Hive架构及搭建方式
[TOC]
前言
本文档基于hive 3.1.2编写
hive的基础知识
基本架构

- 整个hive由hiveserver2和hive 客户端组成
- hive客户端有三种,beeline 、使用jdbc链接hiveserver、或使用hive CLI(这个已经过时,hive官方已经不推荐,推荐beeline)
- hive server本身由hive server2和metastore组成
- metastore是hive的元数据管理组件
- hcatalog 架设在metastore上,暴露一组api,使得其它框架,比如Pig,FLink能够使用hive的元数据管理功能,从而以表视角去管理数据
- webchat 是在hcatalog基础上暴露restful接口
- hive 的实际数据存储在hadoop的hdfs中
hue提供一个图形化的方式,方便用户做基于sql的开发,当然还有其他附加功能
metastore
hive的数据本质上存储在hdfs中的。如何以表的视角看到数据,这就是metastore的功劳,它存储了表的schema信息、序列化信息、存储位置信息等
metastore本身由两部分组成
- metastore server
- metatore db
这个经典的架构,像任何一个单体java应用一样,server是应用本身,db来存储数据。但具体metastore整体的部署模式上,有三种
内嵌服务和数据库

metastore server和metastore DB同hive server部署在一起,以内嵌的方式部署
其中metastore DB是启动了一个内嵌的Derby数据库
内嵌服务

metastore server还是跟hive一起部署。
但metastore DB使用独立的Mysql来承接
服务和数据库单独部署

除了数据库独立部署之外,metastore service本身也独立部署
hcatalog
hcatalog 架设在metastore上,暴露一组api,使得其它框架,比如Pig,FLink能够使用hive的元数据管理功能,从而以表视角去管理数据
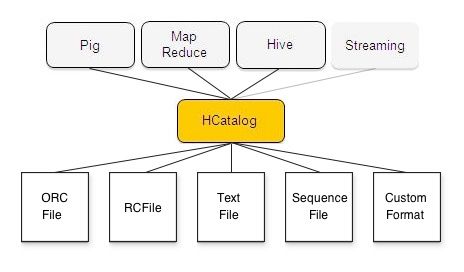
demo
hadoop distcp file:///file.dat hdfs://data/rawevents/20100819/data
hcat "alter table rawevents add partition (ds='20100819') location 'hdfs://data/rawevents/20100819/data'"上述命令先将文件拷贝到hdfs,然后通过hcatalog,将这份数据做为表rawevents的一个新分区
客户端
客户端的本地模式
上述介绍的metastore的嵌入或remote部署,都是以hiveserver的视角来说的。hiveserver本身是独立的部署。但在hive客户端来说,可以通过remote模式,连接到已经部署好的remote server 。 还可以启动客户端的时候,顺带起一个本地的hive server和其对应的metastore。这一点一定要搞清楚
beeline
做为hive推荐的新一代客户端。他使用Thrift 远程调用。 beeline的本地模式
$HIVE_HOME/bin/hiveserver2 #先独立部署hiveserver
$HIVE_HOME/bin/beeline -u jdbc:hive2://$HS2_HOST:$HS2_PORT # 然后以host加port的形式跟hiveserver链接
beeline的本地模式
$HIVE_HOME/bin/beeline -u jdbc:hive2:// #就是不加host和port,该操作会在同一个进程启动hiveserver 和metastore,以及beeline 。 不建议这样使用,只做单元测试本地和远程的区别,就是是否指定远程的Host和port。没有的话,就是本地模式
beeline的自动模式
每次通过beeline连接远端的hiveserver时,需要指定很长一段的jdbc url,很麻烦,如果我们想敲击beeline命令,直接就连接远端的hiveserver2,则可以在hive的配置文件目录添加beeline-site.xml配置文件,文件内容大致如下
beeline.hs2.jdbc.url.tcpUrl
jdbc:hive2://localhost:10000/default;user=hive;password=hive
beeline.hs2.jdbc.url.httpUrl
jdbc:hive2://localhost:10000/default;user=hive;password=hive;transportMode=http;httpPath=cliservice
beeline.hs2.jdbc.url.default
tcpUrl
其中配置了beeline连接的两种方式,和具体的jdbc连接字符串。一种使用tcp,一种使用http。默认是用tcp
jdbc
jdbc链接hive也有两种模式
- For a remote server, the URL format is
jdbc:hive2://(default port for HiveServer2 is 10000).: / ;initFile= - For an embedded server, the URL format is
jdbc:hive2:///;initFile=(no host or port).
部署
一个hive的完整部署涉及五个组件,主要需要部署前三个
- metastore的部署
- hiveserver2的部署
- client的部署
- hcatalog server 的部署(非必须)
- webhcat server的部署(非必须)
其中1,2两部可以何在一起,即hiveserver2内嵌metastore, 只是将metastore的DB,外挂到Mysql。
具体到物理服务器上,上述三个组件,可以部署到三个不同机器上,当然hive client一般会在多个机器上。
三个组件对应的配置都可以是hive-site.xml,但配置内容不一定相同。比如hiveserver2需要配置,meta DB的连接信息,但client则不需要这些信息。
除了hive-site.xml之外,hive还支持在其它几个地方进行配置
- 在启动命令时 通过
--hiveconf参数,指定定制化的配置,如bin/hive --hiveconf hive.exec.scratchdir=/tmp/mydir - 在 hivemetastore-site.xml文件中指定,metastore相关的配置
- 在hiveserver2-site.xml中指定,hiveserver2独享的配置。
以上这些路径和配置文件中拥有相同配置时,hive识别优先级如下,从左至右,依次升高
hive-site.xml -> hivemetastore-site.xml -> hiveserver2-site.xml -> '-hiveconf'
所以,最佳的配置策略是:
- 在hive-site.xml中配置,hiveserver2和hive client都共用的配置,这样方便该配置直接分发到多个机器
- 将metastore相关的配置放到 hivemetastore-site.xml 中。meta数据库相关配置,只在metaserver部署的机器上存在,不会四处分发数据库密码
- 将hiveserver2独有的配置放到hiveserver2-site.xml 中
部署hiveserver2
以下配置,采用内嵌metastore server , remote metastore DB的方式进行hiveserver 部署
在需要部署hive的机器上。创建一个hive账号,adduser hive 并将其加入hadoop组,所有后续配置和启动都以hive用户进行
下载hive安装包。将其中conf下的各template文件去掉,并按需进行配置。
hive-default.xml.template需要改成hive-site.xml
hive-default.xml.template包含了所有的hive各组件相关的默认配置。
详细部署文档:https://cwiki.apache.org/conf...
在hdfs中创建hive数据存放路径
在hdfs中创建以下文件,并给hive所属组赋写权限
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp
$ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse
$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp
$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse/user/hive/warehouse是hive中的表数据实际存储的地方。它是默认路径,你当然可以在hive-site.xml中通过设置hive.metastore.warehouse.dir属性来指定新的路径
配置hive的环境变量
export HIVE_HOME=/opt/apache-hive-3.1.2-bin/
export PATH=$HIVE_HOME/bin:$PATH配置日志输出路径
hive的默认输出路径为/tmp/,如果我们以hive用户启动,那么该路径为/tmp/hive/hive.log
/tmp路径是linux用来存放各应用程序运行时的中间状态数据,一般会在操作系统重启后,自动进行清理。
当然你可以修改hive的log4j文件,来指定hive.log.dir=路径
也可以在启动hiveserver2时,动态的去通过hiveconf参数指定路径bin/hiveserver2 --hiveconf hive.root.logger=INFO,DRFA
hive的临时文件配置
hive运行时也会在host本地,和hdfs中存放临时文件,称之为scratch文件。存放的文件路径为
hdfs :/tmp/hive-
本地:/tmp/
值得说明的是,hive-site.xml模板中,有大量路径配置是 ${java.io.tmpdir}/${user.name}/,${java.io.tmpdir}表示该配置的默认值是取Java使用临时目录,一般在linux下也即/tmp,${user.name}表示取当前启动hive的用户。你如果不特殊指定,可删除对应的配置项。而不要直接配置中也写成${java.io.tmpdir}/${user.name}/,xml中是识别不了这些占位符的。
配置metastore 的DB信息并初始化
在hive-site.xml对应的目录下,创建一个hivemetastore-site.xml文件,用于配置metastore相关信息
初始化metastore db
$HIVE_HOME/bin/schematool -dbType -initSchema 其中dbType的取值可以是derby, oracle, mysql, mssql, postgres
参考资料
https://cwiki.apache.org/conf...
启动hiveserver2
$HIVE_HOME/bin/hiveserver2上述命令为前台运行,最好以no hang up 加后后台方式运行
nohup $HIVE_HOME/bin/hiveserver2 > /opt/apache-hive-3.1.2-bin/logs/hive_runtime_log.log < /dev/null &启动后hive的web界面对应的端口是:10002
基本客户端部署
软件包分发
将上述hive发型包,同配置,拷贝到需要启动beeline的机器上,即完成客户端的配置。配置文件只需要hive-site.xml,可根据具体机器环境,去修改相应的路径配置信息,不需要hivemetastore-site.xml 和 hiveserver2-site.xml文件
环境变量配置
export HIVE_HOME=/opt/apache-hive-3.1.2-bin/
export PATH=$HIVE_HOME/bin:$PATH日志路径配置
同hiveserver一样,根据具体情况,做一些路径配置修改
启动
使用$HIVE_HOME/bin/beeline -u jdbc:hive2://$HS2_HOST:$HS2_PORT即可连接hiveserver2。
由于hive在hdfs中使用的目录,默认是/user/hive/warehouse,所以为了避免权限相关的错,需要在通过beeline链接是加-n参数,用于指定当前客户端使用的用户。并且该用户要有/user/hive/warehouse和其下文件的相关权限,没有的话需要单独加。权限模型,同Linux类似。如果有权限问题,一般的错误类似
Error: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:Got exception: org.apache.hadoop.security.AccessControlException Permission denied: user=yarn, access=WRITE, inode="/user/hive/warehouse/test.db":hive:hadoop:drwxr-xr-x带用户名链接为形式为:
beeline -u jdbc:hive2://master:10000 -n hive这里以hive用户链接到hiveserver
beeline整体使用文档:https://cwiki.apache.org/conf...
hiveserver高可用部署
服务端配置
在所有需要启动hiverserver的机器上,配置hiveserver2-site.xml。在其中做如下配置
hive.server2.support.dynamic.service.discovery
true
hive.server2.zookeeper.namespace
hiveserver2
hive.zookeeper.quorum
master:2181,slave1:2181,slave2:2181
同时记住,需要部署的hiverserver的机器,都要有相同metastore的配置,保证他们连得时同一个mysql,可将hivemetastore-site.xml配置拷贝至多个需要启动hiveserver的机器
参考资料:http://lxw1234.com/archives/2...
客户端连接
用beeline的连接方式如下:
beeline -u "jdbc:hive2://master:2181,slave1:2181,slave2:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2" -n hive注意其中的jdbc url一定要加引号
认证
这里选择Kerberos作为认证选项。其需要配置的三个配置项如下:
Authentication mode:
hive.server2.authentication – Authentication mode, default NONE. Options are NONE (uses plain SASL), NOSASL, KERBEROS, LDAP, PAM and CUSTOM.
Set following for KERBEROS mode:
hive.server2.authentication.kerberos.principal – Kerberos principal for server.
hive.server2.authentication.kerberos.keytab – Keytab for server principal.使用了kerberos认证后的beeline链接方式
beeline -u "jdbc:hive2://master:2181,slave1:2181,slave2:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2"上述命令使用前,一定保证已经通过kinit实现了当前机器的kerberos认证。否者beeline命令会报错,因为没有取到kerberos认证票据。
该命令会自动去读取,当前登录的kerberos用户信息,在执行的命令的时候带上
INFO : Executing with tokens: [Kind: HDFS_DELEGATION_TOKEN, Service: ha-hdfs:haixue-hadoop, Ident: (token for test: HDFS_DELEGATION_TOKEN owner=test, renewer=yarn, realUser=hive/[email protected], issueDate=1594627135369, maxDate=1595231935369, sequenceNumber=66, masterKeyId=27)]比如当前kerberos的tgt是test用户,那么该hivesql 对应的owner就是test。实际组件之间的通信认证是使用的hive/[email protected] 用户。但授权粒度会控制到test上。
这个特性是hive配置的的hive.server2.enable.doAs 属性来控制的,该属性为true时,表示运行以提交用户作为最终sql执行的用户
另外,最好我们在hiveserver的配置文件中,将hive.server2.allow.user.substitution关闭为false. 因为该选项,会允许用户以-n参数指定一个用户。这样会导致一个用户以自己的kerberos凭证,操作别人的库表。但禁用后,hue就无法将其登录用户做为提交job的人。
基于hive-site.xml的客户端连接
上述记录的连接hiveserver2的方式,是通过jdbc来实现的。但有些依赖hive的程序,则只能通过hive-site.xml 这种方式连接hiveserver。典型的就是hue
hue会去${HIVE_CONF_DIR}环境变量或者/etc/hive/conf路径下找hive-site.xml和beeline-hs2-connection.xml两个配置文件,读取其中的信息,实现对hiveserver的连接。
如果集群配置了kerberos,那么需要在hive-site.xml中配置,跟hiveserver2-site.xml一样的kerberos认证配置,例如
hive.server2.authentication
KERBEROS
hive.server2.authentication.kerberos.principal
hive/[email protected]
hive.server2.authentication.kerberos.keytab
/opt/keytab_store/hive.service.keytab
像hue 是使用beeline连接,还可以配置beeline-hs2-connection.xml,在其中指定一些些连接hiveserver2的代理用户信息,不过目前发现不配置依然可以使用。如下:
beeline.hs2.connection.user
hive
beeline.hs2.connection.password
hive
一些错误
错误1 guava
初始化metastore schema是报错
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V原因是hadoop路径share/hadoop/common/lib/下的guava包同hive的lib下的guava包版本不一致。
解决办法,删除hive的guava包,将hadoop的对应guava包拷贝过来
错误2,mysql驱动
[hive@master bin]$ ./schematool -dbType mysql -initSchema
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop-3.2.1/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://xxx.xx.xx.xx:3306/hive?createDatabaseIfNotExist=true
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to load driver
Underlying cause: java.lang.ClassNotFoundException : com.mysql.jdbc.Driver
Use --verbose for detailed stacktrace.
*** schemaTool failed ***问题原因,hive缺乏mysql的驱动
解决办法,下载一个mysql的驱动,安装到hive的lib下
错误3
当使用beeline客户端:beeline -u jdbc:hive2://master:10000链接,hiveserver2时,报以下错误
Error: Could not open client transport with JDBC Uri: jdbc:hive2://master:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: hive is not allowed to impersonate anonymous (state=08S01,code=0)
Beeline version 3.1.2 by Apache Hive我们是以hive用户,启动的hiveserver2。所以,所有客户端,无论以书面用户链接到hiveserver2,最终hiveserver2去访问hadoop集群时,都是以hive的用户去访问的。
但如果你没在hadoop中,做相关的配置,那hadoop默认是不允许hive这个用户作为其他用户的代理用户使用集群的,所以需要在hadoop的core-site.xml中,做以下配置
hadoop.proxyuser.hive.hosts
master,slave1,slave2
hadoop.proxyuser.hive.groups
*
hadoop.proxyuser.super.users
user1,user2
参考资料
https://cwiki.apache.org/conf...
https://cwiki.apache.org/conf...
https://stackoverflow.com/que...
https://cwiki.apache.org/conf...
欢迎关注我的个人公众号"西北偏北UP",记录代码人生,行业思考,科技评论