):
url = base_url.format(x)
page_queue.put(url)
for x in range(5):
t = Producer(page_queue,img_queue)
t.start()
for x in range(5):
t = Consumer(page_queue,img_queue)
t.start()
if __name__ == '__main__':
main()
4.爬取结果:
爬取了20个页面共计600+张照片(请注意自己爬取的速度,不要给网站服务器造成过多的负担!!!)
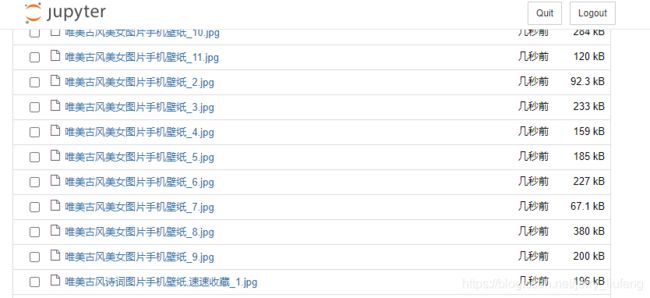

上图为爬取的结果之一。