目标检测-温故而知新
双阶段(候选框提取、分类分开进行)
RCNN->Fast RCNN ->Faster RCNN->Mask-RCNN
单阶段
yolov1(2016cvpr)->ssd(2016 eccv oral)->yolov2(2017cvpr)->retinanet(focal loss)->yolov3(2018arvix)
研一在雁栖湖的时候有门课要求看一系列的论文并且写成ppt的形式。
当时主要看了目标检测方面的论文,有很多地方没理解。
最近有时间又回顾了一遍有一些新的想法,在这里记录一下。
对目标检测不熟悉的朋友可以先看博客最后的基础知识部分,主要包括数据增强,IOU,NMS,mAP。

图片来自参考文献[1]
RCNN系列
多阶段目标检测系列了解的少一点,知乎上看见有人对每篇文章都用一句话总结的不错,搬运一波。

https://www.zhihu.com/question/35887527
补充一个
Mask-RCNN解决的是,“为什么不进一步做实例分割”
于是何恺明尝试在Faster-RCNN的基础之上实现了实例分割,我理解实例分割相当于细粒度目标检测。
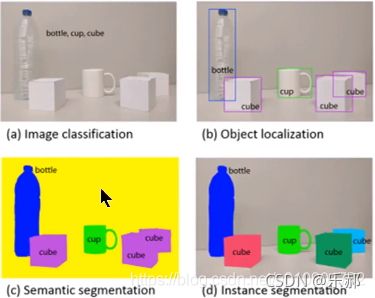
下面是一些我自己觉得RCNN系列中值得注意的地方
1)Faster RCNN 去掉了selective search ,可以端到端的进行训练,但是如果分4步进行训练的话精度会提升。
2)Faster RCNN 和 SSD 中位置损失使用Smooth L1 loss,yolo系列使用L2 loss,猜测是因为yolov2对位置信息使用了新的编码方式,将边界框中心点约束在当前cell中。
3)Mask-RCNN中的ROIAlign代替ROIPooling,我理解ROIAlign相当于亚像素级别的ROIPooling
yolo系列
发表的时间顺序
yolov1->ssd->yolov2->retinanet(focal loss)->yolov3
相对于R-CNN系列的"看两眼"(候选框提取与分类)
YOLO只需要You Only Look Once
YOLO统一为一个回归问题,最后输出时的confidence值,这个值决定了前景和背景。
这样做明显加快了速度,但是缺少了单独提取前景的网络region proposal net。
使得正负样本不平衡问题比较严重,yolov1中有无object的box对confidence预测的权重不同在一定程度上缓解这个问题
后续的focal loss也是针对正负样本不平衡问题以及难样本挖掘问题(类似faster-rcnn的OHEM)
yolov1
You Only Look Once:Unified, Real-Time Object Detection
最终输出的张量大小:7x7x((4+1)*2+20)
7x7个grid
2个box
每个box xyhw4个值以及confidence(红色部分)共5个值
每个grid预测20种类别的置信度(蓝色部分)


图片来自参考文献[2]
损失函数如下:
均为L2 loss
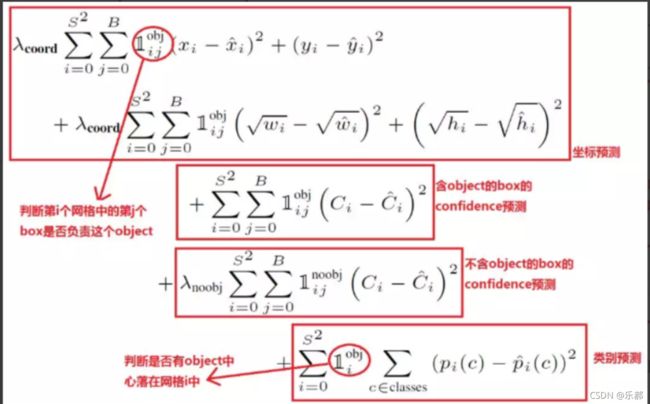
优点:
1)YOLO统一为一个回归问题,最后输出时的confidence值,这个值决定了前景和背景。
2)坐标预测,减少大框占的loss比例,这里对 [w,h] 在损失函数中的处理分别取了根号,缓解尺寸不平衡问题。
3)loss里面针对有无物体loss weight不同,也算是平衡正负样本
缺点:
1)每个grid只能检测一类物体中的一个物体,遇到密集物体,物体占画面比较低时,recall会比较低。
2)存在全链接层,只能单尺度训练
yolov2
YOLO9000: Better, Faster, Stronger
优点
1)引入了anchor box 代替了全链接层
a)可以多尺寸训练模型
b)每一个grid 可以预测一类物体中的多个物体
2)将训练数据集中的矩形框全部拿出来,用kmeans聚类得到先验框的宽和高。
3)多层softmax,充分利用标签之间的相关性信息,多次求解条件概率。
4)坐标预测:将边界框中心点约束在当前cell中,使用sigmoid函数处理偏移值,使得模型稳定。
5)引入Passthrough layer 多个尺寸下检测目标框,缓解小尺寸物体的识别效果不佳的问题。 ssd里面也有相似的操作。
tips:
多尺寸训练模型指的是输入的图片尺寸可以不同。
多个尺寸下检测目标框指的是在不同的感知野下做目标检测,可以同时检测出较大的物体以及较小的物体。
缺点
1)单标签预测。
2)小物体检测效果不好。
多次计算条件概率
下图的softmax指的是进行了多次softmax计算

yolov2的损失函数如下:
类别损失类似yolov1里面针对有无物体loss weight不同,有助于平衡正负样本
[w,h]的预测部分通过(2-wh)缓解尺寸不平衡问题。(yolov2修改了xywh的预测方式)

yolov3
1)单标签->多标签
bceloss+sigmoide->L2+softmax
谷歌的open image论文中有提到过imagenet数据集中存在大量图片不止有一个标签,但是只打了一个标签的情况。
2)多尺度特征融合FPR
yolov2中的Passthrough的升级版,有点类似resnet,unet。
在多个尺度下进行目标检测。
以输入图像为416416为例,YOLOv2中一张图片需要预测13135=845个边界框,而YOLOv3中需要预测(1313+2626+5252)*3=10647个边界框。

RetinaNet(focal loss)
Focal Loss for Dense Object Detection
下图的红色部分用来缓解正负样本不平衡的问题。
对正样本设置更改的权重,通常为0.25。
下图的蓝色部分用来进行难样本挖掘,类似Faster RCNN中的OHEM(online hard example mining)。
预测概率越高的目标,可信度越高,需要更少的关注。

focal loss带来的变化

图片来自参考文献[3]
基础知识
数据增强
目标检测中的数据增强是比较复杂,每一次改变图像同时也要考虑boxes的信息。
比起目标分类更加局限性,比如翻转,左右翻转一般影响不大,但上下翻转造成的影响就截然不同。
参考资料
https://www.freesion.com/article/6083573650/
iou 交集/并集
目标检测和图像分割都往往用到iou,miou等概念。
miou:对各个类别的IOU进行平均。
手写iou计算
def bb_intersection_over_union(boxA, boxB):
boxA = [int(x) for x in boxA]
boxB = [int(x) for x in boxB]
xA = max(boxA[0], boxB[0])
yA = max(boxA[1], boxB[1])
xB = min(boxA[2], boxB[2])
yB = min(boxA[3], boxB[3])
interArea = max(0, xB - xA + 1) * max(0, yB - yA + 1)
boxAArea = (boxA[2] - boxA[0] + 1) * (boxA[3] - boxA[1] + 1)
boxBArea = (boxB[2] - boxB[0] + 1) * (boxB[3] - boxB[1] + 1)
iou = interArea / float(boxAArea + boxBArea - interArea)
return iou
上述代码之所以很多地方需要+1,是因为这里的0->1的距离指的是[0,1]中一共有多少个像素,即像素0和像素1,共2个像素。
参考资料
https://blog.csdn.net/weixin_42135399/article/details/101025941
非极大值抑制—NMS(Non-Maximum Suppression)
解决的问题:
检测出的目标框太多,有很多重复的框,同一物体对应多个框,应该只保留置信度比较高的一个。
(不同类的目标框不构成竞争关系,不会因此被删除)
视频边缘检测的方法中似乎也用到了NMS。

所谓非极大值抑制:
先假设有6个输出的矩形框(即proposal_clip_box),根据分类器类别分类概率做排序,从小到大分别属于车辆的概率(scores)分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框。
soft NMS
soft NMS算法:
NMS算法直接删除IOU过大的框太绝对了,IOU过大降低置信度即可。
和NMS只差一行代码。
大致思路为:
M为当前得分最高框,bi 为待处理框,bi 和M的IOU越大,bi 的得分si 就下降的越厉害。

更进一步还有softer NMS,暂时没有详细了解。
参考资料
https://www.cnblogs.com/makefile/p/nms.html
https://zhuanlan.zhihu.com/p/89426063
mAP
P:准确率
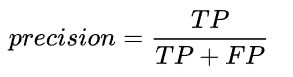
AP :不同召回率上的平均precision
单单一个precision不足以衡量系统的好坏,于是引入了AP(Average Precision)——不同召回率上的平均precision。
mAP:所有类别的AP平均值
参考资料
https://zhuanlan.zhihu.com/p/37910324
参考资料
[1] https://zhuanlan.zhihu.com/p/70387154
[2] https://www.cnblogs.com/ywheunji/p/10808989.html
[3] https://blog.csdn.net/wwwhp/article/details/83317738