Python操作四大主流数据库:SQLite+MySQL+MongoDB+Redis
目录
- 1. Python操作 SQLite 数据库
-
- 1.1 项目实战:抓取豆瓣电影排行榜
- 2. Python操作 MySQL 数据库
-
- 2.1 PyMysql 模块
- 2.2 ORM 框架
-
- 2.2.1 连接数据库
- 2.2.2 创建数据表
- 2.2.3 添加数据
- 2.2.4 更新数据
- 2.2.5 查询数据
- 2.3 ORM爬虫实战一:爬取51Job招聘信息
- 3. Python操作 MongoDB 数据库
-
- 3.1 MongoDB 介绍
- 3.2 MongoDB 可视化工具
- 3.3 PyMongo 的安装
- 3.4 连接 MongoDB 数据库
- 3.5 添加文档
- 3.6 更新文档
- 3.7 查询文档
- 3.8 删除文档
- 3.9 MongoDB ODM
- 4. Python操作 Redis 数据库
1. Python操作 SQLite 数据库
SQLite 是一个开源、小巧、零配置的关系型数据库,支持多种平台,包括 Windows、Mac OS X、Linux、Android、iOS 等,现在运行 Android、iOS 等系统的设备基本都使用 SQLite 数据库作为本地存储方案。尽管 Python 语言在很多场景用于开发服务端应用,使用的是网络关系型数据库或 NoSQL 数据库,但有一些数据是需要保存到本地的,虽然可以用 XML、JSON 等格式保存这些数据,但对数据检索很不方便,因此将数据保存到 SQLite 数据库中,是本地存储的最佳方案。读者可以通过 点击此处 访问 SQLite 官网。
SQLite 数据库的管理工具很多,SQLite 官方提供了一个命令行工具用于管理 SQLite 数据库,不过这个命令行工具需要输入大量的命令才能操作 SQLite 数据库,并不建议使用。因此,本节将介绍一款跨平台的 SQLite 数据库管理工具 DB Browser for SQLite,这是一款免费开源的 SQLite 数据库管理工具。读者可以通过 点击此处 访问官网。进入 DB Browser for SQLite 官网后,选择对应的版本下载即可,如下图所示:
如果读者想要 DB Browser for SQLite 的源代码,请到 github 上下载,地址如下:
https://github.com/sqlitebrowser/sqlitebrowser
安装好 DB Browser for SQLite 后,直接启动即可看到如下图所示的主界面。
DB Browser for SQLite 在操作上非常简便,读者只要稍加摸索就可以掌握任何其他的功能,因此,本节不再深入探讨 DB Browser for SQLite 的其他功能,后续部分会将主要精力放到 Python 语言上来。
通过 sqlite3 模块提供的函数可以操作 SQLite 数据库,sqlite3 模块是 Python 语言内置的,不需要安装,直接导入该模块即可。sqlite3 模块提供的丰富函数可以对 SQLite 数据库进行各种操作,不过在对数据进行增、删、改、查以及其他操作之前,先要使用 connect() 函数打开 SQLite 数据库,通过该函数的参数指定 SQLite 数据库的文件名。打开数据库后,通过 cursor 方法获取 sqlite3.Cursor 对象,然后通过 sqlite3.Cursor 对象的 execute 方法执行各种 SQL 语句,如创建表、创建视图、删除记录、插入记录、查询记录等。如果执行的是查询 SQL 语句 (SELECT 语句),那么 execute 方法会返回 sqlite3.Cursor 对象,需要对该对象进行迭代,才能获取查询结果的值。
本例使用 connect 函数在当前目录创建一个名为 data.sqlite 的 SQLite 数据库,并在该数据库中建立一个 persons 表,然后插入若干条记录,最后查询 persons 表的所有记录,并将查询结果输出到控制台。示例代码如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:1. 用Python 操作 SQLite 数据库.py
@time:2020/11/22
"""
import sqlite3
import os
import json
dbPath = "data.sqlite"
# 只有data.sqlite文件不存在时才创建该文件
if not os.path.exists(dbPath):
# 创建 SQLite数据库
conn = sqlite3.connect(dbPath)
# 获取 sqlite3.Cursor 对象
cursor = conn.cursor()
# 创建 Persons 表
cursor.execute("""CREATE TABLE persons
(id INT PRIMARY KEY NOT NULL,
name TEXT NOT NULL,
age INT NOT NULL,
address CHAR(50),
salary REAL);
""")
# 关闭游标
cursor.close()
# 修改数据库后必须调用 commit 方法提交才能生效
conn.commit()
# 关闭数据库连接
conn.close()
print("创建数据库成功")
conn = sqlite3.connect(dbPath)
c = conn.cursor()
# 删除 persons 表中的所有数据
c.execute("delete from persons;")
# 下面的 4 条语句向 persons表中插入4条记录
c.execute("INSERT INTO persons(id,name,age,address,salary) VALUES(1,'Paul',32,'Californis',20000.00)")
c.execute("INSERT INTO persons(id,name,age,address,salary) VALUES(2,'Allen',25,'Texas',15000.00)")
c.execute("INSERT INTO persons(id,name,age,address,salary) VALUES(3,'Teddy',23,'Norway',20000.00)")
c.execute("INSERT INTO persons(id,name,age,address,salary) VALUES(4,'Amo',25,'Rich-Mond',65000.00)")
# 必须提交才能生效
conn.commit() # 提交事务
print("插入数据成功")
# 查询 persons 表中的所有记录,并按age升序排列
persons = c.execute("SELECT name,age,address,salary from persons order by age")
print(type(persons))
result = []
# 将sqlite3.Cursor 对象中的数据转换为列表形式
for person in persons:
value = {
}
value['name'] = person[0]
value['age'] = person[1]
value['address'] = person[2]
result.append(value)
c.close()
conn.close()
print(type(result))
# 输出查询结果
print(result)
# 将查询结果转换为字符串形式,如果要将数据通过网络传输,就需要首先转换为字符串形式才能传输
resultStr = json.dumps(result)
print(type(resultStr))
print(resultStr)
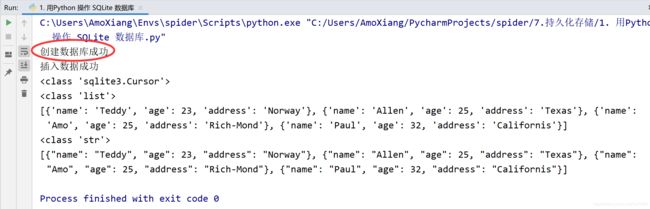
程序第 1 次运行的结果如下图所示:
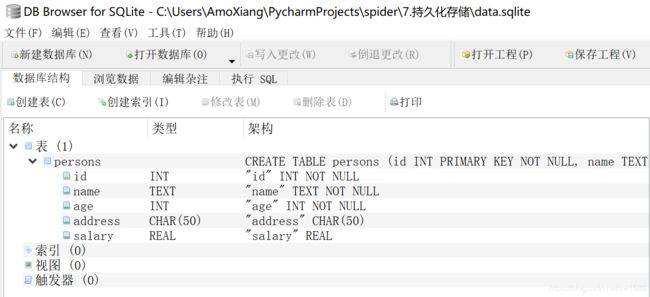
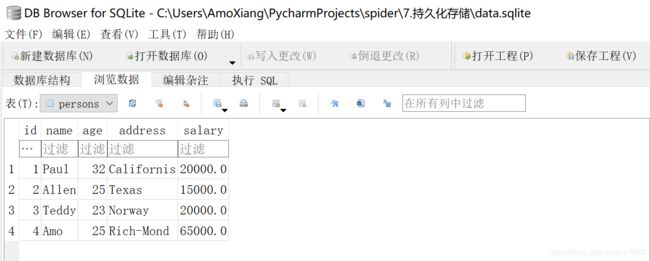
读者可以用 DB Browser for SQLite 打开 data.sqlite 文件,会看到 persons 表的结构如下图所示:
表数据如下图所示:
1.1 项目实战:抓取豆瓣电影排行榜
本节的例子使用 requests 下载豆瓣电影 Top250 排行榜页面的代码,然后使用 lxml、XPath、和 正则表达式对 HTML 代码进行解析,最后将抓取到的信息保存到 SQLite 数据库中。豆瓣电影 Top250 排行榜页面的 URL 如下:
https://movie.douban.com/top250
页面效果如下图所示:

豆瓣电影 Top250 排行榜页面 URL 的规律与音乐排行榜相同,如第 2 页、第 3 页的 URL 如下:
https://movie.douban.com/top250?start=25&filter=
https://movie.douban.com/top250?start=50&filter=
获取豆瓣电影信息的方式与获取豆瓣音乐的方式类似,HTML 代码的结构也类似,只是略有差别。例如:首页获取所有电影 URL 的 XPath 代码如下:
//div[@class="hd"]/a/@href
现在进入电影页面,如下图所示:

本例需要抓取的所有电影信息都在这个页面中。下面是本例要抓取的全部信息:电影名 (name)、导演 (director)、主演 (actor)、类型 (style)、制片国家 (country)、上映时间 (release_time)、片长 (time)、豆瓣评分 (score)。本例提供完整的代码来演示如何抓取豆瓣电影 Top250 排行榜,包括使用 lxml、Xpath 和 正则表达式分析 HTML 代码,以及将提取的数据保存到 SQLite 数据库中。示例代码如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:3.项目实战:抓取豆瓣电影排行榜.py
@time:2020/11/23
"""
import requests
from lxml import etree
import re
import sqlite3
import os
import time
from fake_useragent import UserAgent
# 定义请求头
ua = UserAgent()
def get_headers():
headers = {
"User-Agent": ua.random,
"Referer": "https://accounts.douban.com/",
'Cookie': 'bid=5VxlZD0Dfhc; douban-fav-remind=1; _vwo_uuid_v2=D26DFA41AB507F486C0D7AE551F2CE745|2ca45cb4415f3efa83e1ccdaf25613d0; __utmv=30149280.19182; __utmz=223695111.1602661353.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __yadk_uid=NA6alz7JSTUhzIUHeUXlbsRsQnIrynjp; ll="118172"; gr_user_id=1ed7baa3-e27a-453a-b8db-e37da838c9bc; viewed="1007305_1402531_2995812_3040149"; __gads=ID=8a456d3da7bbe7e1-22dff5828ac400f0:T=1604367514:RT=1604367514:S=ALNI_MZBCS_q_PIsHaoiuW0G1r0fLXkiqw; __utmz=30149280.1605680269.9.5.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmc=30149280; __utmc=223695111; ap_v=0,6.0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1606140584%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DibMwTF6DDPjB3eIq0erwXxZfKRlm-2Grt0Te-BtNwxm_ADGTSco1SnjkZJ5f05vu%26wd%3D%26eqid%3D9064ee4e0001e112000000065f86abe7%22%5D; _pk_ses.100001.4cf6=*; __utma=30149280.479960211.1599478905.1606137821.1606140584.13; __utmt_douban=1; __utma=223695111.197427775.1602661353.1606137821.1606140584.9; __utmb=223695111.0.10.1606140584; dbcl2="191821802:QQlqaha1Ph8"; ck=7L-z; push_noty_num=0; push_doumail_num=0; __utmb=30149280.3.10.1606140584; _pk_id.100001.4cf6=a7fd2471c3f37935.1602661353.9.1606140631.1606138405.'
}
return headers
# 抓取豆瓣电影Top250榜单的页面,并提取电影页面的URL
def get_movie_url(url):
response = requests.get(url=url, headers=get_headers())
selector = etree.HTML(response.text)
# 使用Xpath提取当前页面中所有的电影页面URL
movie_hrefs = selector.xpath('//div[@class="hd"]/a/@href')
print(movie_hrefs)
for movie_href in movie_hrefs:
# 处理每一个电影页面
get_movie_info(movie_href)
# 抓取URL指定的电影页面,并提取前面描述的几个与电影有关的信息
def get_movie_info(href):
global m_id
response = requests.get(url=href, headers=get_headers())
selector = etree.HTML(response.text)
try:
# 提取电影名称
name = selector.xpath("//h1/span[1]/text()")[0]
# 提取导演
director = " / ".join(selector.xpath('//div[@id="info"]/span[1]/span[2]/a/text()'))
actors = selector.xpath('//div[@id="info"]/span[3]/span[2]')[0]
# 提取主演
actor = actors.xpath("string(.)")
# 提取类型
style = " / ".join(re.findall(r'(.*?)', response.text, re.S))
# 提取制片国家
country = "".join(re.findall(r'制片国家/地区: (.*?)
', response.text, re.S))
# 提取上映时间
release_time = "/".join(re.findall(r'(.*?)',
response.text, re.S))
# 提取片长
movie_time = re.findall(r'片长: (.*?)
',
response.text, re.S)[0]
print(movie_time)
# 提取豆瓣评分
# score = selector.xpath('//div[@id="interest_sectl"]/div[1]/div[2]/strong/text()')[0]
score = re.search(r'"ratingValue": "(.*?)"', response.text).group(1)
print(score)
m_id += 1 # 数据库记录的索引
# 要保存到SQLite数据库中的记录
movie = (m_id, str(name), str(director), str(actor), str(style), str(country),
str(release_time), str(movie_time), score)
print(movie)
# 将当前电影的信息保存到数据库中
cursor.execute(
"INSERT INTO movies(id,name,director,actor,style,country,release_time,time,score) values(?,?,?,?,?,?,?,?,?)",
movie)
# 必须提交,才能将数据保存到SQLite数据库中
conn.commit()
except Exception as e:
# print(e)
print(m_id)
pass
if __name__ == '__main__':
# get_movie_info("https://movie.douban.com/subject/1301753/") 测试
m_id = 0 # 数据库记录的索引
dbPath = "movie.sqlite"
if os.path.exists(dbPath):
os.remove(dbPath)
# 创建SQLite数据库
conn = sqlite3.connect(dbPath)
# 获取sqlite3.Cursor对象
cursor = conn.cursor()
# 创建movies表
cursor.execute("""CREATE TABLE movies(
id INT NOT NULL,
name CHAR(50) NOT NULL,
director CHAR(50) NOT NULL,
actor CHAR(50) NOT NULL,
style CHAR(50) NOT NULL,
country CHAR(50) NOT NULL,
release_time CHAR(50) NOT NULL,
time CHAR(50) NOT NULL,
score REAL(50) NOT NULL);
""")
# 提交后,才会创建 movies表
conn.commit()
print("创建movies表成功")
# 产生10个电影榜单页面的URL
urls = ["https://movie.douban.com/top250?start={}&filter=".format(i) for i in range(0, 250, 25)]
# 处理每一个榜单页面
for url in urls:
get_movie_url(url)
time.sleep(1)
# 关闭游标及数据库
cursor.close()
conn.close()
运行结果如下图所示:

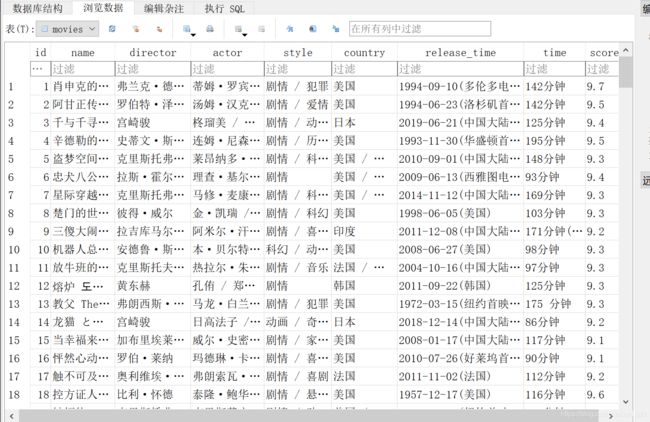
运行程序后,会在当前目录生成一个名为 movies.sqlite 的数据库文件,读者可以用 DB Browser for SQLite 打开这个数据库文件,效果如下图所示:
如果抓取的数据量比较大,而且需要后期整理和查询,建议保存到数据库中。至于保存到什么类型的数据库,这个需要根据业务需求决定。例如,抓取的数据只用于用户自己分析和实验,可以保存到 SQLite 数据库中,因为这种数据库功能较强,而且不需要安装,使用十分方便。如果抓取的数据需要让多人访问和分析,可以考虑 MySQL 数据库。当然,如果抓取到的数据很难整理成二维表的形式或懒得整理,也可以考虑像 MongoDB 这样的文档数据库。
2. Python操作 MySQL 数据库
2.1 PyMysql 模块
更加详细的用法以及案例可以点击博主的 Python每日一练(11)-爬取在线课程 一文进行学习。MySQL 是一个功能强大的网络关系型数据库,支持通过网络多人同时连接和操作数据库,目前国内外有很多网站的后台都是使用 MySQL 数据库,这里关于 MySQL 数据库的安装及配置就不再赘述,MySQL 是常用的关系型数据库,现在很多互联网都使用了 MySQL 数据库。在 Python 语言中需要使用 pymysql 模块来操作 MySQL 数据库。如果读者使用的是 Anaconda 的 Python 环境,需要使用下面的命令安装 pymysql 模块。
conda install pymysql
如果读者使用的是标准的 Python 环境,需要使用 pip 命令安装 pymysql 模块。
pip install pymysql
pymysql 模块提供的 API 与 sqlite3 模块提供的 API 类似,因为它们都遵循 Python DB API 2.0 标准,下面的页面是该标准的完整描述。
https://www.python.org/dev/peps/pep-0249/
其实读者也不必详细研究 Python DB API 规范,只需记住几个函数和方法,绝大多数的数据库的操作就可以搞定了。
(1) connect 函数:连接数据库,根据连接的数据库类型不同,该函数的参数也不同。connect 函数返回 Connection 对象。
(2) cursor 方法:获取操作数据库的 Cursor 对象。cursor 方法属于 Connection 对象。
(3) execute 方法:用于执行 SQL 语句,该方法属于 Cursor 对象。
(4) commit 方法:在修改数据库后,需要调用该方法提交对数据库的修改,commit 方法属于 Cursor 对象。
(5) rollback 方法:如果修改数据库失败,一般需要调用该方法进行数据库回滚,也就是将数据库恢复成修改之前的样子。
本例通过调用 pymysql 模块中的相应 API 对 MySQL 数据库进行增、删、改、查操作。示例代码如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:2.在Python中使用MySQL.py
@time:2020/11/22
"""
from pymysql import *
import json
# 打开 MySQL 数据库,其中127.0.0.1是MySQL服务器的IP,root是用户名,mysql是秘密
# test 是数据库名
def connect_db():
db = connect("127.0.0.1", "root", "mysql", "test", charset="utf8")
return db
db = connect_db()
# 创建 persons表
def create_table(db):
# 获取 Cursor对象
cursor = db.cursor()
sql = """CREATE TABLE persons
(id INT PRIMARY KEY NOT NULL,
name TEXT NOT NULL,
age INT NOT NULL,
address CHAR(50),
salary REAL);
"""
try:
# 执行创建表的SQL语句
cursor.execute(sql)
cursor.close()
# 提交到数据库执行
db.commit()
return True
except:
# 如果发生错误则回滚
db.rollback()
return False
# 向persons表插入4条数据
def insert_records(db):
cursor = db.cursor()
try:
# 首先将以前插入的记录全部删除
cursor.execute("DELETE FROM persons;")
# 下面的几条语句向 persons表中插入4条记录
cursor.execute("INSERT INTO persons(id,name,age,address,salary) VALUES(1,'Paul',32,'Californis',20000.00)")
cursor.execute("INSERT INTO persons(id,name,age,address,salary) VALUES(2,'Allen',25,'Texas',15000.00)")
cursor.execute("INSERT INTO persons(id,name,age,address,salary) VALUES(3,'Teddy',23,'Norway',20000.00)")
cursor.execute("INSERT INTO persons(id,name,age,address,salary) VALUES(4,'Amo',25,'Rich-Mond',65000.00)")
# 提交到数据库执行
cursor.close()
db.commit()
return True
except Exception as e:
print(e)
# 如果发生错误则回滚
db.rollback()
return False
# 查询 persons表中全部的记录,并按age字段降序排列
def select_records(db):
cursor = db.cursor()
sql = "SELECT name,age,salary FROM persons ORDER BY age DESC;"
cursor.execute(sql)
# 调用fetchall()方法获取全部的记录
results = cursor.fetchall()
# 输出查询结果
print(results)
# 下面的代码将查询结果重新组织成其他形式
fields = ["name", "age", "salary"]
records = []
for row in results:
records.append(dict(zip(fields, row)))
cursor.close()
return json.dumps(records)
if create_table(db):
print("成功创建persons表")
else:
print("persons 表已经存在")
if insert_records(db):
print("成功插入记录")
else:
print("插入记录失败")
print(select_records(db))
db.close()
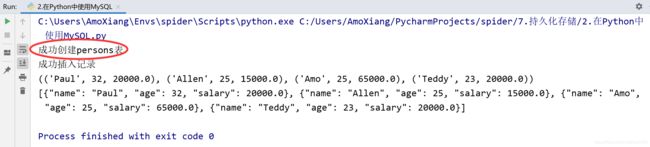
程序运行结果如下图所示:
前面的代码使用了名为 test 的数据库,所以在运行这段代码之前,要保证有一个名为 test 的 MySQL 数据库,并确保已经开启 MySQL 服务。

从前面的代码和输出结果可以看出,操作 MySQL 和 SQLite 的 API 基本是一样的,只是有如下两点区别:
(1)用Cursor.execute 方法查询 SQLite 数据库时会直接返回查询结果,而使用该方法查询 MySQL 数据库时返回了None,需要调用 Cursor.fetchall 方法才能返回查询结果。
(2) Cursor.execute 方法返回的查询结果和 Cursor.fetchall 方法返回的查询结果的样式是不同的,这一点从输出结果就可以看出来。如果想让 MySQL 的查询结果与 SQLite 的查询结果相同,需要使用 zip函数 和 dict函数 进行转换。更加详细的用法以及案例可以点击博主的 Python每日一练(11)-爬取在线课程 一文进行学习。
2.2 ORM 框架
开发人员经常接触的关系型数据库主要有MySQL、Oracle、SQL Server、SQLite 和 PostgreSQL,操作数据库的方法大致有以下两种:
(1) 直接使用数据库接口连接。在 Python 的关系数据库连接模块中,分别有pymysql、cx_Oracle、pymssql、sqlite3 和 psycopg2。通常,这类数据库的操作步骤都是连接数据库、执行 SQL 语句、提交事务、关闭数据库连接。每次操作都需要 Open/Close Connection,如此频繁地操作对于整个系统无疑是一种浪费。对于一个企业级的应用来说,这无疑是不科学的开发方式。
(2) 通过ORM (Object/Relation Mapping,对象-关系映射) 框架来操作数据库。这是随着面向对象软件开发方法的发展而产生的,面向对象的开发方法是当今企业级应用开发环境中的主流开发方法,关系数据库是企业级应用环境中永久存放数据的主流数据存储系统。对象和关系数据是业务实体的两种表现形式,业务实体在内存中表现为对象,在数据库中表现为关系数据。内存中的对象之间存在关联和继承关系,而在数据库中,关系数据无法直接表达多对多关联和继承关系。因此,ORM 系统一般以中间件的形式存在,主要实现程序对象到关系数据库数据的映射。
常用的 ORM框架 模块有 SQLObject、Stom、Django的 ORM、peewee 和 SQLAlchemy。博文主要讲述 Python 的 ORM 框架 ⇒ SQLAlchemy。SQLAlchemy是 Python 编程语言下的一款开源软件,提供 SQL 工具包及对象(关系映射工具),使用 MIT 许可证发行。
SQLAlchemy 采用简单的 Python 语言,为高效和高性能的数据库访问设计,实现了完整的企业级持久模型。SQLAlchemy 的理念是,SQL 数据库的量级和性能重要于对象集,而对象集合的抽象又重要于表和行。因此,SQLAlchmey 采用类似 Java 里 Hibernate 的数据映射模型,而不是其他 ORM 框架采用的 Active Record 模型。不过,Elixir 和 declarative 等可选插件可以让用户使用声明语法。
SQLAlchemy 首次发行于2006年2月,是 Python 社区中被广泛使用的 ORM 工具之一,不亚于 Django 的 ORM 框架。SQLAlchemy 在构建于 WSGI 规范的下一代 Python Web 框架中得到了广泛应用,是由 Mike Bayer 及其开发团队开发的一个单独的项目。使用 SQLAlchemy 等独立 ORM 的一个优势就是允许开发人员首先考虑数据模型,并能决定稍后可视化数据的方式 (采用命令行工具、Web框架还是GUI框架)。这与先决定使用 Web框架或GUI框架,再决定如何在框架允许的范围内使用数据模型的开发方法极为不同。SQLAlchemy 的一个目标是提供能兼容众多数据库 (如SQLite、MySQL、Postgres、Oracle、MS-SQL、SQLServer 和 Firebird) 的企业级持久性模型。安装 SQLAlchemy 时,建议直接使用 pip 安装,命令如下:
pip install SQLAlchemy
使用 SQLAlchemy 连接数据库实质上还是通过数据库接口实现连接,安装 SQLAlchemy 后还需要安装对应数据库的接口模块,下面以 MySQL 为例安装 pymysql 模块:
pip install pymysql
完成安装后,打开 CMD 窗口,通过导入模块测试是否安装成功:
2.2.1 连接数据库
SQLAlchemy 连接数据库使用数据库连接池技术,原理是在系统初始化的时候,将数据库连接作为对象存储在内存中,当用户需要访问数据库时,并非建立一个新的连接,而是从连接池中取出一个已建立的空闲连接对象。使用完毕后,用户也并非将连接关闭,而是将连接放回连接池中,以供下一个请求访问使用。而连接的建立、断开都由连接池自身来管理。同时,还可以通过设置连接池的参数来控制连接池中的初始连接数、连接的上下限数以及每个连接的最大使用次数、最大空闲时间等。也可以通过其自身的管理机制来监视数据库连接的数量、使用情况等。通过了解 SQLAlchemy 的原理有利于理解 SQLAlchemy 连接数据库的代码,代码如下:
from sqlalchemy import create_engine
engine = create_engine("mysql+pymysql://root:mysql@localhost:3306/test?charset=utf8", echo=True,
pool_size=5, pool_timeout=30, max_overflow=4, pool_recycle=7200)
(1) mysql+pymysql://root:mysql@localhost:3306/test?charset=utf8:mysql 指明数据库系统类型,pymysql 是连接数据库接口的模块,root 是数据库系统用户名,mysql 是数据库系统密码,localhost:3306 是本地的数据库系统和数据库端口,test 是数据库名称,charset 指的是编码。
(2) echo=True:用于显示 SQLAlchemy 在操作数据库时所执行的 SQL 语句情况,相当于一个监视器,可以清楚知道执行情况,如果设置为 False,就可以关闭。
(3) pool_size:设置连接数,默认设置5个连接数,连接数可以根据实际情况进调整,在一般的爬虫开发中,使用默认值已足够。
(4) max_overflow:默认连接数为10。当超出最大连接数后,如果超出的连接数在 max_overflow 设置的访问内,超出的部分还可以继续连接访问,在使用过后,这部分连接不放在 pool (连接池) 中,而是被真正关闭。
(5) pool_recycle :连接重置周期,默认为-1,推荐设置为7200,即如果连接已空闲 7200 秒,就自动重新获取,以防止 connection 被关闭。
(6) pool_timeout:连接超时时间,默认为30秒,超过时间的连接都会连接失败。
(7) ?charset=utf8:对数据库进行编码设置,能对数据库进行中文读写,如果不设置,在进行数据添加、修改和更新等时,就会提示编码错误。上述代码只是给出连接 MySQL 的语句,其他数据的连接如下图所示:

2.2.2 创建数据表
完成数据库的连接后,可以通过 SQLAlchemy 对数据表进行创建和删除,使用 SQLAlchemy 创建数据表,代码如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:1.基本使用.py
@time:2020/11/01
"""
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, DateTime
from sqlalchemy import create_engine
engine = create_engine("mysql+pymysql://root:mysql@localhost:3306/test?charset=utf8", echo=True,
pool_size=5, pool_timeout=30, max_overflow=4, pool_recycle=7200)
Base = declarative_base()
# 第一种创建数据表的方式
class MyTable(Base):
# 表名
__tablename__ = "mytable"
# 字段,属性
id = Column(Integer, primary_key=True)
name = Column(String(50), unique=True)
age = Column(Integer)
birth = Column(DateTime)
class_name = Column(String(50))
# 创建数据表
Base.metadata.create_all(engine)
引入 declarative_base 模块,生成其对象 Base,再创建一个类 MyTable。一般情况下,数据表名和类名是一致的,__tablename__ 用于定义数据表的名称,可忽略,忽略时默认类名为数据表名。然后创建字段 id、name、age、birth、class_name。最后使用 Base.metadata.create_all(engine) 在数据库中创建对应的数据表。上述是比较常见的创建数据表的方法之一,还有一种创建方法类似 SQL 语句的创建方法:
from sqlalchemy import Column, MetaData, ForeignKey, Table
from sqlalchemy.dialects.mysql import (INTEGER, CHAR)
meta = MetaData()
my_class = Table("myclass", meta,
Column("id", INTEGER, primary_key=True),
Column("name", CHAR(50), ForeignKey(MyTable.name)),
Column("class_name", CHAR(50))
)
# 创建数据表
my_class.create(bind=engine)
总结: 第二种与第一种创建数据表的方法大有不同,代码比较偏向于SQL创建数据表的语法,两者引入的模块也各不相同,导致在创建数据表的时候,创建语法也不一致。不过两者实现的功能是一样的,读者可以根据自己的爱好进行选择。一般情况下,前者较有优势,在数据表已经存在的情况下,前者再创建数据表不会报错,后者就会提示已存在数据表的错误信息。若要删除数据表,则可用以下代码:
# 若要删除数据表
my_class.drop(bind=engine)
Base.metadata.drop_all(engine)
在删除数据表的时候,一定要先删除设有外键的数据表,也就是先删除 myclass 后才能删除 mytable,两者之间涉及外键,这是在数据库中删除数据表的规则。以下是完整的代码:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:2.第二种创建数据表的方式.py
@time:2020/11/01
"""
# 第一种表创建的导入方式
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, DateTime
# 第二种表创建的导入方式
from sqlalchemy import Column, MetaData, ForeignKey, Table
from sqlalchemy.dialects.mysql import (INTEGER, CHAR)
engine = create_engine("mysql+pymysql://root:mysql@localhost:3306/test?charset=utf8", echo=True,
pool_size=5, pool_timeout=30, max_overflow=4, pool_recycle=7200)
Base = declarative_base()
# 第一种创建数据表的方式
class MyTable(Base):
# 表名
__tablename__ = "mytable"
# 字段,属性
id = Column(Integer, primary_key=True)
name = Column(String(50), unique=True)
age = Column(Integer)
birth = Column(DateTime)
class_name = Column(String(50))
# 创建数据表
Base.metadata.create_all(engine)
meta = MetaData()
my_class = Table("myclass", meta,
Column("id", INTEGER, primary_key=True),
Column("name", CHAR(50), ForeignKey(MyTable.name)),
Column("class_name", CHAR(50))
)
# 创建数据表
my_class.create(bind=engine)
"""
总结:
第二种与第一种创建数据表的方法大有不同,代码比较偏向于SQL创建数据表的语法,两者引入的模
块也各不相同,导致在创建数据表的时候,创建语法也不一致。不过两者实现的功能是一样的,可以根据自己的
爱好进行选择。一般情况下,前者较有优势,在数据表已经存在的情况下,前者再创建数据表不会报错,
后者就会提示已存在数据表的错误信息。
"""
# 若要删除数据表
my_class.drop(bind=engine)
Base.metadata.drop_all(engine)
"""
在删除数据表的时候,一定要先删除设有外键的数据表,也就是先删除 myclass 后才能删除mytable,两者之
间涉及外键,这是在数据库中删除数据表的规则。
"""
无论数据表是否已经创建,在使用 SQLAlchemy 时一定要对数据表的属性、字段进行类定义。也就是说,无论通过什么方式创建数据表,在使用 SQLAlchemy 的时候,第一步是创建数据库连接,第二步是定义类来映射数据表,类的属性映射数据表的字段。
2.2.3 添加数据
完成数据表的创建后,下一步对数据表的数据进行操作。首先创建一个会话对象,用于执行 SQL 语句,代码如下:
from sqlalchemy.orm import sessionmaker
DBSession = sessionmaker(bind=engine)
session = DBSession()
引入 sessionmaker 模块,指明绑定已连接数据库的 engine 对象,生成会话对象 session,该对象用于数据库的增、删、改、查。一般来说,常用的数据库操作是增、改、查,SQLAlchemy 对这类操作有自身的语法支持。对上面代码中创建的数据表添加数据,代码如下:
new_data = MyTable(name="AmoXiang", age=18, birth="2000-5-20", class_name="一年级一班")
session.add(new_data)
session.commit()
session.close()
要使用 SQLAlchemy 添加数据,必须已经定义 mytable 对象,mytable 是映射数据库里面的 mytable 数据表。然后设置类属性 (字段) 对应的添加值,将数据绑定在 session 会话中,最后通过 session.commit() 来提交到数据库中,就完成对数据库的数据添加了。session.close()用于关闭会话,关闭会话不是必要规定,不过为了形成良好的编码规范,最好添加上。注意,如果关闭会话放在 session.commit() 之前,这个添加语句就是无效的,因为当前的 session 已经被关闭和销毁。所以在使用 session.close() 时,要注意编写的位置。完整代码:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:3.添加数据.py
@time:2020/11/01
"""
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, DateTime
engine = create_engine("mysql+pymysql://root:mysql@localhost:3306/test?charset=utf8", echo=True,
pool_size=5, pool_timeout=30, max_overflow=4, pool_recycle=7200)
Base = declarative_base()
DBSession = sessionmaker(bind=engine)
session = DBSession()
# 第一种创建数据表的方式
class MyTable(Base):
# 表名
__tablename__ = "mytable"
# 字段,属性
id = Column(Integer, primary_key=True)
name = Column(String(50), unique=True)
age = Column(Integer)
birth = Column(DateTime)
class_name = Column(String(50))
Base.metadata.create_all(engine)
# new_data = MyTable(name="AmoXiang", age=18, birth="2000-5-20", class_name="一年级一班")
# session.add(new_data)
new_data = MyTable(name="Li Lei", age=18, birth="2000-5-20", class_name="一年级一班")
session.add(new_data)
new_data = MyTable(name="AmoXiang", age=18, birth="2000-5-20", class_name="一年级一班")
session.add(new_data)
session.commit()
session.close()
2.2.4 更新数据
目前,数据库中已经添加了一条数据,如果要对这条数据进行更新,SQLAlchemy 提供了以下两种更新数据的方法。完整代码如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:3.添加数据.py
@time:2020/11/01
"""
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, DateTime
engine = create_engine("mysql+pymysql://root:mysql@localhost:3306/test?charset=utf8", echo=True,
pool_size=5, pool_timeout=30, max_overflow=4, pool_recycle=7200)
Base = declarative_base()
DBSession = sessionmaker(bind=engine)
session = DBSession()
# 第一种创建数据表的方式
class MyTable(Base):
# 表名
__tablename__ = "mytable"
# 字段,属性
id = Column(Integer, primary_key=True)
name = Column(String(50), unique=True)
age = Column(Integer)
birth = Column(DateTime)
class_name = Column(String(50))
Base.metadata.create_all(engine)
"""
首先查询 mytable 表id为1的数据,然后使用update对这条数据进行更新,update数据的格式是字典类型,
通过键值的方式对数据进行更新,接着使用 session.commit()执行更新语句,最后使用session.close()
关闭当前会话,释放资源。如果批量更新,就可以将filter_by(id=1)去掉,
这样能将mytable中age字段的值全部更新为12。filter_by 相当于SQL语句里面的where条件判断
"""
session.query(MyTable).filter_by(id=1).update({
MyTable.age: 12})
"""
使用赋值方式更新数据:
将数据查询出来,生成查询对象,然后对该对象的某个属性重新赋值,最后提交到数据库执
行。这种方法对批量更新不太友好,常用于单条数据的更新,若要用这种方法实现批量更新,
则只能循环每条数据进行赋值更改。但这种方法对性能影响较大,批量更新使用update()比较合理。
"""
get_data = session.query(MyTable).filter_by(id=1).first()
get_data.class_name = "三年级三班"
session.commit()
session.close()
2.2.5 查询数据
SQLAlchemy 对数据库多种查询方式有很好的语法支持。完整代码如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:5.查询数据.py
@time:2020/11/01
"""
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Integer, String, DateTime
from sqlalchemy import Column, MetaData, ForeignKey, Table
from sqlalchemy.dialects.mysql import (INTEGER, CHAR)
from sqlalchemy import or_
engine = create_engine("mysql+pymysql://root:mysql@localhost:3306/test?charset=utf8", echo=True,
pool_size=5, pool_timeout=30, max_overflow=4, pool_recycle=7200)
Base = declarative_base()
DBSession = sessionmaker(bind=engine)
session = DBSession()
# 第一种创建数据表的方式
class MyTable(Base):
# 表名
__tablename__ = "mytable"
# 字段,属性
id = Column(Integer, primary_key=True)
name = Column(String(50), unique=True)
age = Column(Integer)
birth = Column(DateTime)
class_name = Column(String(50))
Base.metadata.create_all(engine)
# 创建数据表
# Base.metadata.create_all(engine)
meta = MetaData()
my_class = Table("myclass", meta,
Column("id", INTEGER, primary_key=True),
Column("name", CHAR(50), ForeignKey(MyTable.name)),
Column("class_name", CHAR(50))
)
# 创建数据表
# my_class.create(bind=engine)
# 查询 MyClass全部数据: 相当于SQL语句里面的select * from myclass;而all()是将数据以列表的形式返回。
# get_data = session.query(my_class).all()
# # [(1, 'AmoXiang', '三年级三班'), (2, 'Han meimei', '三年级二班'), (3, 'LILEI', '三年级一班')]
# print(get_data)
# for i in get_data:
# # print(type(i))
# print(f"我的名字是: {i.name}, 班级是: {i.class_name}")
# 查询某一字段
# get_data = session.query(MyTable.name, MyTable.age).all()
# for i in get_data:
# print(f"我的名字是: {i.name}, 年龄是: {i.age}")
#
# session.close()
# 根据条件查询某条数据
# 筛选方法一:
# get_data = session.query(MyTable).filter(MyTable.id == 1).all()
# print(get_data)
# 筛选方法二:
get_data = session.query(MyTable).filter_by(id=1).all()
print("数据类型是: " + str(type(get_data)))
for i in get_data:
print("我的名字是: " + i.name)
"""
总结:
(1) 字段写法: filter 筛选的字段是带类名(表名)的,而filter_by只需筛选字段即可。
(2) 判断条件: filter 比 filter_by 多出一个等号。
(3) 作用范围: filter 可以用于单表或者多表查询,而filter_by只能用于单表查询。
all() 方法是将查询数据以列表的形式返回,但只查询一条数据的时候,可以用first()返回第一条数据。
"""
# get_data = session.query(MyTable).filter(MyTable.id >= 2, MyTable.class_name == "三年级二班").first()
# print(f"我的名字是: {get_data.name}")
get_data = session.query(MyTable).filter(or_(MyTable.id >= 2, MyTable.class_name == "三年级一班")).all()
# print(type(get_data))
# for i in get_data:
# print(i.name)
# 内连接
get_data = session.query(MyTable).join(my_class).filter(MyTable.class_name == '三年级二班').all()
print('数据类型是:' + str(type(get_data)))
for i in get_data:
print('我的名字是:' + i.name)
print('我的班级是:' + i.class_name)
# 外连接
get_data = session.query(MyTable).outerjoin(my_class).filter(MyTable.class_name == '三年级二班').all()
for i in get_data:
print('我的名字是:' + i.name)
print('我的班级是:' + i.class_name)
"""
一般来说,如果涉及复杂的查询语句,特别涉及多表查询和复杂的查询条件时,SQLAlchemy还可以直接执行SQL语句
"""
sql = "select * from mytable "
session.execute(sql)
# 如果涉及更新、添加数据,就需要session.commit()
session.commit()
session.close()
2.3 ORM爬虫实战一:爬取51Job招聘信息
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:ORM爬虫实战一:爬取51Job招聘信息.py
@time:2020/11/01
"""
import requests
import re
from bs4 import BeautifulSoup
import math
from sqlalchemy import *
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
import time
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36"
}
engine = create_engine("mysql+pymysql://root:mysql@localhost:3306/test?charset=utf8", echo=True,
pool_size=5, pool_timeout=30, max_overflow=4, pool_recycle=7200)
Base = declarative_base()
DBSession = sessionmaker(bind=engine)
session = DBSession()
# 定义数据模型
class TableInfo(Base):
__tablename__ = "job_info"
id = Column(Integer(), primary_key=True)
job_id = Column(String(100), comment='职位ID')
company_name = Column(String(100), comment='企业名称')
company_type = Column(String(100), comment='企业类型')
company_scale = Column(String(100), comment='企业规模')
company_trade = Column(String(100), comment='企业经营范围')
company_welfare = Column(String(1000), comment='企业福利')
job_name = Column(String(3000), comment='职位名称')
job_pay = Column(String(100), comment='职位薪酬')
job_years = Column(String(100), comment='工龄要求')
job_education = Column(String(100), comment='学历要求')
job_member = Column(String(100), comment='招聘人数')
job_location = Column(String(3000), comment='上班地址')
job_describe = Column(Text, comment='工作描述')
job_date = Column(String(100), comment='发布日期')
recruit_sources = Column(String(100), comment='招聘来源')
log_date = Column(String(100), comment='记录日期')
# 创建数据表
Base.metadata.create_all(engine)
# 写入数据库
def insert_db(info_dict):
if info_dict:
temp_id = info_dict["job_id"]
# 判断是否存在记录
info = session.query(TableInfo.job_id).filter_by(job_id=temp_id).first()
# 若存在更新数据
if info:
info.job_id = info_dict.get('job_id', ''),
info.company_name = info_dict.get('company_name', ''),
info.company_type = info_dict.get('company_type', ''),
info.company_trade = info_dict.get('company_trade', ''),
info.company_scale = info_dict.get('company_scale', ''),
info.company_welfare = info_dict.get('company_welfare', ''),
info.job_name = info_dict.get('job_name', ''),
info.job_pay = info_dict.get('job_pay', ''),
info.job_years = info_dict.get('job_years', ''),
info.job_education = info_dict.get('job_education', ''),
info.job_member = info_dict.get('job_member', ''),
info.job_location = info_dict.get('job_location', ''),
info.job_describe = info_dict.get('job_describe', ''),
info.job_date = info_dict.get('job_date', ''),
info.recruit_sources = info_dict.get('recruit_sources', ''),
info.log_date = time.strftime("%Y.%m.%d %H:%M:%S", time.localtime(time.time()))
else:
inset_data = TableInfo(
job_id=info_dict.get('job_id', ''),
company_name=info_dict.get('company_name', ''),
company_type=info_dict.get('company_type', ''),
company_trade=info_dict.get('company_trade', ''),
company_scale=info_dict.get('company_scale', ''),
company_welfare=info_dict.get('company_welfare', ''),
job_name=info_dict.get('job_name', ''),
job_pay=info_dict.get('job_pay', ''),
job_years=info_dict.get('job_years', ''),
job_education=info_dict.get('job_education', ''),
job_member=info_dict.get('job_member', ''),
job_location=info_dict.get('job_location', ''),
job_describe=info_dict.get('job_describe', ''),
job_date=info_dict.get('job_date', ''),
recruit_sources=info_dict.get('recruit_sources', ''),
log_date=time.strftime("%Y.%m.%d %H:%M:%S", time.localtime(time.time())))
session.add(inset_data)
session.commit()
# 获取城市的编号
def get_city_code():
url = "https://js.51jobcdn.com/in/resource/js/2020/search/common.b35d7e36.js"
response = requests.get(url, headers=headers)
response.encoding = "gbk"
city_code = re.search(r"window.area=(\{.*?})", response.text).group(1)
city_dict = dict(eval(city_code)) # 字符串转字典
# 字典的键值互换
city_dict = {
value: key for key, value in city_dict.items() if int(key) <= 320900}
return city_dict
# 获取职位的总页数,参数city_code是城市编号,keyword是职位关键字
def get_page_number(city_code, key_word):
# 获取搜索页的网页信息
url = f"https://search.51job.com/list/{city_code},000000,0000,00,9,99,{key_word},2,1.html?"
response = requests.get(url=url, headers=headers)
# print(response.text)
# 查找总的职位数
re_obj = re.search(r'"jobid_count":"(\d+)"', response.text)
# 计算总页数并返回结果
if re_obj:
page_number = int(math.ceil(int(re_obj.group(1)) / 50))
return page_number
else:
return 0
# 遍历每一页的职业信息
def get_page(key_word, page_number):
for p in range(1, page_number + 1):
# https://search.51job.com/list/030200,000000,0000,00,9,99,python,2,1.html?
url = f"https://search.51job.com/list/090200,000000,0000,00,9,99,{key_word},2,{p}.html?"
response = requests.get(url=url, headers=headers)
href_list = map(lambda x: x.replace('\\', "")[:-1], re.findall(r'"job_href":"(https:.*?),', response.text))
for href in href_list:
info_dict = get_info(href)
insert_db(info_dict)
# 爬取职位详情页的数据,参数url是职位详情页的链接
def get_info(url):
temp_dict = {
}
if "https://jobs.51job.com/" in url:
response = requests.get(url=url, headers=headers)
response.encoding = "gbk"
time.sleep(1.5)
soup = BeautifulSoup(response.text, "lxml")
# 职位ID
temp_dict["job_id"] = url.split(".html")[0].split("/")[-1]
# 企业名
temp_dict["company_name"] = soup.select("div.com_msg > a > p")[0].get_text()
# 企业类型、规模、经营范围
p_tags = soup.select("div.com_tag > p")
for p_tag in p_tags:
if "i_flag" in str(p_tag):
temp_dict["company_type"] = p_tag.get_text()
if "i_people" in str(p_tag):
temp_dict["company_scale"] = p_tag.get_text()
if "i_trade" in str(p_tag):
temp_dict["company_trade"] = p_tag.get_text().strip()
# 职位名称
temp_dict["job_name"] = soup.select("h1")[0].attrs["title"]
# 职位薪资
temp_dict["job_pay"] = soup.select("div.cn > strong")[0].get_text()
# 职位要求:工龄、招聘人数、发布日期、学历要求
msgltype = soup.find(attrs={
"class": "msg ltype"}).get_text().split("|")
education = ['初中', '中专', '中技', '大专', '高中', '本科', '硕士', '博士']
if msgltype:
for text in msgltype:
if "经验" in text.strip():
temp_dict["job_years"] = text.strip()
if "人" in text.strip():
temp_dict["job_member"] = text.strip()
if "发布" in text.strip():
temp_dict["job_date"] = text.strip()
if text.strip() in education:
temp_dict["job_education"] = text.strip()
# 企业福利待遇
span_tags = soup.select("div.jtag>.t1>span")
welfare = ""
for span_tag in span_tags:
welfare += span_tag.get_text().strip() + "/"
temp_dict["company_welfare"] = welfare[:-1]
# 上班地点
bmsg_inbox = soup.find(attrs={
"class": "bmsg inbox"})
if bmsg_inbox:
if bmsg_inbox.p:
temp_dict["job_location"] = bmsg_inbox.p.get_text().strip()
# 职位的工作描述
find_desc = soup.find(name="div", class_="bmsg job_msg inbox")
new_soup = BeautifulSoup(str(find_desc).split('')[0], "lxml")
temp_dict["job_describe"] = new_soup.get_text().strip().replace("\xa0", "")
# 招聘来源
temp_dict["recruit_sources"] = "前程无忧"
return temp_dict
if __name__ == '__main__':
# print(get_page_number("020000", "python")
# print(get_info("https://jobs.51job.com/shanghai-ptq/121160736.html?s=01&t=0"))
# print()
# print(get_page_number(get_city_code()["成都"], "python"))
page_num = get_page_number(get_city_code()["成都"], "python")
get_page("python", page_num)
3. Python操作 MongoDB 数据库
3.1 MongoDB 介绍
MongoDB 是一种基于分布式文件存储的数据库,由 C++ 语言编写,旨在为 Web 应用提供可扩展的高性能数据存储解决方案。MongoDB 是介于关系数据库和非关系数据库之间的产品,是非关系数据库中功能最丰富、最像关系数据库的数据库。MongoDB 支持的数据结构非常松散,类似于 JSON 的 BSON 格式,因此可以存储比较复杂的数据类型。MongoDB 最大的特点是支持的查询语言非常强大,其语法有点类似面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。MongoDB 的特点是高性能、易部署、易使用,存储数据非常方便。主要功能特性有:
(1) 面向集合存储、易存储对象类型的数据。
(2) 模式自由。
(3) 支持动态查询。
(4) 支持完全索引,包含内部对象。
(5) 支持查询。
(6) 支持复制和故障恢复。
(7) 使用高效的二进制数据存储,包括大型对象 (如视频等)。
(8) 自动处理碎片,以支持云计算层次的扩展性。
(9) 支持 Ruby、Python、Java、C++、PHP、C# 等多种语言。
(10) 文件存储格式为 BSON (一种JSON的扩展)。
(11) 可通过网络访问。
所谓 面向集合 (Collection-Oriented),意思是数据被分组存储在数据集中,被称为一个集合 (Collection)。每个集合在数据库中都有一个唯一的标识名,并且可以包含无限数目的文档。集合的概念类似关系型数据库 (RDBMS) 里的表 (Table ),不同的是 MongoDB 不需要定义任何模式 (Schema),具有闪存高速缓存算法,能够快速识别数据库内大数据集中的热数据,提供一致的性能改进。模式自由 (Schema-Free),意味着对于存储在 MongoDB 数据库中的文件,不需要知道它的任何结构定义。如果需要,完全可以把不同结构的文件存储在同一个数据库里。存储在集合中的文档被存储为 键-值 对的形式。键用于唯一标识一个文档,为字符串类型,而值则可以是各种复杂的文件类型。我们称这种存储形式为 BSON(Binary Serialized Document Format)。MongoDB 已经在多个站点部署,其主要场景如下:
(1) 网站实时数据处理。非常适合实时地添加、更新与查询,并具备网站实时数据存储的复制及高度伸缩性。
(2) 缓存。由于性能很高,因此适合作为信息基础设施的缓存层。在系统重启之后,由它搭建的持久化缓存层可以避免下层的数据源过载。
(3) 高伸缩性的场景。非常适合由数十或数百台服务器组成的数据库,它的路线图中已经包含对 MapReduce 引擎的内置支持。
3.2 MongoDB 可视化工具
笔者这里就不再赘述 MongoDB数据库的安装,读者可自行百度进行安装。可视化工具可帮助使用者快速查看数据库的使用情况,MongoDB 常用的可视化工具有 RoboMongo 和 MongoBooster。以 RoboMongo 使用为例,官方网站下载地址为:
https://robomongo.org/download
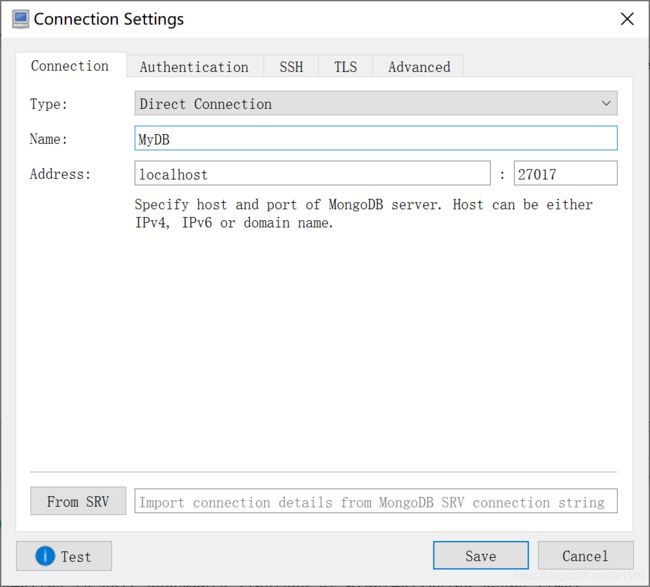
下载后运行 .exe 文件,按提示可完成安装。然后运行软件,单击 MongoDB Connections 界面中的 Create 按钮,弹出 Connections Settings,输入 Name 和 Address 的信息,Name 为对该连接的命名,可自定义命名,Address 处分别输入数据库 IP地址 和 端口。此处以本地数据库为例,如下图所示:
连接数据库后,会看到数据库有一个 system 文件夹,文件夹里有 admin 和 local 数据库,两者皆属于系统数据库,如下图所示:
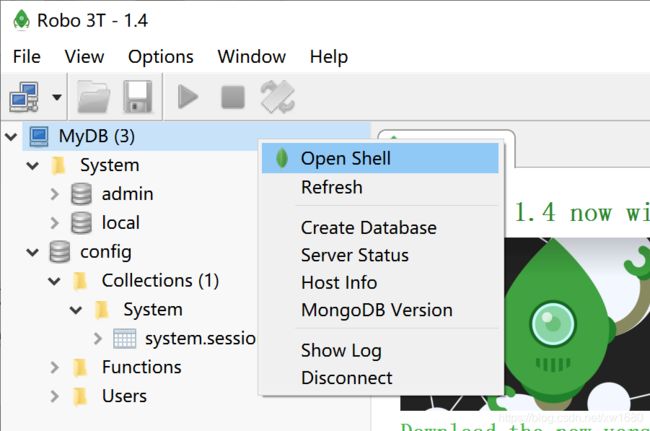
(1) 右击 MyDB,单击 Create Database,将数据库命名为 DB。
(2) 打开数据库 DB,右击 Collections ,选择 Create Collection,命名为 user。新建的 user 称为集合,相当于关系数据库里面的数据表。
(3) 右击 user,选择 Insert Document。Document 代表文档内容,相当于 MySQL 里数据表中的数据。Document 是 BSON 格式,类似 JSON。
(4) 集合 user 里有文件夹 Indexes,用于实现集合的索引功能,文件夹 Functions 用于实现脚本功能,在 Users 中设定用户账号密码,用于设置访问权限。
3.3 PyMongo 的安装
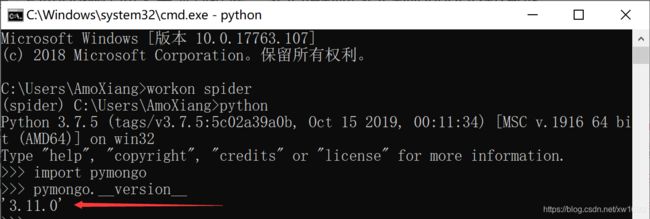
PyMongo 是 Python 操作 MongoDB 的第三方库,有庞大的社区,功能较为稳定和完善。建议使用 pip 安装 PyMongo:
pip install pymongo
完成安装后,打开 CMD 窗口,通过导入模块测试是否安装成功:
3.4 连接 MongoDB 数据库
通过前面的介绍,相信大家对 MongoDB 的数据结构有了一定的了解,本节介绍 Python 连接 MongoDB 数据库。使用 Python 实现对 MongoDB 操作的原理与连接关系式数据库一样:连接数据库 ⇒ 访问数据表(集合) ⇒ 增删改查。Python 连接 MongoDB 主要由 PyMongo 实现,连接代码如下:
import pymongo
# 创建对象,连接本地数据库
# 方法一:
client = pymongo.MongoClient()
# 方法二:
client2 = pymongo.MongoClient("localhost", 27017)
# 方法三:
client3 = pymongo.MongoClient("mongodb://localhost:27017/")
# 连接DB数据库
db = client3["DB"]
# 连接集合user,集合类似关系型数据库的数据表
# 如何集合不存在,就会新建集合user
user_collection = db.user
代码使用三种方法创建数据库 (client) 对象,localhost 是数据库 IP地址,27017 是数据库端口,db=client[“DB”] 指向需要连接的数据库,user_collection = db.user 指向 user 集合 (相当于关系数据库的数据表),如果数据库设置了用户验证,在连接命令上要添加验证信息:
import pymongo
# 用户验证方法一:
client = pymongo.MongoClient()
db_auth = client.admin
db_auth.authenticate = (username, password)
# 连接DB数据库
db = client["DB"]
# 用户验证方法二:
client = pymongo.MongoClient("mongodb://username:password@localhost:27017/")
# 连接DB数据库
db = client["DB"]
上述代码提供两种验证方式,用户验证实质上是在连接数据库的时候,将数据库用户的账号、密码添加到连接语句上实现验证登录。
3.5 添加文档
在 MongoDB 中,常用的操作有添加文档、更新文档、删除文档和查询文档。文档的数据结构和 JSON 基本一样。所有存储在集合中的数据都是 BSON 格式。BSON 是一种类似 JSON 的二进制形式的存储格式,简称 Binary JSON。文档添加方式分别有单条添加和批量添加,实现代码如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:3.添加文档.py
@time:2020/11/23
"""
import pymongo
import datetime
# 创建对象
client = pymongo.MongoClient()
# 连接DB数据库
db = client["DB"]
# 连接集合user,集合类似关系型数据库的数据表
# 如何集合不存在,就会新建集合user
user_collection = db.user
# 设置文档格式(文档即我们常说的数据)
user_info = {
"_id": 100,
"author": "小黄",
"text": "Python 爬虫开发",
"tags": ["mongodb", "python", "pymongo"],
"date": datetime.datetime.utcnow()
}
# 使用 insert_one 单条添加文档,inserted_id获取写入后的id
# 添加文档时,如果文档尚未包含"_id"键,就会白动添加"_id"。
# "_id"的值在集合中必须是唯一的 inserted_id 用于获取添加后的id,若不需要,则可以去掉
user_id = user_collection.insert_one(user_info).inserted_id
print(f"user id is {user_id}")
# 批量添加
user_infos = [{
"_id": 101,
"author": "小黄",
"text": "Python 爬虫开发",
"tags": ["mongodb", "python", "pymongo"],
"date": datetime.datetime.utcnow()
}, {
"_id": 102,
"author": "小黄_A",
"text": "Python 爬虫开发_A",
"tags": {
"db": "MongoDB", "lan": "Python", "modle": "PyMongo"},
"date": datetime.datetime.utcnow()
}]
# inserted_ids用于获取添加后的id,若不需要,则可以直接去掉
user_id = user_collection.insert_many(user_infos).inserted_ids
print(f"user id is {user_id}")
程序执行完之后,在可视化工具中查看结果如下:
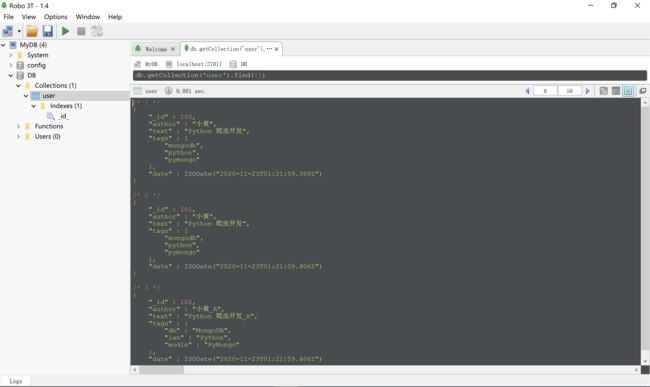
代码实现了单条添加和批量添加,单条添加的数据是 user_info,该数据是一个字典数据结构,批量添加的数据是 user_infos,该数据是一个字典数据组成的列表。执行数据添加分别由 insert_one 和 insert_many 方法实现。数据添加完成后,使用 inserted_id 和 inserted_ids 可返回添加后所自动生成的 id 内容。
3.6 更新文档
更新文档同样分为单条更新和批量更新,分别由 update() 和 update_many() 实现。文档更新需要加入操作符。操作符的作用:通常文档只会有一部分要更新,利用原子的更新修改器可以使得这部分更新极为高效。MongoDB 提供了许多原子操作,比如文档的保存、修改、删除等。所谓原子操作,就是要么将这个文档保存到 MongoDB,要么没有保存到 MongoDB ,不会出现查询到的文档没有保存完整的情况。更新修改器是一种特殊的键,用来指定复杂的更新操作,比如调整、增加或者删除键,还可能用于操作数组或者内嵌文档。下面介绍常用的更新操作符:
(1) $set:用来指定一个键的值。如果这个键不存在,就创建它,如果存在,就执行更新。
(2) $unset:从文档中移除指定的键。
(3) $inc:修改器用来增加已有键的值,或者在键不存在时创建一个键。$inc 就是专门来增加(和减少) 数字的,只能用于整数、长整数或双精度浮点数。要是用在其他类型的数据上,就导致操作失败。
(4) $rename:操作符可以重命名字段名称,新的字段名称不能和文档中现有的字段名相同。如果文档中存在A、B字段,将 B 字段重命名为 A ,$rename 会将 A 字段和值移除掉,然后将 B 字段名改为 A
(5) $push:如果指定的键已经存在,就会向已有的数组末尾加入一个元素,如果指定的键不存在,就会创建一个新的数组。
如何使用操作符实现更新文档呢?例如更新上述已添加的文档的代码如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:4.更新文档.py
@time:2020/11/23
"""
import pymongo
# 创建对象
client = pymongo.MongoClient()
# 连接DB数据库
db = client["DB"]
# 连接集合user,集合类似关系型数据库的数据表
# 如何集合不存在,就会新建集合user
user_collection = db.user
# 更新单条文档
# update(筛选条件,更新内容)。筛选条件为空,默认更新第一条文档
user_collection.update_one({
}, {
"$set": {
"author": "小黄C", "text": "Python Web开发"}})
# 批量更新文档,只要将方法 update 改为 update_many即可
程序执行结果如下:
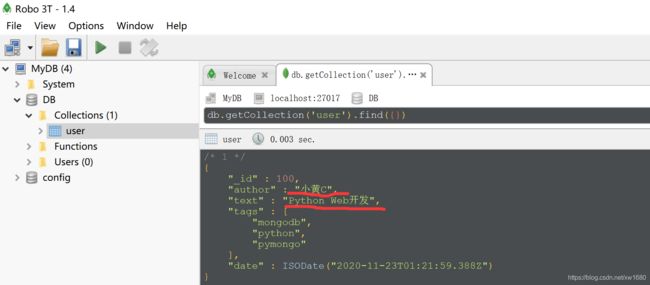
3.7 查询文档
查询文档是使用 find() 方法产生一个查询来从 MongoDB 的集合中查询到数据。该方法与其他的方法的使用大致相同,使用方法如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:5.查询文档.py
@time:2020/11/23
"""
import pymongo
# 创建对象
client = pymongo.MongoClient()
# 连接DB数据库
db = client["DB"]
# 连接集合user,集合类似关系型数据库的数据表
# 如何集合不存在,就会新建集合user
user_collection = db.user
# 查询文档,find({"_id":101}),其中{"id":101}为查询条件
# 若查询条件为空,则默认查询全部
find_value = user_collection.find({
"_id": 101})
print(list(find_value))
print("-----------------------------------------------")
# 如果要实现多条件查询,就需要使用查询操作符:$and和$or,使用方法如下:
# AND条件查询
find_value = user_collection.find({
"$and": [{
"_id": 101}, {
"author": "小黄"}]})
print(list(find_value))
print("-----------------------------------------------")
# OR条件查询
find_value = user_collection.find({
"$or": [{
"author": "小黄_A"}, {
"author": "小黄"}]})
print(list(find_value))
"""
方法find()传递字典作为查询条件,操作符$and和$or作为字典的键,字典的值是列
表格式的,列表中的元素以字典形式表示,一个元素代表一个查询条件。
"""
print("-----------------------------------------------")
"""
如果要实现大于、小于或者不等于这类比较查询,就需要使用比较查询操作符:$lt(小于)、$lte(小于或等于)
$gt(大于)、$gte(大于或等于)、$in(in,符合范围内)、$nin(not in,范围之外)、使用方法如下:
"""
# 如查找id>100而<102,即_id=101的文档
find_value = user_collection.find({
"_id": {
"$gt": 100, "$lt": 102}})
print(list(find_value))
# 查找id在[100,101]
find_value = user_collection.find({
"_id": {
"$in": [100, 101]}})
print(list(find_value))
print("-----------------------------------------------")
"""
比较查询和多条件查询存在明显的差别:
(1) 多条件查询以操作符为字典的键,比较查询以字段为字典的键。
(2) 多条件查询的值是列表格式的,比较查询的值是字典格式的。
"""
# 如果使用两者组成一个查询,代码如下:
find_value = user_collection.find({
"$and": [{
"_id": {
"$gt": 100, "$lt": 102}}, {
"_id": {
"$in": [100, 101]}}]})
print(list(find_value))
"""
从代码中可以看到,多条件查询操作符$and作为最外层字典的键,比较
查询操作符位于最里层字典。$and是将每个条件连接起来,主要作用于每个查询条件之间
;比较查询操作符($gt和$in)使条件按照某个规则成立条件判断,主要作用于每个查询条
件里面。
"""
当查询条件不明确某个值的时候,可以使用模糊匹配进行查询。在 MongoDB 中实现模糊匹配需要引用正则表达式,代码如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:6.模糊查询.py
@time:2020/11/23
"""
import pymongo
import re
# 创建对象
client = pymongo.MongoClient()
# 连接DB数据库
db = client["DB"]
# 连接集合user,集合类似关系型数据库的数据表
# 如何集合不存在,就会新建集合user
user_collection = db.user
# 模糊查询实际上是加入正则表达式实现
# 方法一:
find_value = user_collection.find({
"author": {
"$regex": ".*小.*"}})
print(list(find_value))
print("----------------------------------------")
# 方法二:
regex = re.compile(r".*小.*")
find_value = user_collection.find({
"author": regex})
print(list(find_value))
print("----------------------------------------")
"""
总结: 实现模糊匹配有两种不同的方式,两者都需要引用正则表达式来完成模糊功能。
方法一: 使用操作符 $regex 作为字典的键,告诉数据库这个查询语句要查找字段author
中含有"小"的内容。
方法二:re.compile定义了一个Pattern实例,这是正则表达式对象,将
其实例作为查询条件的值,同样也是告诉数据库需要查找字段 author 中含有 "小" 的内容
"""
3.8 删除文档
collection.delete_many() 方法会删除集合中所有符合条件的文档。collection.delete_one() 方法会删除集合中符合条件的第 1 个文档。语句中的 query 是一个字典对象,用来指定要删除的文档。如果没有指定 query 的值,则 collection.delete_many() 方法会删除集合中的所有文档。由于操作比较简单,这里笔者就不再赘述。
3.9 MongoDB ODM
学习网址
4. Python操作 Redis 数据库
由于 Python 操作 Redis 需要懂得 redis 数据库的一些基本操作,然而本篇博文已经太长,所以在后续的博客编写中在统一进行讲解 redis 数据库的一些基本概念以及它的常用操作和 python 如何去操作它,未完待续。。。