多元线性回归算法预测房价
多元线性回归算法预测房价
- 一、理论学习
-
- (一)背景
- (二)线性回归检验
- 二、数据清洗
-
- (一)数值数据处理
- (二)非数值型数据转换
- 三、Excel多元线性回归
- 四、多元线性回归模型预测房价
-
- (一)基础包与数据导入
- (二)变量探索
- (三)分析数据
- (四)拟合
- 四、sklearn多元线性回归预测房价
-
- (一)不进行数据处理
- (二)对数据进行清洗后再求解
- 五、总结
- 六、参考资料
一、理论学习
学习参考资料“多元线性回归模型预测房价.ipynb”,自己实践重新做一下针对房屋数据集“house_prices.csv”的多元线性回归(基于统计分析库statsmodels);并重点理解偏差数据、缺少数据的预处理(数据清洗)、“特征共线性”的检测方法以及统计学的传统估计参数。
(一)背景
波士顿房价数据集包括多个样本,每个样本包括多个特征变量和该地区的平均房价。房价(单价)显然和多个特征变量相关,不是单变量线性回归(一元线性回归)问题;选择多个特征变量来建立线性方程,这就是多变量线性回归(多元线性回归)问题。
房价和多个特征变量相关,本案例尝试使用多元线性回归建模

(二)线性回归检验
在正态假定下,如果X是列满秩的,则普通线性回归模型的参数最小二乘估计为:

于是y的估计值为:

(1)回归方程的显著性检验

(2)回归系数的显著性检验

二、数据清洗
(一)数值数据处理
1.数据集主要问题
(1)数据缺失
(2)数据不一致
(3)存在“脏”数据
(4)数据不规范
数据整体较为规整,但通过初步观察,该数据集主要存在如下问题:数据缺失,存在某些数据等于0
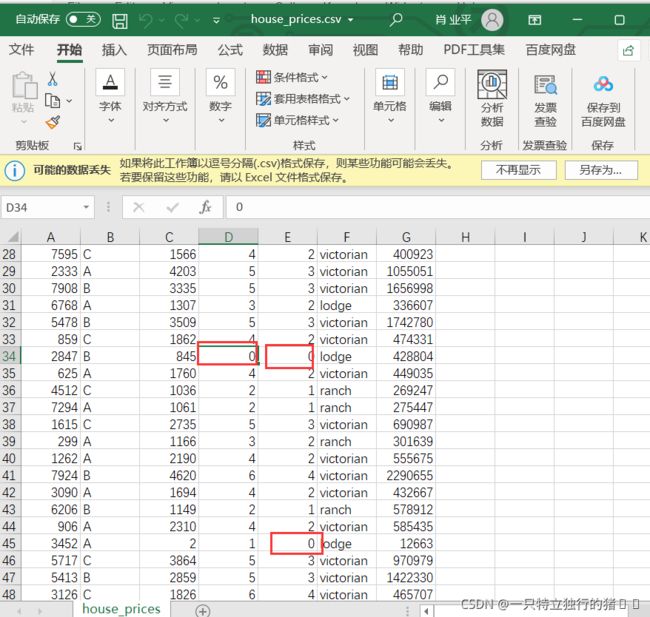
2、删除重复数据
(1)在 Excel 中新建一个工作表house_prices_new.csv执行数据清洗,方便和原始数据区分开来,选中需要处理的数据

(2)选择数据——数据工具——删除重复值
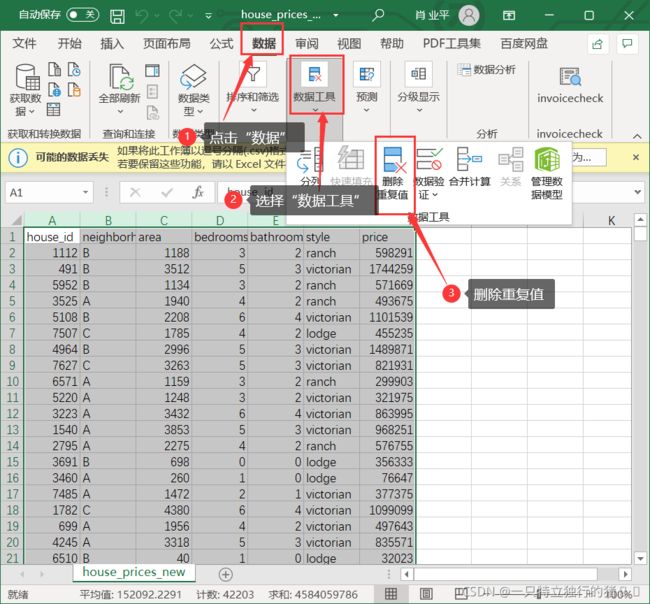
(3)利用唯一标识house_id,删除重复值

会发现没有重复数据

3.升序排列,选择筛选和排序——升序


4,缺失值处理
- 通过人工手动补全,适合与缺失值比较少
- 删除缺失数据
- 用列表平均值代替缺失值
- 用统计模型计算出来的值代替缺失值
本题删除所有值为0的,缺失值所在行
(1)选中地址列的数据区域即bedrooms所在的列

(2)采用选择菜单:点击数据——筛选——图中下拉三角形

(3)筛选值为0

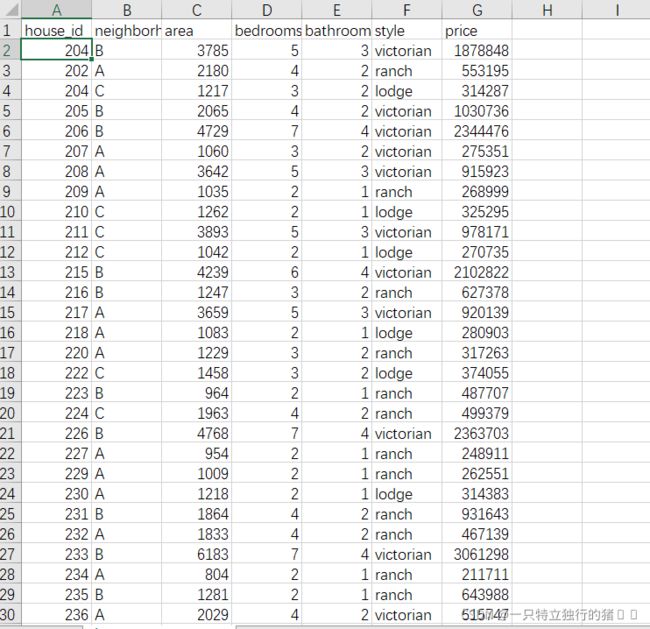
(4)选中删除bedrooms值为0的所有行

(5)以同样的方法删除bathrooms值为0的行
结果如下
(二)非数值型数据转换
在原始数据中,
neighborhood和style为非数值型数据。需要转换成数值型数据才能够进行回归分析。
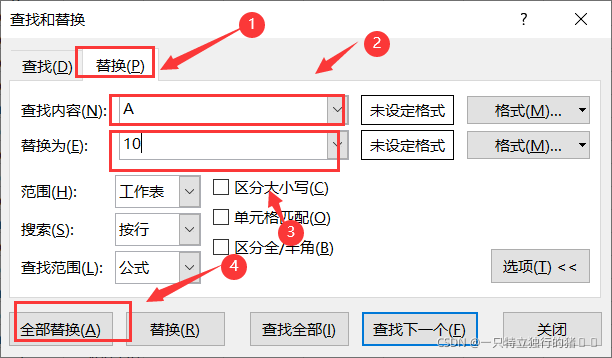
(1)开始——查找和替换——替换

(2)选中neighborhood所在的列进行替换,把原数据的A、B、C替换为10、20、30
(3)替换成功

(4)以同样的方式替换style,将原数据的victorian、ranch、lodge替换为100、200、300
(5)替换结果
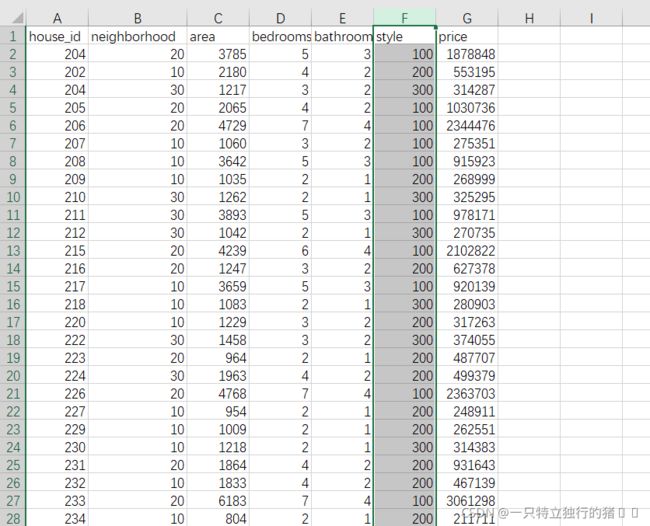
三、Excel多元线性回归
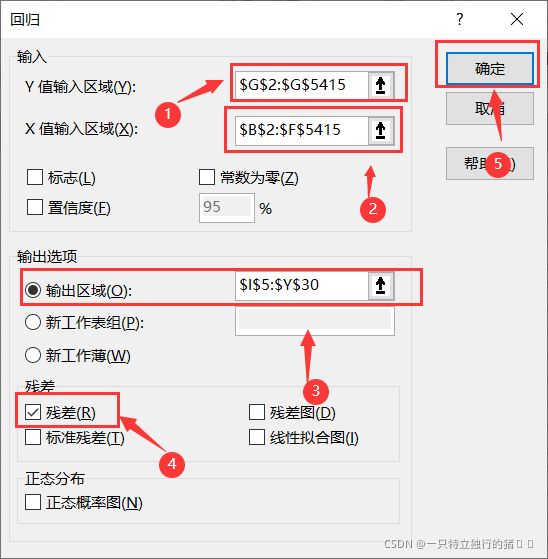
1.选择数据——数据分析——回归——确定

2.以X和Y值区间
①以
price作为Y值输入区间
②以neighborhood、area、bedrooms、bathrooms、style作为X值输入区间
③输出显示区域选择
④勾选残差
⑤点击确定
3.输出结果

四、多元线性回归模型预测房价
(一)基础包与数据导入
1.导入包
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
2.读取文件house_prices.csv’数据
(1)代码
df = pd.read_csv('C:/Users/86199/Jupyter/house_prices.csv')
df.info(); df.head()
(2)输出结果

(二)变量探索
1.数据处理
# 异常值处理
# ================ 异常值检验函数:iqr & z分数 两种方法 =========================
def outlier_test(data, column, method=None, z=2):
""" 以某列为依据,使用 上下截断点法 检测异常值(索引) """
"""
full_data: 完整数据
column: full_data 中的指定行,格式 'x' 带引号
return 可选; outlier: 异常值数据框
upper: 上截断点; lower: 下截断点
method:检验异常值的方法(可选, 默认的 None 为上下截断点法),
选 Z 方法时,Z 默认为 2
"""
# ================== 上下截断点法检验异常值 ==============================
if method == None:
print(f'以 {column} 列为依据,使用 上下截断点法(iqr) 检测异常值...')
print('=' * 70)
# 四分位点;这里调用函数会存在异常
column_iqr = np.quantile(data[column], 0.75) - np.quantile(data[column], 0.25)
# 1,3 分位数
(q1, q3) = np.quantile(data[column], 0.25), np.quantile(data[column], 0.75)
# 计算上下截断点
upper, lower = (q3 + 1.5 * column_iqr), (q1 - 1.5 * column_iqr)
# 检测异常值
outlier = data[(data[column] <= lower) | (data[column] >= upper)]
print(f'第一分位数: {q1}, 第三分位数:{q3}, 四分位极差:{column_iqr}')
print(f"上截断点:{upper}, 下截断点:{lower}")
return outlier, upper, lower
# ===================== Z 分数检验异常值 ==========================
if method == 'z':
""" 以某列为依据,传入数据与希望分段的 z 分数点,返回异常值索引与所在数据框 """
"""
params
data: 完整数据
column: 指定的检测列
z: Z分位数, 默认为2,根据 z分数-正态曲线表,可知取左右两端的 2%,
根据您 z 分数的正负设置。也可以任意更改,知道任意顶端百分比的数据集合
"""
print(f'以 {column} 列为依据,使用 Z 分数法,z 分位数取 {z} 来检测异常值...')
print('=' * 70)
# 计算两个 Z 分数的数值点
mean, std = np.mean(data[column]), np.std(data[column])
upper, lower = (mean + z * std), (mean - z * std)
print(f"取 {z} 个 Z分数:大于 {upper} 或小于 {lower} 的即可被视为异常值。")
print('=' * 70)
# 检测异常值
outlier = data[(data[column] <= lower) | (data[column] >= upper)]
return outlier, upper, lower
2.调用函数
outlier, upper, lower = outlier_test(data=df, column='price', method='z')
outlier.info(); outlier.sample(5)
3.删除错误数据
# 这里简单的丢弃即可
df.drop(index=outlier.index, inplace=True)
(三)分析数据
1.定义变量
# 类别变量,又称为名义变量,nominal variables
nominal_vars = ['neighborhood', 'style']
for each in nominal_vars:
print(each, ':')
print(df[each].agg(['value_counts']).T)
# 直接 .value_counts().T 无法实现下面的效果
## 必须得 agg,而且里面的中括号 [] 也不能少
print('='*35)
# 发现各类别的数量也都还可以,为下面的方差分析做准备

2.热力图查看变量关联性
# 热力图
def heatmap(data, method='pearson', camp='RdYlGn', figsize=(10 ,8)):
"""
data: 整份数据
method:默认为 pearson 系数
camp:默认为:RdYlGn-红黄蓝;YlGnBu-黄绿蓝;Blues/Greens 也是不错的选择
figsize: 默认为 10,8
"""
## 消除斜对角颜色重复的色块
# mask = np.zeros_like(df2.corr())
# mask[np.tril_indices_from(mask)] = True
plt.figure(figsize=figsize, dpi= 80)
sns.heatmap(data.corr(method=method), \
xticklabels=data.corr(method=method).columns, \
yticklabels=data.corr(method=method).columns, cmap=camp, \
center=0, annot=True)
# 要想实现只是留下对角线一半的效果,括号内的参数可以加上 mask=mask
3.调用函数输出结果
# 通过热力图可以看出 area,bedrooms,bathrooms 等变量与房屋价格 price 的关系都还比较强
## 所以值得放入模型,但分类变量 style 与 neighborhood 两者与 price 的关系未知
heatmap(data=df, figsize=(6,5))

(四)拟合
1.引入模型
(1) 刚才的探索我们发现,style 与 neighborhood 的类别都是三类, 如果只是两类的话我们可以进行卡方检验,所以这里我们使用方差分析
利用回归模型中的方差分析,只有 statsmodels 有方差分析库, 从线性回归结果中提取方差分析结果
1)代码
import statsmodels.api as sm
from statsmodels.formula.api import ols # ols 为建立线性回归模型的统计学库
from statsmodels.stats.anova import anova_lm
2)结果

(2)数据集样本随机选择 600 条
1)代码
df = df.copy().sample(600)
# C 表示告诉 Python 这是分类变量,否则 Python 会当成连续变量使用
## 这里直接使用方差分析对所有分类变量进行检验
## 下面几行代码便是使用统计学库进行方差分析的标准姿势
lm = ols('price ~ C(neighborhood) + C(style)', data=df).fit()
anova_lm(lm)
# Residual 行表示模型不能解释的组内的,其他的是能解释的组间的
# df: 自由度(n-1)- 分类变量中的类别个数减1
# sum_sq: 总平方和(SSM),residual行的 sum_eq: SSE
# mean_sq: msm, residual行的 mean_sq: mse
# F:F 统计量,查看卡方分布表即可
# PR(>F): P 值
# 反复刷新几次,发现都很显著,所以这两个变量也挺值得放入模型中
2)结果

2.多元线性回归建模
(1)代码
from statsmodels.formula.api import ols
lm = ols('price ~ area + bedrooms + bathrooms', data=df).fit()
lm.summary()
(2)输出结果
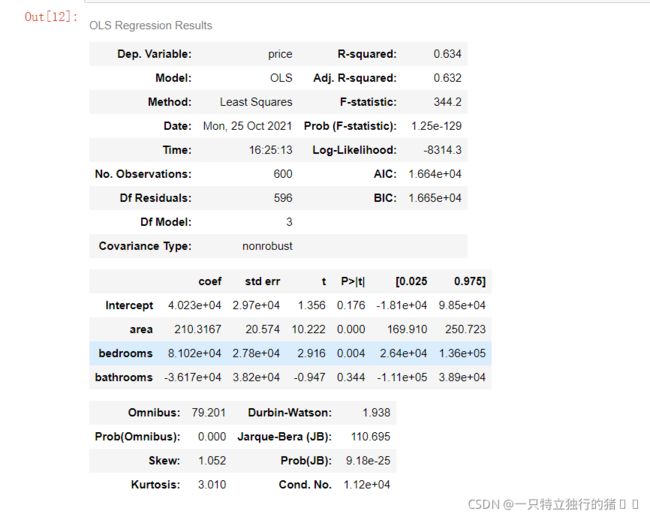
3.模型优化
(1)发现精度还不够高,这里通过添加虚拟变量与使用方差膨胀因子检测多元共线性的方式来提升模型精度
# 设置虚拟变量
# 以名义变量 neighborhood 街区为例
nominal_data = df['neighborhood']
# 设置虚拟变量
dummies = pd.get_dummies(nominal_data)
dummies.sample() # pandas 会自动帮你命名
# 每个名义变量生成的虚拟变量中,需要各丢弃一个,这里以丢弃C为例
dummies.drop(columns=['C'], inplace=True)
dummies.sample()

(2)结果与原数据集拼接
# 将结果与原数据集拼接
results = pd.concat(objs=[df, dummies], axis='columns') # 按照列来合并
results.sample(3)
# 对名义变量 style 的处理可自行尝试
(3)输出结果

4.再次建模
(1)代码
# 再次建模
lm = ols('price ~ area + bedrooms + bathrooms + A + B', data=results).fit()
lm.summary()
(2)结果

5.处理多元共线性
(1)#自定义方差膨胀因子的检测公式
def vif(df, col_i):
"""
df: 整份数据
col_i:被检测的列名
"""
cols = list(df.columns)
cols.remove(col_i)
cols_noti = cols
formula = col_i + '~' + '+'.join(cols_noti)
r2 = ols(formula, df).fit().rsquared
return 1. / (1. - r2)
(2)函数调用
test_data = results[['area', 'bedrooms', 'bathrooms', 'A', 'B']]
for i in test_data.columns:
print(i, '\t', vif(df=test_data, col_i=i))
# 发现 bedrooms 和 bathrooms 存在强相关性,可能这两个变量是解释同一个问题
(3)结果

6.再次拟合
bedrooms 和 bathrooms 这两个变量的方差膨胀因子较高,印证了方差膨胀因子大多成对出现的原则,这里我们丢弃膨胀因子较大的
bedrooms 即可
(1)代码
lm = ols(formula='price ~ area + bathrooms + A + B', data=results).fit()
lm.summary()
(2)输出结果

(3)还是存在多元共线性,再次检测
test_data = df[['area', 'bathrooms']]
for i in test_data.columns:
print(i, '\t', vif(df=test_data, col_i=i))
(4)结果输出

(5)发现精度没变,但具体问题还是需要结合具体业务来分析
四、sklearn多元线性回归预测房价
(一)不进行数据处理
1.导入包和数据
(1)代码
import pandas as pd
import numpy as np
import math
import matplotlib.pyplot as plt # 画图
from sklearn import linear_model # 线性模型
data = pd.read_csv('C:/Users/86199/Jupyter/house_prices_second.csv') #读取数据
data.head() #数据展示
(2)显示结果

2.去除第一列house_id
(1)代码
new_data=data.iloc[:,1:] #除掉id这一列
new_data.head()
(2)结果

3.关系系数矩阵显示
new_data.corr() # 相关系数矩阵,只统计数值列
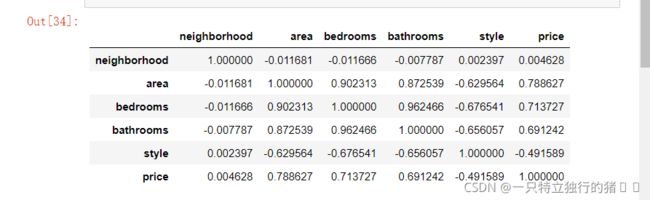
4.赋值变量
(1)代码
x_data = new_data.iloc[:, 0:5] #area、bedrooms、bathroom对应列
y_data = new_data.iloc[:, -1] #price对应列
print(x_data, y_data, len(x_data))
(2)结果

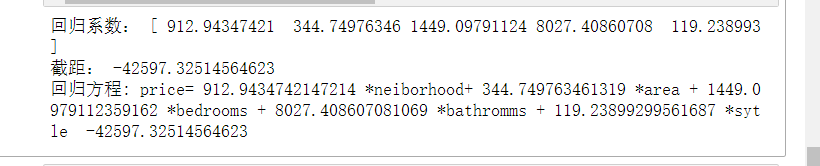
5.建立模型并输出结果
# 应用模型
model = linear_model.LinearRegression()
model.fit(x_data, y_data)
print("回归系数:", model.coef_)
print("截距:", model.intercept_)
print('回归方程: price=',model.coef_[0],'*neiborhood+',model.coef_[1],'*area +',model.coef_[2],'*bedrooms +',model.coef_[3],'*bathromms +',model.coef_[4],'*sytle ',model.intercept_)
(二)对数据进行清洗后再求解
1.赋值新变量
new_data_Z=new_data.iloc[:,0:]
new_data_IQR=new_data.iloc[:,0:]
2.异常值处理
# ================ 异常值检验函数:iqr & z分数 两种方法 =========================
def outlier_test(data, column, method=None, z=2):
""" 以某列为依据,使用 上下截断点法 检测异常值(索引) """
"""
full_data: 完整数据
column: full_data 中的指定行,格式 'x' 带引号
return 可选; outlier: 异常值数据框
upper: 上截断点; lower: 下截断点
method:检验异常值的方法(可选, 默认的 None 为上下截断点法),
选 Z 方法时,Z 默认为 2
"""
# ================== 上下截断点法检验异常值 ==============================
if method == None:
print(f'以 {column} 列为依据,使用 上下截断点法(iqr) 检测异常值...')
print('=' * 70)
# 四分位点;这里调用函数会存在异常
column_iqr = np.quantile(data[column], 0.75) - np.quantile(data[column], 0.25)
# 1,3 分位数
(q1, q3) = np.quantile(data[column], 0.25), np.quantile(data[column], 0.75)
# 计算上下截断点
upper, lower = (q3 + 1.5 * column_iqr), (q1 - 1.5 * column_iqr)
# 检测异常值
outlier = data[(data[column] <= lower) | (data[column] >= upper)]
print(f'第一分位数: {q1}, 第三分位数:{q3}, 四分位极差:{column_iqr}')
print(f"上截断点:{upper}, 下截断点:{lower}")
return outlier, upper, lower
# ===================== Z 分数检验异常值 ==========================
if method == 'z':
""" 以某列为依据,传入数据与希望分段的 z 分数点,返回异常值索引与所在数据框 """
"""
params
data: 完整数据
column: 指定的检测列
z: Z分位数, 默认为2,根据 z分数-正态曲线表,可知取左右两端的 2%,
根据您 z 分数的正负设置。也可以任意更改,知道任意顶端百分比的数据集合
"""
print(f'以 {column} 列为依据,使用 Z 分数法,z 分位数取 {z} 来检测异常值...')
print('=' * 70)
# 计算两个 Z 分数的数值点
mean, std = np.mean(data[column]), np.std(data[column])
upper, lower = (mean + z * std), (mean - z * std)
print(f"取 {z} 个 Z分数:大于 {upper} 或小于 {lower} 的即可被视为异常值。")
print('=' * 70)
# 检测异常值
outlier = data[(data[column] <= lower) | (data[column] >= upper)]
return outlier, upper, lower
3.price 列为依据,使用 Z 分数法,z 分位数取 2 来检测异常值
outlier, upper, lower = outlier_test(data=new_data_Z, column='price', method='z')
outlier.info(); outlier.sample(5)
# 这里简单的丢弃即可
new_data_Z.drop(index=outlier.index, inplace=True)

4. price 列为依据,使用 上下截断点法(iqr) 检测异常值
outlier, upper, lower = outlier_test(data=new_data_IQR, column='price')
outlier.info(); outlier.sample(6)
# 这里简单的丢弃即可
new_data_IQR.drop(index=outlier.index, inplace=True)

5.输出原数据相关矩阵
print("原数据相关性矩阵")
new_data.corr()
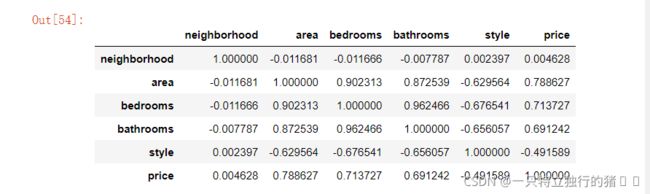
6.Z方法处理的数据相关性矩阵
在这里插入代码片print("Z方法处理的数据相关性矩阵")
new_data_Z.corr()

7.IQR方法处理的数据相关性矩阵
print("IQR方法处理的数据相关性矩阵")
new_data_IQR.corr()

8.建模输出
x_data = new_data_Z.iloc[:, 0:5]
y_data = new_data_Z.iloc[:, -1]
# 应用模型
model = linear_model.LinearRegression()
model.fit(x_data, y_data)
print("回归系数:", model.coef_)
print("截距:", model.intercept_)
print('回归方程: price=',model.coef_[0],'*neiborhood+',model.coef_[1],'*area +',model.coef_[2],'*bedrooms +',model.coef_[3],'*bathromms +',model.coef_[4],'*sytle ',model.intercept_)

五、总结
本次实验了解了多元回归模型的相关概念,构建模型的基本步骤。学会了如何用Excel表构建多元回归模型,其实更一元线性回归所用方法很相似,唯一不同的点就是X值区间的选择,由一元线性回归的单个变量变为多个。更加熟悉使用sklearn库调用函数的方法,了解了一些处理数据的基本方法,包括处理缺省值和非数值数据的处理方法等。
六、参考资料
多元线性回归—波士顿房价预测(版本一)
多元线性回归模型
数据清洗技术——Excel数据清洗
excel数据清洗_数据清洗步骤
【机器学习】机器学习之多元线性回归
sklearn多元线性回归预测房价