Nacos源码系列——第三章(全网最经典的Nacos集群源码主线剖析)
上两个章节讲述了Nacos在单机模式下的服务注册,发现等源码剖析过程,实战当中
其实单机是远远不够的,那么Nacos是如何在集群模式下是如何保证节点状态同步,以及服
务变动,新增数据同步的过程的!
重要几个点:
1、Nacos心跳在集群架构下的设计原理剖析
2、Nacos集群节点+服务状态同步源码剖析
3、Nacos集群服务新增数据同步源码剖析
4、Nacos集群节点增加后数据同步源码剖析
1、集群环境下如何进行本地调试
单机版本我在前面的章节已经讲述如何部署,那么集群条件下按照以下步骤
需要先配置mysql存储,在mysql里新建一个库,我这边命名nacos_config
选中nacos源码的distribution/conf下的sql脚本,在刚创建的数据库执行下即可!
然后修改console模块下的application.properties的mysql配置
因为我这里模拟三台,所以我需要在我的磁盘上建立三个文件夹
D:\nacos-cluster\nacos-8847\conf
D:\nacos-cluster\nacos-8848\conf
D:\nacos-cluster\nacos-8849\conf,里面放cluster.conf。
cluster.conf里配置本机ip加三个端口模拟三台集群
192.168.1.9:8847 192.168.1.9:8848 192.168.1.9:8849Idea做三个主启动类分别加上参数
-Dserver.port=8847 -Dnacos.home=D:\nacos-cluster\nacos-8847
准备好后我们启动三台完毕
随便访问一台试试
到这我们源码模拟集群搭建过程就完成!
2、Nacos心跳在集群架构下的设计原理剖析
前面我们已经讲述过单机下的心跳机制,Nacos Server端会开启一个定时心跳检查任务,来保证某个服务的健康状态的检查;你想下如果在集群下,会采用每个Nacos都开启定时对每个服务做心跳检查吗?如果都开启的话,那么心跳之间要相互的同步数据,保证大家的信息都是基本一致,一旦集群数量越多,那么这个成本是不是越高,两两同步,甚至更多,所以Nacos在集群环境下并非这样设计,而是只在一台对当前的服务上定时心跳检查,有任何变动,通知其他节点即可!
在ClientBeatCheckTask里,如果你问我怎么找到的,看看我前面的章节就可以了。
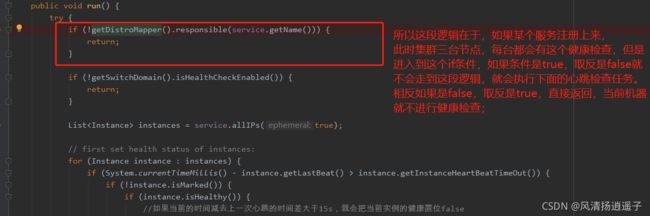
在这个run里面之前我有讲过下面的检查逻辑,而上面的逻辑我是跳过的。
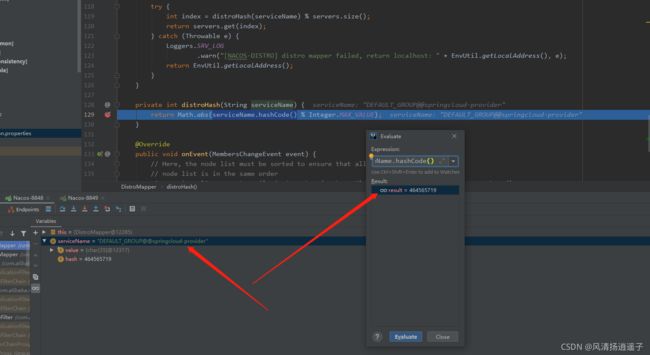
进入responsible方法,大概的浏览下,前面的判断先过去,重点一看就有一个distroHash这个方法;
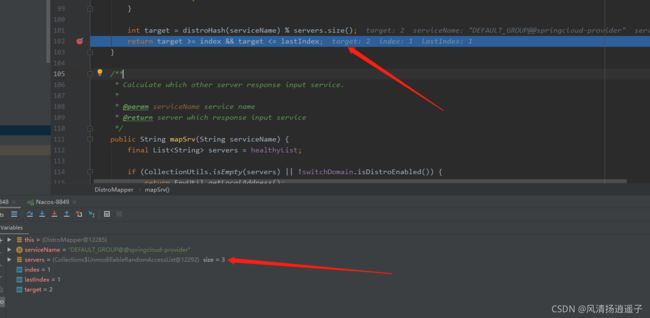
进入distroHash里面,逻辑是服务名取hashCode的值对Integer的最大值取余
我们可以debug看下这个值是多少
server有三台,所以这个target的值是2,在第三台上
每一台机器都会走这段逻辑,这段我举个例子:
假设有三台:192.168.1.9:8847 192.168.1.9:8848 192.168.1.9:8849
server[0]:192.168.1.9:8847
server[1]:192.168.1.9:8848
server[2]:192.168.1.9:8849
有个服务注册上来了,每个服务端会维护一个servers,里面存放上面三个IP+Port,此时第一台8847开始执行心跳检查,进入responsiable方法,判断当前的ip在不在这个List里,如果在,返回当前的index索引,这个index范围在[0-2],再判断最后出现的索引的地方,如果当前IP已经不在servers中,直接返回true,取非就是false,那么当前节点就做这个服务的健康检查(这点不理解为什么),如果当前IP在这个servers中,开始对服务进行取模到一台上,返回
target >= index && target <= lastIndex其实在我看来index和lastIndex值是一样的,因为ip和端口正常来说不会重复出现在list。里,所以这块我不理解为什么要多判断一次,target值一定也是[0-2]之间,所以如果index=1,target=2,这个判断就是false,取反就是true,当前节点不做该服务的健康检查,因为index=1说明当前节点是8848这台,而target表示落点在server[2]上,说明到server[2]这台上,该服务做健康检查,其他节点,该服务不做健康检查直接return掉了,每次相同的服务只定位到那台机器上做健康检查任务。
所以说到这里,原理就已经大概清楚了。
那么问题就来了,如果三台有一台挂了呢?那取模不就有问题了?
接着往下看,有个ServerListManager.init方法,我也是在之前看到了有个类GlobalExcutor里面全是scheduled定时任务才知道在这里,当然我也猜到了集群中的节点同步,通常肯定是放在定时任务里的;于是才找到这个init方法。
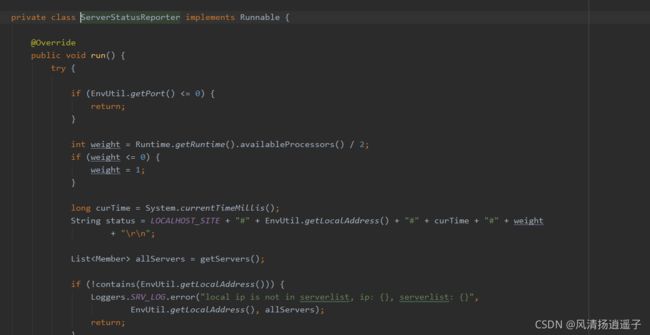
这里有个registerServerStatusReporter,存在一个参数ServerStatusReporter,是个线程。
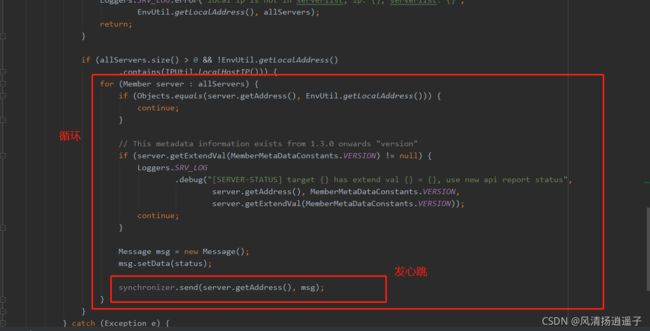
搞个for循环后,给所有服务节点发送个心跳
然后调用的是url的一个接口,每台机器都会提供一个状态的接口,/operator/servers/status,实际上每台机器都会调用其他两台机器的这个接口告诉他我还活着,那么如果当前机器死了,另外两台机器就收不到该机器的心跳了,默认就会把自己的serverlist这三台机器更新成2台,所以刚刚的hash运算即便服务挂了也不会出现问题。
那么心跳在集群模式下的设计原理和心跳状态同步机制就讲到这。
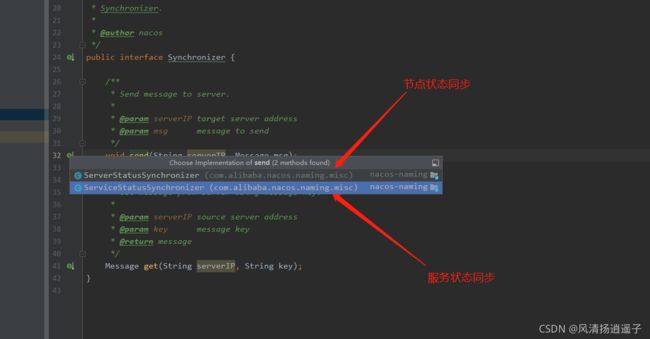
3、Nacos集群节点+服务状态同步源码剖析
那么光有心跳不行啊,如果某个服务不健康了,或者要被踢下线了,这几台服务之间是如何感知的呢?
我是通过刚刚的send方法,发现了另一个实现ServiceStatusSynchronizer,见明知意是服务状态同步器,然后看看哪里调用send方法,最后发现是在ServiceManager.init里进行的调用。
在ServiceManager类里有个私有类ServiceReporter也是个线程,debug看下里面是发送的什么信息,实际上发送到其他节点,告诉他到底该服务咋了,是不健康了,还是要剔除。
那主线就到这结束,如果感兴趣可以自行深入往下研究。
4、Nacos集群服务新增数据同步源码剖析
如果我们有一台新的节点注册上去,那么集群之间是怎么进行新增数据同步的呢?
这个类在前面章节讲过
DistroConsistencyServiceImpl.put方法有个distroProtocol.sync
里面搞了个for循环,allMembersWithoutSelf 如果是单机,这就是空的,for循环就结束了,但是集群的话,拿到除开自己的其他节点
这段代码讲实话我看了很久,绕的一批,不知道写这个为啥要这样吗,我大概说下,里面做了distroKeyWithTarget是除开自己的机器,把当前的distorKey和目标机器封装起来,然后添加到一个任务去执行;
这里又很类似一个异步套路,既然往里去put,就一定有地方去get
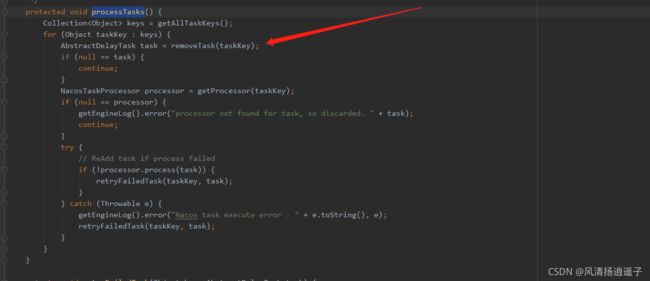
下面有一个方法processTasks执行队列的任务,首先把任务移出来。
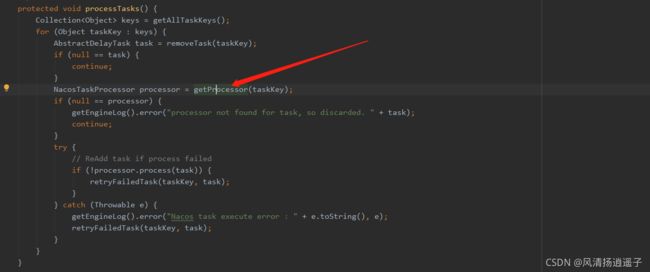
移出来的任务判断当前这个任务是不是为空或者应该被执行,如果不是,就直接移出来返回当前的任务对象AbstractDelayTask,继续往下看调用getProcessor(taskKey)
然后看下try的processor.process(task),关键在于
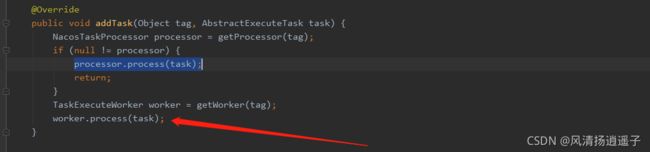
distroTaskEngineHolder.getExecuteWorkersManager().addTask(distroKey, syncChangeTask);这个方法
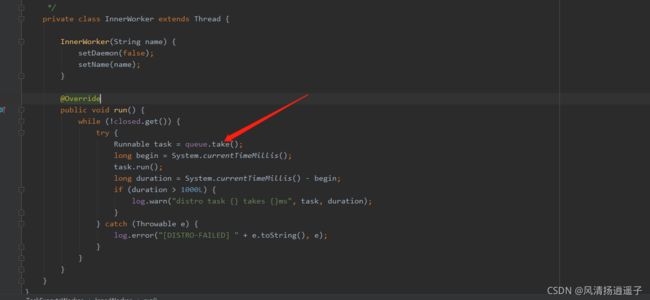
往里看走到了worker.process(task)
最终放到一个阻塞queue队列里
既然有put就有take,通常会在当前的类中TaskExecuteWorker,执行task.run方法
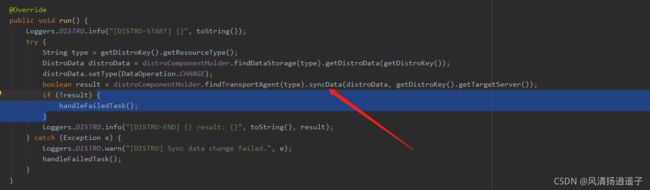
我这里直接debug下去的,进入到DistroSyncChangeTask.run方法
然后进入syncData里面,这里也有个syncData方法
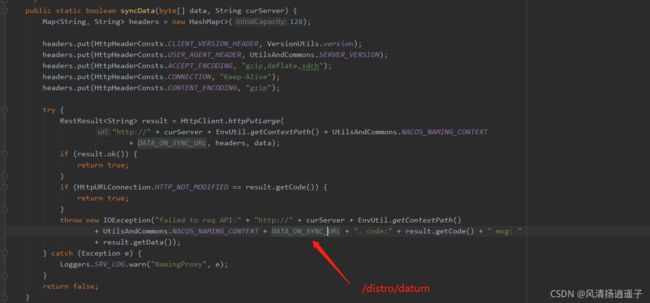
最终进入到真正的同步api里,把数据同步到其他节点上。
所以说这段代码太绕了,不知道搞这么多异步队列做什么,当然我不是源码开发的人,只是站在一个角度看不明白而已哈哈。
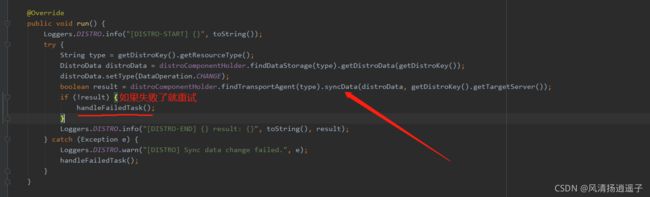
那么如果同步数据失败了就重试。
5、Nacos集群节点增加后数据同步源码剖析
那么如果这个时候我新加了节点进来,这个数据又是如何同步到新的节点上多呢?
这个我也找了半天,刚刚上一节描述了节点之间的数据同步的源码后发现到的
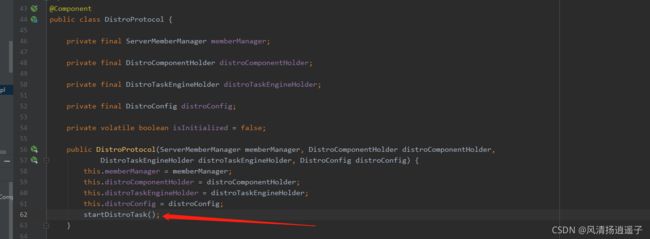
还是和同步syncData一样的类DistroProtocol构造方法有个startDistroTask()
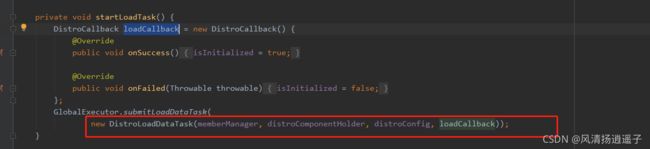
开启一个加载数据的任务
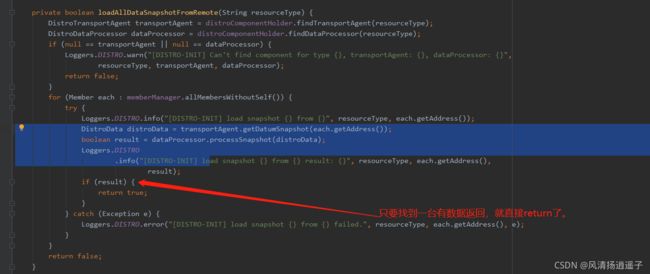
这个Task又是一个线程,看run方法
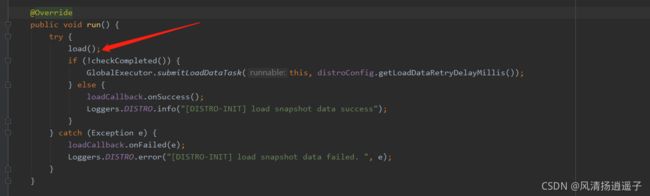
进入load方法,里面会去加载远端机器的数据,存到一个map里
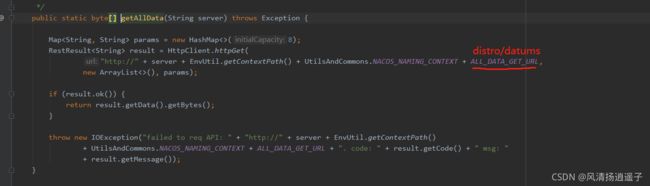
再进去看看,走到getDatumSnapshot(each.getAddress())
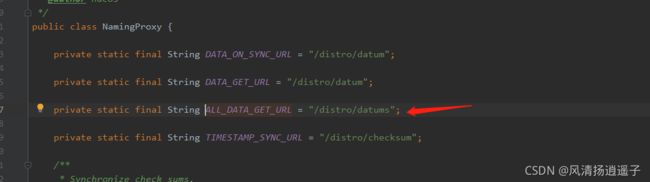
又调用了这个NamingProxy,老眼熟了,里面就是http接口方法。
看下参数
最终还是走到了http的接口上调用其他服务的方法,通过HttpClient拉取数据到自己的服务上。
这里要注意下,新加进来的机器不是每个机器都去找,它只会找一个机器去同步。
这个会不会出现有段时间节点之间数据不一致的问题啊,当然会有,ap架构下的Nacos集群就会有这样的问题,但是ap架构是最终一致性的,这个关系其实不大,找不到再去其他节点上找就是了。如果你想保证数据的强一致性,那就用到cp架构,后面我再更新。
所以最终你把整体的架构把握了就可以,真正遇到问题的时候,再去追踪细节。
喜欢的话一键三连吧!!哈哈