LIBSVM安装和使用实验(Windows 10)
目录
1. 概要
2. LIBSVM安装
2.1 下载
2.2 python安装
3. 第一个实验
3.1 数据下载
3.2 基于原始数据直接训练和预测
3.3 对数据进行scaling后再做训练和预测
3.4 自动化的参数搜索
3.5 全流程自动化
3.5.1 gnuplot安装
3.5.2 运行easy.py
4. 小结
1. 概要
本文介绍在Windows10下安装LIBSVM以及确认安装的实验结果。
2. LIBSVM安装
2.1 下载
从github(https://github.com/cjlin1/libsvm)上下载该软件包。
For MS Windows users, there is a sub-directory in the zip file containing binary executable files.
嗯,有过暗黑的编译安装体验折磨过的小伙伴可以安心了,啥都不用做,直接用就是了。但是为了windows工具的使用方便,将路径加入到系统路径变量中去是一个明智的做法。设置方法如下:
此电脑à属性à高级系统设置à环境变量:将libsvm-master\windows加入到系统变量之path变量中去就可以了。
2.2 python安装
为了在python环境中也能够正常使用,以下也进行了python安装。不过在本文后面的实验中并没有用到这个安装。
参照LIBSVM -- A Library for Support Vector Machines (ntu.edu.tw),在Anaconda Prompt中:
> pip install -U libsvm-official
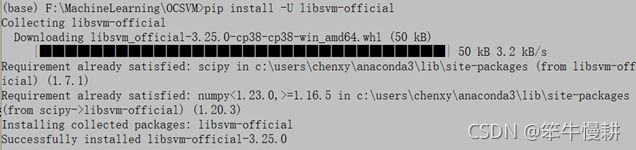
安装成功。。。就这么简单完了?有点不知所措。主要是python安装各种包有过太多残酷体验。。。加之看有些博客也渲染了这种恐惧情绪(也许是针对以前版本的安装)。看来作者已经很好地解决了这些鸡零狗碎的问题。
安装目录:C:\Users\username\Anaconda3\Lib\site-packages\libsvm

3. 第一个实验
3.1 数据下载
在[1].A.1中有具体的操作过程。但是,纸上得来终觉浅,绝知此事须躬行。。。实际操作再现一遍是入门学习的正确姿态。
数据下载:LIBSVM Data: Classification (Binary Class) (ntu.edu.tw)
svmguide1.txt: 训练数据
svmguide1.t: 测试数据
以下假定数据都存放在.\svmguide1目录底下。在该目录中启动一个terminal(Windows PowerShell, Anaconda Prompt, 或甚至dos终端啥的应该都可以。以下我用Anaconda Prompt,“>>”表示命令行提示符)。但是要记住在设置修改系统路径后需要重启一下终端路径设置的更改才能生效。
3.2 基于原始数据直接训练和预测
>> svm-train svmguide1.txt

以上运行在同一目录下生成了svmguide1.txt.model文件,表示已经训练好的模型。
>> svm-predict svmguide1.t svmguide1.txt.model svmguide1.t.predict
![]()
这个命令表示用训练好的模型对测试数据svmguide1.t进行预测,预测结果存在svmguide1.t.predict文件中。
3.3 对数据进行scaling后再做训练和预测
接下来参照文档[1]进行正确的训练和预测流程:
(1) Data scaling
>> svm-scale -l -1 -u 1 -s range1 svmguide1.txt > svmguide1.scale
以上命令表示将数据scaling到[-1,1]区间(下限和上限分别由-l,-u参数指定)。”-s range1”的作用是啥呢,参见下面的说明。生成的数据放在svmguide1.scale,对比这个文件与原始的svmguide1.txt可以看到数据范围已经变化了。
(2) 对测试数据施以同样的scaling处理
>> svm-scale -r range1 svmguide1.t > svmguide1.t.scale
“-r range1”的作用是指从参数文件中恢复出range1参数用于测试数据的scaling。在上一条命令执行后会生成”range1”文件,”-s”很显然表示存储(save)的意思。”-r”则表示”recovery”的意思—以上是我的猜测,但是大抵应该靠谱的。
测试数据与训练数据用相同的参数进行scaling非常重要!
(3) 对scaled后的训练数据进行训练
>> svm-train svmguide1.scale

其它结果数据暂且不管,但看迭代次数就可以看出只有原始数据直接训练的十分之一。
(4) 基于scaled后的测试数据再次预测
>> svm-predict svmguide1.t.scale svmguide1.scale.model svmguide1.t.predict

针对测试数据的分类准确性(Accuracy)从66.92%提升至96.15%!而且只用十分之一的迭代次数,“又要马儿不吃草,又要马儿跑的好”真的是可以做到的!由此可见对数据进行适当的scaling处理的重要性。
3.4 自动化的参数搜索
Libsvm还提供了自动进行grid搜索最优化参数的脚本:libsvm-master\tools\grid.py
关于grid search参见[1]-3.2 Cross-validation and Grid-search
输入命令如下所示:
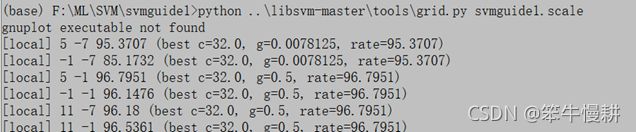
。。。。。。

真的太赞了!作者太亲民了!只不过如以上警告信息所示,我没有安装gnuplot,所以没有显式出炫目的图形化结果来,后面再来补充安装gnuplot(工具太多了对于我等渣渣们也是一件难事)。。。
另外,最后输出的三个数中,最后一个是Accuracy比较好猜,前面两个根据文档[1]应该分别是C和gamma,但是为什么我得到的结果与文档[1]中给出的结果不一致呢?有点方。。。
Anyway,先参照以上参数结果重新训练和预测:
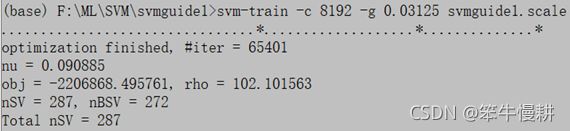
等等。。。好像有点不妙,迭代次数居然变为65401!为什么呢?
![]()
预测的Accuracy也比之前变低了,说明的确有些问题。
用文档[1]中提供的C=2.0, gamma=2.0重新新做训练和预测看看。
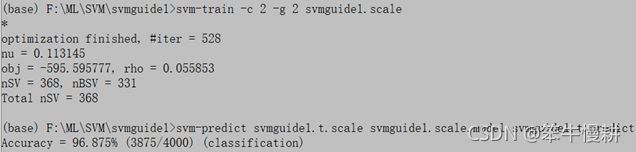
的确再现了[1]中的结果。那就是我的grid-search的执行那一步有问题。。。不知所措。。。
查了查万能的互联网,有人[2]指出了要进入到grid.py所在的目录去运行才能保证该脚本正常工作,试试看。呃,还是不行。难道是因为我没有安装gnuplot?
先不管了,继续往下走,看看全自动的全流程脚本的运行情况如何。
3.5 全流程自动化
先运行看看情况再说(仍然回到数据目录):

报错。。。嗯嗯,这个才回到了熟悉的场景了嘛,太顺利了都让人不相信是开源世界了^-^.
打开easy.py来看一下:

从以上这一段代码来看,确实是(如果不修改脚本的话)要求进入到工具所在的目录(虽然上一节表明进入到工具所在目录也并没有解决grid-search的问题)
3.5.1 gnuplot安装
Easy.py中也要调用gnuplot,看来躲不过,老老实实地从以下网站下载并安装:
https://sourceforge.net/projects/gnuplot/files/gnuplot/5.4.2/ gp542-win64-mingw.exe
需要注意的是,安装完后需要手动修改esay.py中的gnuplot_exe对应的路径(因为easy.py中的缺省的路径跟真正的安装路径可能不一样)

不过安装完了后看到:

暂时就这样将就一下吧。。。
3.5.2 运行easy.py
命令执行(需要几分钟的时间)状况如下:
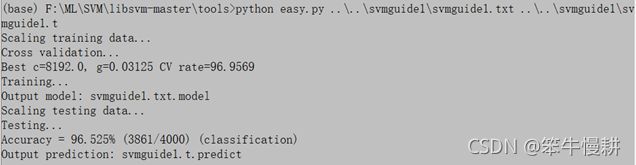
C和g的值与之前单独执行grid-search的结果是一样的。
自动过程中生成了一张图如下所示(这个应该就是gnuplot生成的):
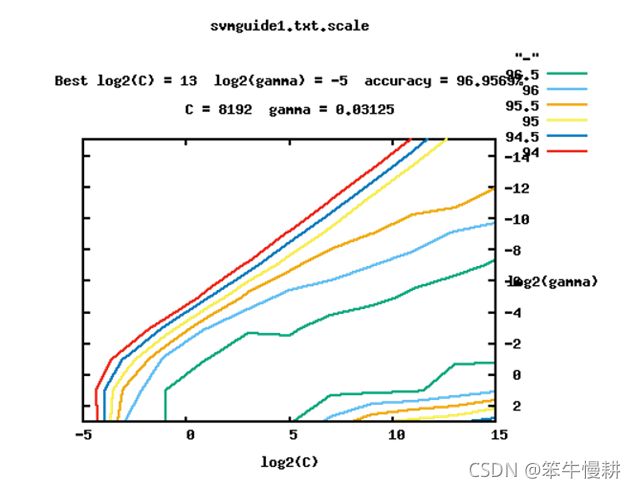
4. 小结
基本上正确安装并再现了[1]—A.1中的实验结果。
不够完美的是:grid-search所得到的C和gamma的最优值与文档中所说的不一致。需要进一步调查。
下一篇是进一步的针对UCI-SPECTF的实验以及相关联的数据转换,请参见:
LIBSVM使用实验兼数据转换--UCI-SPECTF https://blog.csdn.net/chenxy_bwave/article/details/120937943
https://blog.csdn.net/chenxy_bwave/article/details/120937943
Reference:
[1] Chih-Wei Hsu, et al, A Practical Guide to Support Vector Classification
[2] http://www.solomonson.com/posts/2011-01-29-getting-started-libsvm/