大神万字总结:InnoDB 锁类型及其详细分析
0 事务支持
首先回顾一下事务相关的基础概念。
在默认情况下,InnoDB 开启自动提交,每一个 SQL 语句会形成其独立的事务,在语句执行完毕后自动提交,如果语句执行失败,则自动回滚。用户可以通过 START TRANSACTION 或 BEGIN 命令显式开启事务,通过 COMMIT 或 ROLLBACK 显示提交或回滚事务。用户可以通过 SET AUTO_COMMIT=0 显式关闭自动提交。
隔离级别方面,InnoDB 支持标准的: READ UNCOMMITTED , READ COMMITED , REPEATABLE READ 和 SERIALIZABLE 四种隔离级别。默认情况下,InnoDB 隔离级别设置为 REPEATABLE READ ,可以通过变量 tx_isolation 设置期望的事务隔离级别。
InnoDB 通过不同类型的锁来实现对事务隔离性、一致性的保证,同时提供尽可能高的性能。
为了方便下面讨论,我们建如下表,并进行数据初始化:
CREATE TABLE `tb_test` (`id` INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,`value` INT NOT NULL,`cnt` INT NOT NULL,KEY idx_cnt(`cnt`))ENGINE=INNODB;INSERT INTO `tb_test` VALUES(1, 1, 1), (5, 5, 5), (10, 10, 10), (15, 15, 15), (20, 20, 20);
复制代码
复制代码
后续讨论均以如上数据结构及初始数据为假设进行讨论。
1 锁的类型及兼容性
1.1 表级锁
MySQL 在引擎之上支持表级别的锁,在数据备份、数据同步等场景下,可以通过表级锁确保获得完整一致的数据。
-
锁定表读
LOCK TABLE tb_test READ;复制代码
复制代码
锁定表读时,不影响其他查询,但阻塞其他数据更新类操作。

-
锁定写表
LOCK TABLE tb_test WRITE;复制代码
复制代码
锁定表写,阻塞所有其他在当前表上的读写操作。

1.2 行级锁
InnoDB 为了尽可能支持高并发的写入,支持细粒度的行级锁。行级锁分为如下几种:
-
共享(S)锁(Shared Lock):表示锁定一行数据并读取。
-
排它(X)锁(Exclusive Lock): 表示锁定一行数据更新或删除。
行级锁的兼容关系如下:

可以看到,只有共享锁之间兼容,其他组合之间都是冲突的。
1.3 意向锁
考虑如下场景:
Session A: 申请表 T 的某一行 R 上的 X 锁成功。Session B: 申请表 T 上的 X 锁,由于与 SessionA 的锁定对象不同,也成功。
复制代码
这时,Session B 可以在表 T 上进行任意数据的读写,因此也可以对行 R 进行修改,这与 Session A 获取到的 X 锁是冲突的。为了解决这种问题,InnoDB 在行级锁之上支持 表级别的意向锁 (Intention Lock)。
-
意向共享(IS)锁(Intention Shared lock): 表示事务期望对表 T 上某些行获取共享锁。
-
意向排他(IX)锁(Intention Exclusive lock):表示事务期望对表 T 上某些行获取排他锁。
例如: SELECT ... LOCK IN SHARE MODE 会在表上设置 IS 锁,而 SELECT ... FOR UPDATE 会在表上设置 IX 锁。
意向锁遵循如下原则:
-
在某事务获取 S 锁之前,需要首先获取对应表上的 IS 或者更强的 IX 锁。
-
在某事务获取 X 锁之前,需要首先获取对应表上是 IX 锁。
兼容性方面:
-
意向锁之间是完全兼容的。这是因为意向锁是为了处理表锁和行锁之间可能存在的并发冲突而引入的,意向锁获取的上下文中,实际期望操作的是表中的某些行,两个事务可能操作的是完全不同的行,因此意向锁之间没有互相阻塞的需要。
-
意向锁是表级锁,因此与行锁之间是完全兼容的,不存在互相冲突。
-
意向锁和表级锁之间的兼容性,可以将意向锁视作同等级别的表锁进行分析。即:IX 锁与表级 X, S 锁都是冲突的,IS 锁与表级 X 锁冲突、与表级 S 锁兼容。
1.4 行锁、间隙锁及 Next-Key Lock
如前面讨论,InnoDB 支持行级锁。行级锁主要包括行锁、间隙锁以及 Next-Key lock
1.4.1 行锁
从名称看来,行锁锁定的对象是表中的记录行。 但事实上,行锁锁定的对象是索引记录 。通常 InnoDB 表都会建立索引,即使不显式建立索引,InnoDB 也会为表创建索引。
对两个会话,执行如下命令:

此时查询锁的情况:
mysql> select * from innodb_lock_waits;+-------------------+-------------------+-----------------+------------------+| requesting_trx_id | requested_lock_id | blocking_trx_id | blocking_lock_id |+-------------------+-------------------+-----------------+------------------+| 15389 | 15389:23:3:2 | 15388 | 15388:23:3:2 |+-------------------+-------------------+-----------------+------------------+1 row in set (0.01 sec)# 为了便于展示,部分信息省略mysql> select * from innodb_locks;+--------------+-------------+-----------+-----------+------------------+------------+| lock_id | lock_trx_id | lock_mode | lock_type | lock_table | lock_index |+--------------+-------------+-----------+-----------+------------------+------------+| 15389:23:3:2 | 15389 | X | RECORD | `test`.`tb_test` | PRIMARY || 15388:23:3:2 | 15388 | S | RECORD | `test`.`tb_test` | PRIMARY |+--------------+-------------+-----------+-----------+------------------+------------+2 rows in set (0.00 sec)
复制代码
复制代码
可以看到会话 A 持有 S 锁,而此时会话 B 申请 X 锁被会话 A 阻塞。注意此时 lock_type 是 RECORD , lock_index 是 PRIMARY ,表明两个锁的类型是行锁,而这个行锁的锁定对象是表的主键记录。此时执行命令 SHOW ENGINE INNODB STATUS ,可以看到如下结果,注意字样: X locks rec but not gap ,表明不是间隙锁。
RECORD LOCKS space id 23 page no 3 n bits 72 index `PRIMARY` of table `test`.`tb_test` trx id 15387 lock_mode X locks rec but not gap waiting复制代码
复制代码
1.4.2 间隙锁 (Gap Lock)与幻读
考虑下面的场景

此时查看锁的情况如下:

可以看到,这个场景中,两个会话都获取了间隙锁。session A 获取了 X 型的 Gap Lock, lock_type 为 RECORD. sessionB 在插入数据时,期望获取同样的 X 锁,被 session A 阻塞。
那么,什么是间隙锁呢?
间隙锁是指:在扫描数据时,对于满足条件的数据,锁定索引记录之间区间,或者第一个索引记录之前的区间,或者最后一个索引记录之后的区间。例如,对于表 tb_test 中的数据:
MySQL [gaea]> select * from tb_test;+----+-------+-----+| id | value | cnt |+----+-------+-----+| 1 | 1 | 1 || 5 | 5 | 5 || 10 | 10 | 10 || 15 | 15 | 15 || 20 | 20 | 20 |+----+-------+-----+复制代码
复制代码
针对主键 id , 则应该有如下间隙, 注意他们都是开区间 :
(-∞,1), (1,5), (5,10), (10,15), (15,20), (20,∞)复制代码
复制代码
前面的例子中,session A 和 session B 所操作的数据都位于区间 (5, 10) 而观察此时 lock_data 列,值为 10。即间隙 (5, 10) 与索引记录 10 相关联。因此, 间隙锁位于行锁对应的索引记录之前,到前一个索引之间的区间。
那么,为什么需要间隙锁呢?
考虑如下场景:

此场景下,session B 的插入操作会被 session A 第一条 SELECT ... FOR UPDATE 语句阻塞,因为 session B 期望插入的记录,位于 session A 锁定的区间内。
此时,如果没有间隙锁,session A 第二次查询将查到第一次查询结果中不存在的记录,即出现了所谓的 幻读 。 因而,间隙锁的存在,主要是为了解决幻读的问题。
在 MySQL InnoDB 的事务模型中,幻读存在的条件是,事务的隔离级别低于 REPEATABLE READ 。
因此,只有将数据库的隔离级别设置为等于或者高于 REPEATABLE READ ,上述场景才会出现会话之间阻塞的情况。如果将隔离级别设置为 READ COMMITED ,则不会出现相应的阻塞,因为在此时的隔离级别下,容忍幻读的存在。
继续考虑如下场景:

按照前面的讨论,两个会话都会获取 (5,10) 之间的间隙锁,那么 session B 是否会被 session A 阻塞?实际情况是并不会阻塞,这是因为: 间隙锁之间并不会相互阻塞,无论锁的类型是 X 还是 S,间隙锁的目的是为了阻止其他会话插入对应的区间,因此也仅会阻塞其他会话的插入操作。
1.4.3 Next-Key lock
考虑如下场景:

此时查询锁的情况如下:

此时,虽然 session A 中的查询,符合条件的记录仅有 (10, 10, 10) 一条,但是,session A 仍旧阻塞了 session B。
上面的场景中: 行锁和间隙锁共同构成了 Next-Key lock. InnoDB 在进行加锁时,会对扫描到的索引加 Next-Key lock,即同时加行锁和间隙锁。 例如,对于插入的记录 (6,6,6) ,对应主键 10,其对应的 Next-Key lock 为: (5,10] 。
1.4.4 Next-Key Lock 的退化
与上面的场景类似,考虑如下场景:

注意到,与上一个例子的不同之处是,此场景下,session A 的查询条件为 id。此时,session B 并不会被阻塞,这是否与前面的讨论矛盾呢?
事实上这是索引记录的加锁的特殊情况: 对于索引上的等值查询,如果是唯一索引,且扫描到对应的索引记录,则 Next-Key lock 退化为行锁。
继续考虑如下场景:

按照前面的描述,此时 session A 应该在 tb_test 表的 idx_cnt 索引上加 Next-Key lock,即 (15,20] 。但是,观察到,此时 session B 会被阻塞,而 session C 的语句可以执行成功。查看锁的情况:
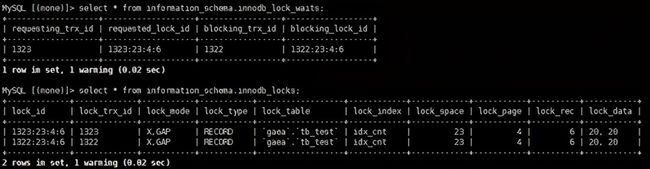
这种场景下: 对于索引上的等值查询,扫描到的最后一个索引记录不符合条件,Next-Key lock 退化为间隙锁。
1.4.5 插入意向锁(Insert Intention Lock)
对于前面讨论的场景:

session B 会被 session A 阻塞,此时通过执行命令 SHOW ENGINE INNODB STATUS 可以观察到:
------- TRX HAS BEEN WAITING 10 SEC FOR THIS LOCK TO BE GRANTED:RECORD LOCKS space id 23 page no 3 n bits 80 index PRIMARY of table `gaea`.`tb_test` trx id 1372 lock_mode X locks gap before rec insert intention waitingRecord lock, heap no 4 PHYSICAL RECORD: n_fields 5; compact format; info bits 0 0: len 4; hex 0000000a; asc ;; 1: len 6; hex 000000000507; asc ;; 2: len 7; hex a70000011b0128; asc (;; 3: len 4; hex 8000000a; asc ;; 4: len 4; hex 8000000a; asc ;;复制代码
复制代码
注意到此时插入操作被阻塞期间,等待的锁为插入意向锁 insert intention 。 插入意向锁实际就是插入操作在进行插入之前获取的一种特殊的间隙锁。
前面讨论的间隙锁的规则,也适用于插入意向锁,即: 插入意向锁之间不会互相阻塞,但插入意向锁与重叠区间的其他间隙锁之间会互相阻塞,这是因为间隙锁的主要目的就是避免在事务未提交前,其他事务在区间内插入新的记录。
1.4.6 小结
综合上面对行级锁的讨论,进行小结:
-
InnoDB 行级锁加锁的基本单位是 Next-Key lock.
-
加锁的对象为语句执行过程中的索引记录。
-
对于索引上的等值查询,如果是唯一索引,且扫描到对应的索引记录,则 Next-Key lock 退化为行锁。
-
对于索引上的等值查询,扫描到的最后一个索引记录不符合条件,Next-Key lock 退化为间隙锁。
-
间隙锁之间不会相互阻塞,其目的主要为避免并发的其他会话在区间内插入新的记录。
-
插入意向锁是 INSERT 操作获取的一种特殊间隙锁,插入意向锁之间不会相互阻塞,但与其他间隙锁之间会相互阻塞。
2 不同语句锁类型
2.1 锁定读、UPDATE 及 DELETE
对于锁定读( SELECT ... LOCK IN SHARE MODED / SELECT ... FOR UPDATE )以及 UPDATE 、 DELETE 操作,InnoDB 会在所有扫描到的索引记录上添加行级锁。需要注意的是添加行级锁的范围与 WHERE 条件没有关系。
如前面讨论的,这里的行级锁通常为 Next-Key lock,只有在索引等值查询的时候会退化。因此,应该对表的索引进行仔细设计,同时注意语句的执行计划,避免锁定大范围的数据。
假设某些语句不走索引,那么 InnoDB 将不得不进行全表扫描,这将导致所有记录及其之间的间隙锁定。此时将不能在表中插入记录。例如,如下的查询,虽然是等值查询,但是其执行计划为全表扫描,其他并发的插入将均被阻塞。
mysql> explain select * from tb_test where value=7 for update;+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+| 1 | SIMPLE | tb_test | NULL | ALL | NULL | NULL | NULL | NULL | 5 | 20.00 | Using where |+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
复制代码
复制代码
2.2 INSERT
如前面讨论, INSERT 首先会获取插入意向锁,这是一种区间锁,如果对应区间已经被锁定,那么 INSERT 操作将无法继续执行。如果获取插入意向锁成功,那么 INSERT 将继续执行,同时会获取插入记录上的行锁。
插入过程中,如果发生索引冲突 DUPLICATE KEY ERROR ,此时插入操作将会获取对应索引记录上共享锁。这有可能导致死锁的发生。考虑如下场景。

session A 首先获取主键记录 1 上的排他锁,接下来 session B 和 session C 的插入操作都会得到主键冲突,因此会各自获取主键记录上的共享锁。然后 session A 回滚,此时 session B 和 session C 都尝试获取排他锁,但是被对方的共享锁阻塞,从而发生死锁。
2.3 复杂语句
与 INSERT 不同, INSERT ... ON DUPLICATE KEY UPDATE ... 在出现主键冲突需要执行更新操作时,会获取排他锁。当扫描的记录是主键时,Next-Key lock 退化为行锁。
INSERT INTO T SELECT ... FROM S WHERE... 语句会在表 T 上针对插入的每行获取行锁,此时并不会获取间隙锁。在表 S 上,会对扫描到的记录获取 Next-Key lock。
3 死锁
3.1 概念及示例
数据库中的死锁与一般意义上的死锁并没有区别,出现的条件可以简要描述为:
两个独立的过程(线程、事务等)在执行过程中,获取锁时出现了闭环的循环等待。
考察如下产生死锁的场景:

分析上述会话,session A 第一条 delete 语句,会获取 Next-Key lock,由于查询条件 id 是唯一索引,因此会退化为间隙锁(表中并不存在对应的记录,不会退化为行锁): (5, 10) ; 同样地,session B 的 delete 语句也会获取间隙锁。
由于间隙锁之间不会冲突,因此两个会话的 delete 语句都成功获取锁。接下来,session A 执行插入操作,获取插入意向锁,被 session B 获取的间隙锁阻塞,接着 session B 同样执行插入操作,被 session A 阻塞。此时产生死锁,某一个会话的事务被回滚。另一个会话的插入操作则执行成功。
3.2 死锁应对
在支持事务的数据库中,死锁是一个常见的问题。死锁问题并不是绝对不能发生的危险问题,只要不因频繁发生死锁而大面积影响业务,对小概率发生死锁的情况,进行提前设计可以有效应对。
-
仔细设计 SQL,避免间隙锁加在较大的区间。较大的区间意味着更高的并发写入概率,从而会提高死锁发生的概率。
例如,对于 2.1 中所举的例子,将 SQL 改写为 INSERT INTO ... ON DUPLICATE KEY UPDATE... . 如果没有对应的数据,不同行的插入,插入意向锁不会相互阻塞;如果有重复主键数据,则 UPDATE 操作属于唯一索引上的等值查询,此时间隙锁退化为行锁。
-
优化业务流程,降低事务的总执行时间。通过降低事务的执行时间,降低了事务之间并发的可能性,从而一定程度上降低死锁发生的概率。
例如,在设计数据结构和业务流程时,避免在一个长事务中操作多张表。
又例如,避免在事务当中引入其他网络调用操作,因为网络调用的时间通常会远高于本地调用。
-
如果可能,适当降低隔离级别。InnoDB 默认隔离级别为 REPEATABLE READ ,在某些高查询低写入、业务流程相对简单或者容忍幻读的应用场景中,可以将隔离级别设置为 READ COMMITTED ,这不但能够在一定程度上降低死锁发生的概率,还能有效提升数据库能够提供的并发能力。
例如,对于 2.1 中所举的例子,将数据库的隔离级别设置为 READ COMMITTED 则不会发生死锁。
-
对于 SELECT ... LOCK IN SHARE MODE 和 SELECT ... FOR UPDATE ,如果查询读取的记录为单行,也可以降低事务隔离级别至 READ COMMITTED 。此时已通过命令显式加锁,无需更高的隔离级别。
对于上面两条建议,需要注意:
当将隔离级别设置为 READ COMMITTED 时,意味着容忍幻读的发生,此时间隙锁不生效,并发会话可能插入并不存在的数据,导致前后读取的记录数不一致。
-
仔细设计表的索引。通过良好设计的索引降低事务扫描的记录数,从而降低死锁的概率。
-
对于可能发生的死锁,还需要设计重试机制。万一产生死锁,通过重试机制确保数据可以最终写入成功。