人体动作识别与生成:基于ST-GCN的方法
本文转载自DeepBlue深兰科技。

ST-GCN: Spatial Temporal Graph Convolutional Networks时空图卷积网络,这个网络结构来源于CVPR 2018年的一篇文章《Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition》,也就是基于时空图卷积网络来做人体动作识别。
今天,我们就来了解下,如何基于ST-GCN来实现人体动作的识别与生成。

![]()
Why:为什么要使用ST-GCN?
ST-GCN网络训练好之后要达到的效果就是:用户提供一段视频,网络会输出视频中人的动作分类。

类似于上图中的视频,如何来识别视频中的人在做什么动作呢? 视频其实就是一帧一帧的图片拼接而成的,而传统处理图像识别的网络最常用的就是CNN(卷积神经网络),那ST-GCN是否跟CNN有关系呢?为什么要使用这个网络呢?
可以从以下三点来理解:
(1) 输入数据有量级的差别。举个例子,数据为一段10秒左右的视频,大概300帧,像素1920*1080,分别输入两个网络中。传统CNN是将所有视频拆分为一帧一帧的图片输入网络,而ST-GCN则直接输入人体的骨架关节数据,CNN的输入数据量约为ST-GCN的83000倍。
(2) 输入数据纯净度高,噪声少。CNN是将视频数据直接输入网络,包括了视频的背景以及图片中的各种噪音,而ST-GCN是仅仅将人体骨架关节点的信息输入网络,只保留了主要的有效信息,噪声低。
(3) 考虑了空间和时间上的相邻关节,效果更好。ST-GCN不仅考虑了空间上的相邻节点,也考虑了时间上的相邻节点,将邻域的概念扩展到了时间上,实验效果表明精度也更高。
![]()
What:ST-GCN到底是什么?
ST-GCN是TCN与GCN的结合。TCN,对时间维度的数据进行卷积操作;GCN,则对空间维度的数据进行卷积操作。GCN属于GNN,而GNN的基础是图论。神经网络处理的传统数据都是欧式距离结构的数据,比如二维的图像、一维的声音等等。而对于非欧式距离结构的数据,比如社交网络、交通运输网等等,传统的网络结构无法直接处理,而GNN就是用来处理这类型数据的。所以要了解ST-GCN,就要先从图论的一些基本理论入手,然后再延伸到GNN、GCN、ST-GCN。
2.1 图论
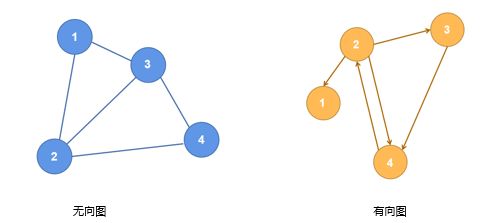
这里的图并不是指我们日常所见的图片,图的广泛概念包含具体的事物,以及事物之间的联系。图论中的图由两部分构成,即点和边。
点:图上具体的节点。
边:连接图上点和点之间的东西,边分为有向边和无向边。
图:节点V(G)和边E(G)构成的集合就是图,可以表示为:G = {V(G), E(G)}。图可以简单分为有向图和无向图(如下图所示)。
2.2 GNN
GNN: Group Neural Network 图神经网络,即结合图论与深度学习的网络结构。目前主要包含:Graph Convolutional Networks (GCN)、Graph Attention Networks、Graph Auto-encoder、Graph Generative Networks、Graph Spatial-Temporal Networks。最初的GNN网络,就是将点和边的特征一起传入网络中学习。
2.3 GCN
GCN:Graph Convolutional Networks 图卷积神经网络,顾名思义,是将图与卷积结合起来。根据卷积核的不同,主要分为spectral method(频谱方法)和spatial method(空间方法)。二者的区别在于:频谱方法基于拉普拉斯矩阵,与图的关系紧密联系,可泛化能力弱;空间方法则直接在图上定义卷积,对有紧密关系的节点进行操作,分为点分类和图分类。ST-GCN中的GCN属于图分类,且采用的是空间方法。
2.4 ST-GCN
ST-GCN:Spatial Temporal Graph Convolutional Networks时空图卷积网络,是在GCN的基础上提出的。核心观点是将TCN与GCN相结合,用来处理有时序关系的图结构数据。网络分为2个部分:GCN_Net与TCN_Net。
GCN_Net对输入数据进行空间卷积,即不考虑时间的因素,卷积作用于同一时序的不同点的数据。TCN_Net对数据进行时序卷积,考虑不同时序同一特征点的关系,卷积作用于不同时序同一点的数据。
![]()
How:ST-GCN 具体如何使用?
前部分讲了ST-GCN是什么,那我们回归到ST-GCN的具体应用上,首次提出ST-GCN是用来做人体动作识别,即通过一段视频来判断其中人的动作,也就是人体动作识别。
数据集:论文中使用的数据集为NTU-RGB+D,包含60种动作,共56880个样本,其中有40类为日常行为动作,9类为与健康相关的动作,11类为双人相互动作。数据集已经将视频中的人体动作转换为了骨架关节的数据,其中人体的骨架标注了25个节点,就是一种图结构的数据。


NTU-RGB+D数据集的分类
亮点:
(1) 邻接矩阵不采用传统的方式,采用一种新的方式,将邻接矩阵分为3个子集:根节点本身、向心力群,离心群。这一策略的灵感来自于身体部位的运动可以被广泛地归类为同心运动和偏心运动,通常距离重心越近,运动幅度越小,同时能更好地区分向心运动和离心运动。即下图中的(d)。
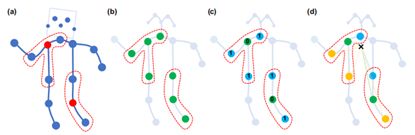
(2) 网络中加入可学习的边的权重,即加入attention机制。每层网络中邻接矩阵A都与可学习的权重相乘,这些权重在反向传播中更新。添加的原因是考虑到人体做不同的动作所侧重的关节点不同,而且添加了注意力机制更有利于提高网络的泛化能力。
整体效果:
使用ST-GCN的网络结构进行人体动作识别,论文中在NTU-RGB+D数据集的x_sub模式下识别精度达到81.5%,NTU-RGB+D数据集的x-view模式下识别精度达到88.3%,优于传统的人体动作识别网络。
![]()
团队工作亮点
ST-GCN的技术延展-动作生成
基于对ST-GCN在人体动作识别上的效果,我们将ST-GCN网络与VAE网络结合。目的在于获取人体动作的语义,进而生成人体的动作,最终可以应用于机器人动作模仿或者其他强化学习项目中。
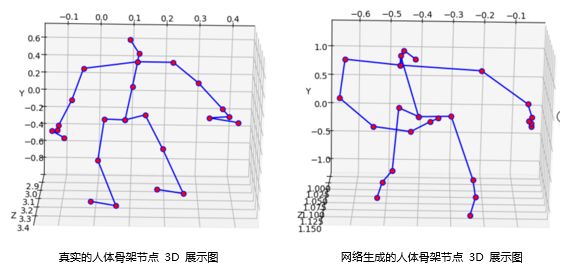
目前项目已在进行中,下图展示的是真实的人体骨架节点3D图与网络生成的人体骨架节点3D图。具体的研究结果,之后再跟大家分享,敬请期待。
END

备注:人体

人体动作检测与识别交流群
动作识别、动作检测等技术,
若已为CV君其他账号好友请直接私信。
我爱计算机视觉
微信号:aicvml
QQ群:805388940
微博知乎:@我爱计算机视觉
网站:www.52cv.net

在看,让更多人看到 