Mysql进阶操作:数据库表约束,分组查询,数据库表关系,多表联查
文章目录
- 数据库表约束
-
- 数据库表的扩展属性
- 数据库表关系
-
- E-R图
- 三大范式
- 分组查询
-
- 聚合函数
- having子句
- 多表联查
-
-
- 内连接:inner join
- 外连接:
-
- 左连接:left join
- 右连接:right join
- 自连接
- 子查询
-
- 单行子查询:返回一行记录的子查询
- 多行子查询:返回多行记录的子查询
-
- 索引
- 事务
数据库表约束
数据库表约束:对数据库表中某一字段的约束(如:唯一约束,非NULL约束…)
唯一约束 unique:指定该列中的数据唯一,不能出现重复
create table if not exists tb_class (id int unique,name varchar(5));
非NULL约束:指定某一列不能为空
create table if not exists tb_class (id int NOT NULL,name varchar(5));-----设定课程id为整型,并且非空
主键约束 primary key:非空且唯一;
- 相较于unique和not null,可以将多个列设置为主键-----组合主键;
- 组合主键中所有的数据都相同才算重复;
- 一张表中只能有一个主键
create table if not exists tb_class (id int primary key,name varchar(5));-----将id设置为主键
create table if not exists tb_class (id int ,name varchar(5),primary key(id,name));----将id和name设置为组合主键
外键约束:用于关联其他表的主键或唯一键,表示当前表中指定字段的数据受到其他表中指定字段的约束
例如:假设现在有两个表:课程表(课程号,教师…)和选课表(课程号-----设为外键,受限于课程表中的课程号…),如果想要在选课表中插入一条数据,那么这条数据中的课程号必须要在课程表中存在
check 子句:check子句在mysql中可以写并且不会报错,但实际并不会生效
create table tb_stu(id int primary key,sex varchar(1),check(sex='男’or sex=‘女’));-----check子句在次数约束:性别必须为男或女;
数据库表的扩展属性
auto_increment:自增属性,这一字段必须是数字
default:默认值,如果指定字段设置了默认值,则在没有插入数据的情况下,会插入默认数据
comment:每一个字段的注释,让我们字以后查看表结构时能够通过注释了解字段的相关信息
create table if not exists student(
id int primary key auto_increment comment ‘学生信息id’,
sn int not null unique comment ‘学号’,
name varchar(32) comment ‘姓名’,
qq_emil varchar(32) default ‘[email protected]’ comment ‘QQ邮箱’,
classes_id int comment ‘所在班级id’,
foreign key(classes_id) references classes(id)
);

数据库表关系
E-R图
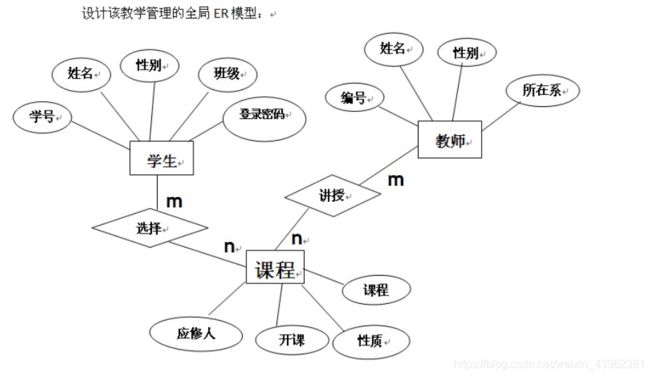
E-R图也称实体-联系图(Entity Relationship Diagram),提供了表示实体类型、属性和联系的方法,用来描述现实世界的概念模型。
用“矩形框”表示实体型,矩形框内写明实体名称;用“椭圆图框”或圆角矩形表示实体的属性,并用“实心线段”将其与相应关系的“实体型”连接起来;用”菱形框“表示实体型之间的联系成因,在菱形框内写明联系名,并用”实心线段“分别与有关实体型连接起来,同时在”实心线段“旁标上联系的类型(1:1,1:n或m:n)。例如:
三大范式
三大范式是用于规范数据库表设计的,减少数据库中数据的冗余,以提高查询和传输的性能。
第一范式:要求数据库表中的每一列都是不可分割的原子性数据。
第二范式: 确保表中的每一列数据都与主键相关,而不能与主键的一部分相关-----主要针对组合主键
第三范式:表中的每一列数据都应该与主键直接相关,而不能间接相关
分组查询
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。需要满足:使用 GROUP BY 进行分组查询时,SELECT指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中。
select column1, sum(column2), … from table group by column1,column3;
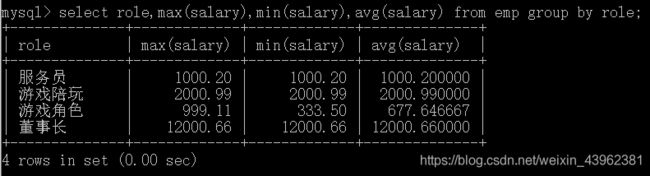
例如:查询每个职位的最高工资、最低工资和平均工资
select role,max(salary),min(salary),avg(salary) from emp group by role;
聚合函数
常见的统计总数、计算平局值等操作,可以使用聚合函数来实现,常见的聚合函数有:
| 函数 | 说明 |
|---|---|
| COUNT(fields) | 返回查询到的数据的 数量 |
| SUM(fields) | 返回查询到的数据的总和 |
| AVG(fields) | 返回查询到的数据的 平均值 |
| MAX(fields) | 返回查询到的数据的数据的最大值 |
| MIN(fields) | 返回查询到的数据的最小值 |
having子句
分组查询时,要进行条件过滤,不能使用where子句,而是使用having子句
例如:要查询平均薪资大于1000的岗位,应该使用如下语句:
select role, avg(salary) from emp group by role having avg(salary)>1000;

多表联查
实际开发中往往数据来自不同的表,所以需要多表联合查询。多表查询是对多张表的数据取笛卡尔积:

如何将多张表中的数据通过语句进行合并:
内连接:inner join
内连接:指连接结果取两张表中数据的交集。
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
外连接:
外连接:连接结果不仅包含符合连接条件的行同时也包含自身不符合条件的行。常见的有左外连接、右外连接
左连接:left join
以左表为基准,找符合条件的数据,如果右表中没有符合条件的数据,就以NULL展示。
– 左外连接,左表完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
右连接:right join
以右表为基准,找符合条件的数据,如果左表中没有符合条件的数据,就以NULL展示。
– 右外连接,右表完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;
举例说明:内连接,左连接,外连接

自连接
该表自己和自己进行连接;需要使用别名进行显示

多表联查实例:

子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
单行子查询:返回一行记录的子查询
select * from student where classes_id=(select classes_id from student where name=‘不想毕
业’);
多行子查询:返回多行记录的子查询
1.[NOT] IN 关键字
– 使用IN
select * from score where course_id in (select id from course where name=‘语文’ or
name=‘英文’);
– 使用 NOT IN
select * from score where course_id not in (select id from course where name!=‘语文’
and name!=‘英文’);w
2.[NOT] EXISTS关键字:
– 使用 EXISTS
select * from score sco where exists (select sco.id from course cou where (name=‘语 文’ or name=‘英文’) and cou.id = sco.course_id);
– 使用 NOT EXISTS
select * from score sco where not exists (select sco.id from course cou where
(name!=‘语文’ and name!=‘英文’) and cou.id = sco.course_id);
索引
索引:索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。
索引保存的数据结构主要为B+树,及hash的方式。
对于数据库中的数据来说起着类似于目录一样的功能,通过索引可以快速地检索数据的位置;索引是提高数据库海量数据查询效率的关键信息
创建主键、唯一键、外键都会伴随着为对应字段添加索引
应用场景:
- 海量数据,并且该列经常被查询
- 该列的修改和删除的概率较低
- 索引会占用额外的磁盘空间,会创建索引信息表,因此索引不是越多越好
创建索引:create index index_name on table_name(fields);
删除索引:drop index index_name on table_name ;
查看索引:show index from table_name;
事务
事务:事务指逻辑上的一组操作-----原子操作,组成这组操作的各个单元,要么全部成功,要么全部失败。在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务。
使用方法:
(1)开启事务:start transaction;
(2)执行多条SQL语句
(3)回滚或提交:rollback/commit
说明:rollback是全部失败,commit是全部成功。