多目标跟踪之LightTrack
论文:LightTrack: A Generic Framework for Online Top-Down Human Pose Tracking
Github: https://github.com/Guanghan/lighttrack
京东的一篇cvpr2019
论文提出了轻量级的多目标跟踪框架LightTrack。包含YOLOV3的目标检测,基于CPN_res101,MSRA152,mobile_deconv这3个网络种任意一个的关键点检测,基于SGCN的人体姿势匹配。整体结构是一种自上而下的结构。
主要贡献:
- 提出了一个通用的基于自上而下的骨架跟踪框架。
- 提出了SGCN作为一个REID模块进行姿势跟踪。
- 根据各种不同的设置进行了大量的实验。
整体流程:

跟踪过程分为主要帧和次要帧。每隔10帧或者目标跟踪丢失的帧算一个主要帧。
在主要帧中,首先使用YOLOv3进行检测,对检测到的目标进行两边20%的放大。再使用关键点检测模型mobile_deconv获得15个或者17个人体关键点。跟踪匹配过程同时考虑了空间相关性(spatial consistency)和姿势相关性(pose consistency)。然后首先使用IOU进行ID的匹配,如果没有匹配上的返回-1,再使用关键点的特征进行匹配。如果还是没有匹配上,就将该目标的ID+1,作为一个新的目标。
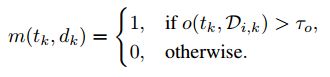
在次要帧中,只通过关键点进行下一帧的关键点预测,具体首先通过之前帧的关键点得到框。然后使用该得到的框进行关键点的预测,会得到预测的结果和得分。最后通过关键点的预测的得分是否小于规定阈值(0.6),来判断目标是否跟踪丢失,如果一直跟踪的,就在图像上画出跟踪的信息,如果跟踪丢失了,就不在图像上画框了。
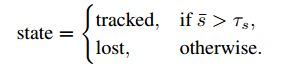
整体来看,框检测过程只有关键帧才有,关键点检测所有帧都有,SGCN识别过程也只有关键帧才有。
HPE(Human Pose Estimation):
姿态关键点检测部分,作者尝试了CPN_res101,MSRA152,mobile_deconv共3种网络结构。
mobile_deconv的结构:
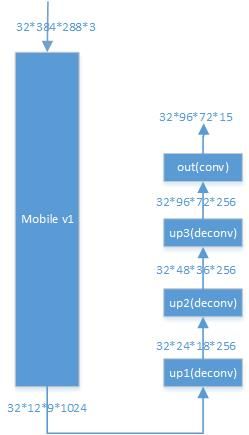
Top-Down Pose Tracking Framework:
需要重新跟新识别ID的情况:
- 之前视频中的人消失,或者遮挡
- 新的候选人出现,或者之前视频中消失的人重新出现
- 人走路的时候相互遮挡,被当成了1个人
- 摄像头的抖动或者变焦导致跟踪失败

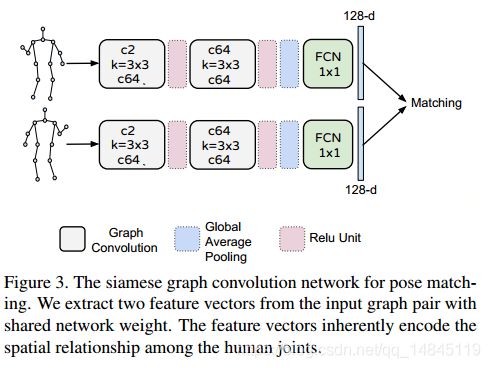
SGCN(Siamese Graph Convolution Network):
优势:
- SGCN提取的特征具有人体姿势的相关性,并且具备可解释性。并且在边界框有很强的关系,对边界框有直接的强制约束。
- 通过使用人体关键点可以更好的进行跟踪,得到ROI区域。
- 保证了候选区域之间的区分度,可以使用姿势特征做基于骨架的姿势匹配。
网络结构代码,
class Model(nn.Module):
r"""Siamese graph convolutional networks
Args:
in_channels (int): Number of channels in the input data
num_class (int): Number of classes for the classification task
graph_args (dict): The arguments for building the graph
edge_importance_weighting (bool): If ``True``, adds a learnable
importance weighting to the edges of the graph
**kwargs (optional): Other parameters for graph convolution units
Shape:
- Input: :math:`(N, in_channels, T_{in}, V_{in}, M_{in})`
- Output: :math:`(N, num_class)` where
:math:`N` is a batch size,
:math:`T_{in}` is a length of input sequence,
:math:`V_{in}` is the number of graph nodes,
:math:`M_{in}` is the number of instance in a frame.
"""
def __init__(self, in_channels, num_class, graph_args,
edge_importance_weighting, **kwargs):
super().__init__()
# load graph
self.graph = Graph(**graph_args)
A = torch.tensor(self.graph.A, dtype=torch.float32, requires_grad=False)
self.register_buffer('A', A)
# build networks
spatial_kernel_size = A.size(0)
temporal_kernel_size = 1
kernel_size = (temporal_kernel_size, spatial_kernel_size)
self.data_bn = nn.BatchNorm1d(in_channels * A.size(1))
self.st_gcn_networks = nn.ModuleList((
st_gcn(in_channels, 64, kernel_size, 1, residual=False, **kwargs),
st_gcn(64, 64, kernel_size, 1, **kwargs),
))
'''
st_gcn(64, 64, kernel_size, 1, **kwargs),
st_gcn(64, 128, kernel_size, 2, **kwargs),
st_gcn(128, 128, kernel_size, 1, **kwargs),
st_gcn(128, 128, kernel_size, 1, **kwargs),
st_gcn(128, 256, kernel_size, 2, **kwargs),
st_gcn(256, 256, kernel_size, 1, **kwargs),
st_gcn(256, 512, kernel_size, 1, **kwargs),
'''
# initialize parameters for edge importance weighting
if edge_importance_weighting:
self.edge_importance = nn.ParameterList([
nn.Parameter(torch.ones(self.A.size()))
for i in self.st_gcn_networks
])
else:
self.edge_importance = [1] * len(self.st_gcn_networks)
# fcn for prediction
self.fcn = nn.Conv2d(64, num_class, kernel_size=1)
def forward(self, input_1, input_2): # siamese network needs two times of forwards
feature_1 = self.extract_feature(input_1)
feature_2 = self.extract_feature(input_2)
return feature_1, feature_2
def extract_feature(self, x):
# data normalization
N, C, T, V, M = x.size()
x = x.permute(0, 4, 3, 1, 2).contiguous()
x = x.view(N * M, V * C, T)
x = self.data_bn(x)
x = x.view(N, M, V, C, T)
x = x.permute(0, 1, 3, 4, 2).contiguous()
x = x.view(N * M, C, T, V)
# forwad
for gcn, importance in zip(self.st_gcn_networks, self.edge_importance):
x, _ = gcn(x, self.A * importance)
# global pooling
x = F.avg_pool2d(x, x.size()[2:])
x = x.view(N, M, -1, 1, 1).mean(dim=1)
# prediction
x = self.fcn(x)
feature = x.view(x.size(0), -1)
#print("feature size: {}".format(feature.size()))
return feature
class st_gcn(nn.Module):
r"""Applies a spatial temporal graph convolution over an input graph sequence.
Args:
in_channels (int): Number of channels in the input sequence data
out_channels (int): Number of channels produced by the convolution
kernel_size (tuple): Size of the temporal convolving kernel and graph convolving kernel
stride (int, optional): Stride of the temporal convolution. Default: 1
dropout (int, optional): Dropout rate of the final output. Default: 0
residual (bool, optional): If ``True``, applies a residual mechanism. Default: ``True``
Shape:
- Input[0]: Input graph sequence in :math:`(N, in_channels, T_{in}, V)` format
- Input[1]: Input graph adjacency matrix in :math:`(K, V, V)` format
- Output[0]: Outpu graph sequence in :math:`(N, out_channels, T_{out}, V)` format
- Output[1]: Graph adjacency matrix for output data in :math:`(K, V, V)` format
where
:math:`N` is a batch size,
:math:`K` is the spatial kernel size, as :math:`K == kernel_size[1]`,
:math:`T_{in}/T_{out}` is a length of input/output sequence,
:math:`V` is the number of graph nodes.
"""
def __init__(self,
in_channels,
out_channels,
kernel_size, # (temporal_kernel_size, spatial_kernel_size)
stride=1,
dropout=0,
residual=True):
super().__init__()
assert len(kernel_size) == 2
assert kernel_size[0] % 2 == 1
padding = ((kernel_size[0] - 1) // 2, 0)
self.gcn = ConvTemporalGraphical(in_channels, out_channels,
kernel_size[1])
if not residual:
self.residual = lambda x: 0
elif (in_channels == out_channels) and (stride == 1):
self.residual = lambda x: x
else:
self.residual = nn.Sequential(
nn.Conv2d(
in_channels,
out_channels,
kernel_size=1,
stride=(stride, 1)),
nn.BatchNorm2d(out_channels),
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x, A):
res = self.residual(x)
x, A = self.gcn(x, A)
return self.relu(x), A
传统卷积:

图卷积:
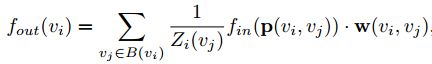
对于一个 batch 的视频,我们可以用一个 5 维矩阵(N,C,T,V,M) 表示。
N 代表视频的数量,通常一个 batch 有 256 个视频(其实随便设置,最好是 2 的指数)。
C 代表关节的特征,通常一个关节包含 x,y,acc 等 3 个特征(如果是三维骨骼就是 4 个)。
T 代表关键帧的数量,一般一个视频有 150 帧。
V 代表关节的数量,通常一个人标注 18 个关节。
M代表一帧中的人数,一般选择平均置信度最高的 2 个人。
代码,
class ConvTemporalGraphical(nn.Module):
r"""The basic module for applying a graph convolution.
Args:
in_channels (int): Number of channels in the input sequence data
out_channels (int): Number of channels produced by the convolution
kernel_size (int): Size of the graph convolving kernel
t_kernel_size (int): Size of the temporal convolving kernel
t_stride (int, optional): Stride of the temporal convolution. Default: 1
t_padding (int, optional): Temporal zero-padding added to both sides of
the input. Default: 0
t_dilation (int, optional): Spacing between temporal kernel elements.
Default: 1
bias (bool, optional): If ``True``, adds a learnable bias to the output.
Default: ``True``
Shape:
- Input[0]: Input graph sequence in :math:`(N, in_channels, T_{in}, V)` format
- Input[1]: Input graph adjacency matrix in :math:`(K, V, V)` format
- Output[0]: Outpu graph sequence in :math:`(N, out_channels, T_{out}, V)` format
- Output[1]: Graph adjacency matrix for output data in :math:`(K, V, V)` format
where
:math:`N` is a batch size,
:math:`K` is the spatial kernel size, as :math:`K == kernel_size[1]`,
:math:`T_{in}/T_{out}` is a length of input/output sequence,
:math:`V` is the number of graph nodes.
"""
def __init__(self,
in_channels, # in_channels for Data is 2: (x, y)
out_channels,
kernel_size,
t_kernel_size=1, # t_kernel_size == 1 means only use single-frame
t_stride=1,
t_padding=0,
t_dilation=1,
bias=True):
super().__init__()
self.kernel_size = kernel_size
self.conv = nn.Conv2d(
in_channels,
out_channels * kernel_size,
kernel_size=(t_kernel_size, 1),
padding=(t_padding, 0),
stride=(t_stride, 1),
dilation=(t_dilation, 1),
bias=bias)
def forward(self, x, A):
assert A.size(0) == self.kernel_size
x = self.conv(x) # Conv2D
n, kc, t, v = x.size()
x = x.view(n, self.kernel_size, kc//self.kernel_size, t, v)
x = torch.einsum('nkctv,kvw->nctw', (x, A))
return x.contiguous(), A
训练损失函数:
contrastive loss
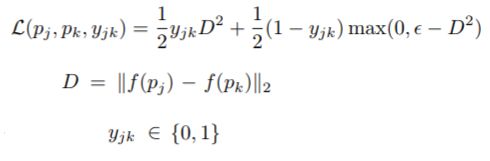
其中,D表示归一化的欧式距离,当j和k类别相同时候,yjk=1,不同的时候,yjk=0。
e表示类间的最小margen。
代码,
class ContrastiveLoss(torch.nn.Module):
"""
Contrastive loss function.
Based on:
"""
def __init__(self, margin=1.0):
super(ContrastiveLoss, self).__init__()
self.margin = margin
def check_type_forward(self, in_types):
assert len(in_types) == 3
x0_type, x1_type, y_type = in_types
assert x0_type.size() == x1_type.shape
assert x1_type.size()[0] == y_type.shape[0]
assert x1_type.size()[0] > 0
assert x0_type.dim() == 2 # last layer graph feature dimension: (batch_size, feature_size)
assert x1_type.dim() == 2
assert y_type.dim() == 1 # label: 0->not matching; 1->matching
def forward(self, x0, x1, y):
self.check_type_forward((x0, x1, y))
# euclidian distance
diff = x0 - x1
dist_sq = torch.sum(torch.pow(diff, 2), 1)
dist = torch.sqrt(dist_sq)
mdist = self.margin - dist
dist = torch.clamp(mdist, min=0.0)
loss = y * dist_sq + (1 - y) * torch.pow(dist, 2)
loss = torch.sum(loss) / 2.0
return loss
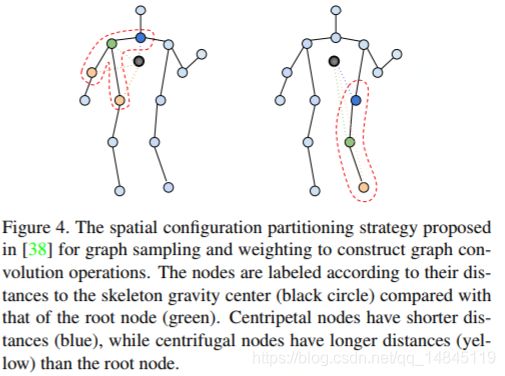
对于一个根节点,与它相连的边可以分为 3 部分。
第 1 部分连接了空间位置上比本节点更远离整个骨架重心的邻居节点(黄色节点),包含了离心运动的特征。
第 2 部分连接了更为靠近重心的邻居节点(蓝色节点),包含了向心运动的特征。
第 3 部分连接了根节点本身(绿色节点),包含了静止的特征。
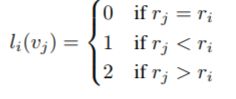
训练数据集:
MPII Video Pose dataset: 593 个训练视频, 74 验证视频,375 测试视频。
COCO
PoseTrack dataset
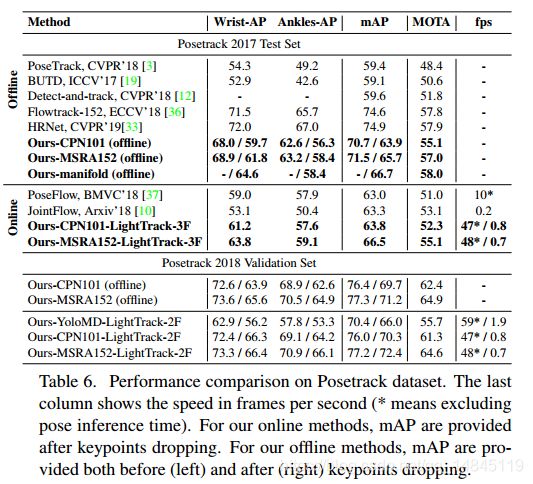
实验结果:
代码:
- 检测部分使用darknetv3官方程序训练,作者程序使用pytorch读取训练后保存的.weights以及解析相应.cfg。
- 关键点检测部分使用tensorflow训练,由于作者同时使用了coco和posetrack数据集。所以格式是作者自己定义的json格式。
{
"annolist": [{
"image": [{
"name": "/export/guanghan/Data/posetrack_data/images/bonn_5sec/020910_mpii/00000001.jpg
}],
"annorect": [{
"y2": [820],
"annopoints": [{
"point": [{
"y": [480.276],
"x": [1309.639],
"score": [1.0],
"id": [0]
}, {
"y": [471.052],
"x": [1308.319],
"score": [1.0],
"id": [1]
}, {
"y": [472.37],
"x": [1309.639],
"score": [1.0],
"id": [2]
}, {
"y": [456.557],
"x": [1267.417],
"score": [1.0],
"id": [3]
}, {
"y": [476.323],
"x": [1300.403],
"score": [1.0],
"id": [4]
}, {
"y": [480.276],
"x": [1225.194],
"score": [1.0],
"id": [5]
}, {
"y": [564.609],
"x": [1299.083],
"score": [1.0],
"id": [6]
}, {
"y": [550.115],
"x": [1126.236],
"score": [1.0],
"id": [7]
}, {
"y": [575.151],
"x": [1151.306],
"score": [1.0],
"id": [8]
}, {
"y": [602.823],
"x": [1229.153],
"score": [1.0],
"id": [9]
}, {
"y": [676.615],
"x": [1226.514],
"score": [1.0],
"id": [10]
}, {
"y": [706.922],
"x": [1188.25],
"score": [1.0],
"id": [11]
}, {
"y": [592.281],
"x": [1292.486],
"score": [1.0],
"id": [12]
}, {
"y": [577.1275],
"x": [1203.4235],
"score": [1.0],
"id": [13]
}, {
"y": [561.974],
"x": [1114.361],
"score": [1.0],
"id": [14]
}]
}],
"track_id": [0],
"y1": [423],
"score": [0.9997325539588928],
"x2": [1329],
"x1": [1094]
},
{
"y2": [940],
"annopoints": [{
"point": [{
"y": [599.656],
"x": [1084.479],
"score": [1.0],
"id": [0]
}, {
"y": [589.703],
"x": [1085.903],
"score": [1.0],
"id": [1]
}, {
"y": [589.703],
"x": [1085.903],
"score": [1.0],
"id": [2]
}, {
"y": [569.797],
"x": [1034.653],
"score": [1.0],
"id": [3]
}, {
"y": [593.969],
"x": [1078.785],
"score": [1.0],
"id": [4]
}, {
"y": [599.656],
"x": [999.062],
"score": [1.0],
"id": [5]
}, {
"y": [770.281],
"x": [1041.771],
"score": [1.0],
"id": [6]
}, {
"y": [714.828],
"x": [892.292],
"score": [1.0],
"id": [7]
}, {
"y": [724.781],
"x": [936.424],
"score": [1.0],
"id": [8]
}, {
"y": [815.781],
"x": [896.562],
"score": [1.0],
"id": [9]
}, {
"y": [800.141],
"x": [1028.958],
"score": [1.0],
"id": [10]
}, {
"y": [844.219],
"x": [822.535],
"score": [1.0],
"id": [11]
}, {
"y": [719.094],
"x": [1036.076],
"score": [1.0],
"id": [12]
}, {
"y": [726.914],
"x": [1018.281],
"score": [1.0],
"id": [13]
}, {
"y": [734.734],
"x": [1000.486],
"score": [1.0],
"id": [14]
}]
}],
"track_id": [1],
"y1": [536],
"score": [0.9994370341300964],
"x2": [1112],
"x1": [796]
},
{
"y2": [742],
"annopoints": [{
"point": [{
"y": [397.156],
"x": [848.719],
"score": [1.0],
"id": [0]
}, {
"y": [389.474],
"x": [850.257],
"score": [1.0],
"id": [1]
}, {
"y": [391.01],
"x": [848.719],
"score": [1.0],
"id": [2]
}, {
"y": [371.036],
"x": [807.188],
"score": [1.0],
"id": [3]
}, {
"y": [397.156],
"x": [836.413],
"score": [1.0],
"id": [4]
}, {
"y": [386.401],
"x": [757.965],
"score": [1.0],
"id": [5]
}, {
"y": [470.906],
"x": [842.566],
"score": [1.0],
"id": [6]
}, {
"y": [484.734],
"x": [677.979],
"score": [1.0],
"id": [7]
}, {
"y": [507.781],
"x": [691.823],
"score": [1.0],
"id": [8]
}, {
"y": [526.219],
"x": [762.58],
"score": [1.0],
"id": [9]
}, {
"y": [604.578],
"x": [751.812],
"score": [1.0],
"id": [10]
}, {
"y": [619.943],
"x": [739.507],
"score": [1.0],
"id": [11]
}, {
"y": [501.635],
"x": [824.108],
"score": [1.0],
"id": [12]
}, {
"y": [451.70050000000003],
"x": [729.509],
"score": [1.0],
"id": [13]
}, {
"y": [401.766],
"x": [634.91],
"score": [1.0],
"id": [14]
}]
}],
"track_id": [2],
"y1": [337],
"score": [0.9968172311782837],
"x2": [871],
"x1": [613]
},
{
"y2": [601],
"annopoints": [{
"point": [{
"y": [258.724],
"x": [975.375],
"score": [1.0],
"id": [0]
}, {
"y": [252.409],
"x": [976.639],
"score": [1.0],
"id": [1]
}, {
"y": [252.409],
"x": [976.639],
"score": [1.0],
"id": [2]
}, {
"y": [238.516],
"x": [939.986],
"score": [1.0],
"id": [3]
}, {
"y": [252.409],
"x": [961.472],
"score": [1.0],
"id": [4]
}, {
"y": [253.672],
"x": [886.903],
"score": [1.0],
"id": [5]
}, {
"y": [369.87],
"x": [970.319],
"score": [1.0],
"id": [6]
}, {
"y": [344.609],
"x": [818.653],
"score": [1.0],
"id": [7]
}, {
"y": [364.818],
"x": [864.153],
"score": [1.0],
"id": [8]
}, {
"y": [429.232],
"x": [880.583],
"score": [1.0],
"id": [9]
}, {
"y": [460.807],
"x": [917.236],
"score": [1.0],
"id": [10]
}, {
"y": [511.328],
"x": [866.681],
"score": [1.0],
"id": [11]
}, {
"y": [368.607],
"x": [946.306],
"score": [1.0],
"id": [12]
}, {
"y": [345.8725],
"x": [870.4725000000001],
"score": [1.0],
"id": [13]
}, {
"y": [323.138],
"x": [794.639],
"score": [1.0],
"id": [14]
}]
}],
"track_id": [3],
"y1": [205],
"score": [0.980134904384613],
"x2": [994],
"x1": [776]
}
]
}]
}
总结:
采用YOLOv3 + MobileNetv1-deconv的检测+关键点回归,可以实现 2 FPS 的速度和70:4 mAP 准确性。在PoseTrack’18 validation set数据集上达到55:7% MOTA(Multi-Object Tracking Accuracy)得分。
References:
https://www.zhihu.com/question/276101856/answer/638672980