Intelligent Fault Diagnosis of Machines with Small & Imbalanced Data: Review | 小样本及不平衡数据下的智能故障诊断: 综述
本文是对智能故障诊断领域最新综述文章:Intelligent Fault Diagnosis of Machines with Small & Imbalanced Data: A State-of-the-art Review and Possible Extensions 的翻译,欢迎各位同行前来交流!
- 相关链接
- Abstract
- Introduction
- Research Methodology and Initial Analysis
-
- Research Methodology
- Initial Analysis
- Data Augmentation-based Strategy for S&I-IFD
- Feature Learning-based Strategy for S&I-IFD
- Classifier Design-based Strategy for S&I-IFD
- Future Challenges and Possible Extensions for S&I-IFD
- Conclusions
相关链接
原文:https://www.sciencedirect.com/science/article/pii/S0019057821001257
ResearchGate: https://www.researchgate.net/publication/349909446_Intelligent_fault_diagnosis_of_machines_with_small_imbalanced_data_A_state-of-the-art_review_and_possible_extensions
知乎:https://zhuanlan.zhihu.com/p/353641313
Abstract
基于人工智能技术,智能故障诊断的研究取得了显著的成果。在工程场景中,机器通常在正常状态下工作,这意味着可以收集到的故障数据有限。小样本及不平衡数据下的智能故障诊断(S&I-IFD),是指利用有限的机器故障样本建立智能诊断模型,以实现精确的故障识别,已经引起了研究人员的关注。目前,关于 S&I-IFD 的研究已经取得了丰硕的成果,但仍缺乏对最新成果的综述,未来的研究方向也不够明确。针对这一问题,本文对 S&I-IFD 的研究成果进行了回顾,并提供了一些未来的展望。现有的研究成果主要分为三类:基于数据增强的策略、基于特征学习的策略和基于分类器设计的策略。基于数据增强的策略通过增强训练数据来提高诊断模型的性能。基于特征学习的策略通过从小样本及不平衡数据中提取特征来准确识别故障。基于分类器设计的策略通过构建适合小样本&不平衡数据的分类器,实现高诊断精度。最后,本文指出了 S&I-IFD 面临的研究挑战,并提供了一些可能带来突破的方向,包括元学习和零样本学习。
关键词:智能故障诊断;小样本数据;不平衡数据;数据增强;特征学习;分类器设计;元学习;零样本学习 | Intelligent fault diagnosis; Small & imbalanced data; Data augmentation; Feature learning; Classifier design; Meta-learning; Zero-shot learning;
Introduction
故障诊断在机器健康管理中起着至关重要的作用,因为它在机器监测数据和其健康状况之间搭建了一座桥梁。智能故障诊断利用人工智能技术使故障诊断过程智能化、自动化[1]。近来,深度自动编码器(DAE)[2,3]、深度卷积神经网络(DCNN)[4,5]等深度神经网络[6,7]被广泛应用于构建端到端的智能诊断模型,减少了对人工经验和专家知识的依赖,极大地促进了智能故障诊断的发展[8]。 小样本及不平衡数据下的智能故障诊断(S&I-IFD)是指利用少量的故障数据建立智能诊断模型,以实现准确的机器故障识别。一般来说,基于深度神经网络的智能诊断模型建立在对海量机器监测数据的分析上[8]。训练数据越充分,训练集中的故障类型越丰富,智能诊断模型的诊断性能越好。然而,在工程场景中,由于以下三个原因,很难建立一个理想的数据集用于智能诊断模型的训练。
- 在工程场景中,机器通常都是在正常状态下工作,故障很少发生。尽管状态监测系统可以不断地采集机器的运行监测数据,但采集到的数据大部分是健康数据,故障数据的量较小。因此,很难直接从工程场景中获取足够的故障数据来支持智能诊断模型的训练。
- 在实验室中进行故障模拟实验以收集故障数据的成本很高。例如,为了在实验室中获得齿轮的故障数据,研究人员需要购买齿轮试样,通过线切割或其他方式人为制造故障。此外,还需要建立故障模拟试验台来收集故障数据。这样的故障模拟实验不仅成本高,而且消耗了大量的人力。另外,一些常见的故障,如齿面胶合,很难通过人工来模拟。因此,在实验室进行故障模拟实验很难收集到足量的故障数据。
- 通过计算机模拟得到的故障数据不够实用。一些故障仿真软件可以模拟设备的故障,并输出故障数据。例如,Gasturb 是一款航空发动机的性能计算软件[9]。研究人员利用 Gasturb 对航空发动机的故障进行模拟,获得故障数据。然而,Gasturb虽然可以进行精确的数学运算,但无法模拟航空发动机复杂的工作环境。不同的工作环境和工作条件对故障数据影响很大。因此,通过仿真获得的故障数据通常不够实用。
如何解决 S&I-IFD 问题是学者们长期以来的研究兴趣。例如,一些研究者利用合成少数类过采样技术(Synthetic Minority Oversampling Technique (SMOTE))[10]扩大故障样本数量,或者利用支持向量机SVM[11]开发故障分类器,使诊断模型在故障数据样本不足的情况下也能够有比较高的识别精度。近来,S&I-IFD 的研究通过新的机器学习算法取得了丰硕的成果。例如,研究人员利用生成对抗网络(GAN)来模拟机器故障样本的数据分布,从而生成更多的故障样本来扩展有限的故障数据集[12]。此外,迁移学习相关的诊断模型将之前学习到的诊断知识重复利用至新的诊断任务中,这样利用少量的故障样本也可以实现准确的故障识别[13]。
目前,在 S&I-IFD 方面已经取得了很多研究成果,但是对于未来发展的研究方向还不够明确,缺乏对现有成果的综述。虽然已经存在一些关于智能故障诊断的综述,但这些综述主要是针对深度学习等一些理论在感应电机等特定对象上的运用[14,15],而没有针对故障数据样本缺乏的问题。毋庸置疑,在现实世界的很多领域,如医疗、金融等领域,小样本及不平衡数据是一个普遍存在的问题[16]。例如,对银行交易系统中的无效交易和金融欺诈的检测也是一个典型的小&不平衡数据问题。因此,许多关于不平衡数据分类的综述也已经发表[16-19]。但是,这些已有的综述对近年来基于 GAN 和迁移学习等新机器学习理论的关注很少。而且,这些现有的综述主要是对研究方法的总结,并没有把机械设备作为一个特殊的研究对象。从数据分析的角度来看,机器监测数据的分析往往涉及到频域分析、时频域分析等,这与其他数据类型例如图像数据的分析有所不同。据笔者所知,类似的 S&I-IFD 的综述论文既没有在考虑中,也没有已经在其他场合发表。因此,有必要对 S&I-IFD 进行综述,总结现有的成果,并给出一些未来进一步探索的方向。
本文的贡献包括两个方面。首先,本文重点研究了智能故障诊断中的小&不平衡数据问题,并回顾了近 10 年来 S&I-IFD 的相关工作。与其他关于小&不平衡数据的综述不同[16-19],本文根据机器故障诊断(MFD)的一般过程,将 S&I-IFD 的成果分为三类:基于数据增强的策略、基于特征学习的策略和基于分类器设计的策略,如图 1 所示。具体来说,机器故障诊断 主要包含三个阶段:数据预处理、特征提取和状态识别[1]。对于 S&I-IFD,也可以从这三个步骤中找到解决方案,如图 1 所示。从数据预处理的角度来看,学者们通过数据生成或数据超采样对有限的故障数据进行扩增,扩增后的数据可以直接用于训练智能诊断模型。在特征提取方面,可以直接从有限的故障数据中设计正则化的神经网络或利用特征自适应来学习故障特征,而无需增强数据。在状态识别方面,可以直接设计适合于小样本&不平衡数据的故障分类器对机器的健康状况进行分类。与其他关于小&不平衡数据学习的综述相比[16-19],所提出的综述具有更强的领域特征,因此,本文可能对该领域的研究者有更大的启发。其次,基于现有的研究成果和最新的机器学习理论,本文提出了未来的研究挑战和进一步发展的方向。具体来说,在数据增强方面,目前的研究主要集中在扩大故障样本的数量上,而如何衡量和提升样本的质量则需要更加关注。如何防止基于迁移学习的诊断模型发生负转移是其应用的关键。此外,作为一种新的机器学习理论,元学习[20]在处理小样本问题上已经初步显示出其优势。因此,元学习理论(Meta-learning)在 S&I-IFD 上的应用可能会大大增加。最后,在完全没有故障样本的极端情况下,零样本学习(Zero-shot learning)[21]可能会为 S&I-IFD 带来突破。
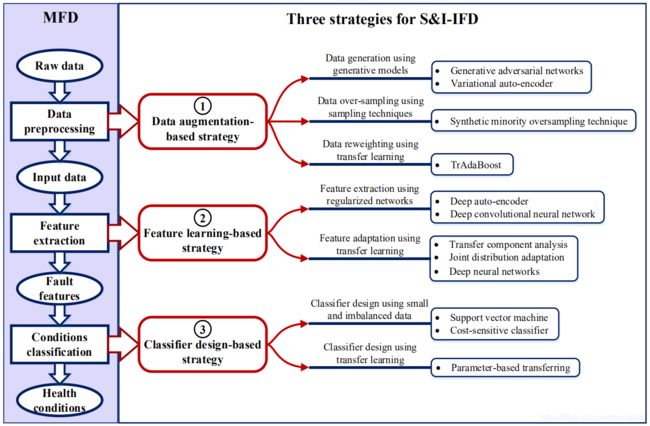
Fig. 1.The process of machine fault diagnosis (MFD) and three strategies for S&I-IFD.
在接下来的内容中,第 2 节介绍了研究方法和初始的数据分析。
第 3、4、5 节分别从数据增强、特征学习和分类器设计的角度回顾了现有的研究成果。
第 6 节给出了未来 S&I-IFD 的一些可能的扩展。
第 7 节给出了本次综述的结论。
Research Methodology and Initial Analysis
Research Methodology
本文主要对 2010 年至 2020 年 11 月发表的有关 S&I-IFD 的文献进行检索和收集。文献检索选择了 4 个自然科学研究领域的图书馆数据库,分别是 Science Direct、IEEE Xplore、Springer 和 ACM。此外,还利用 Scopus 和 Web of Science 对个别出版社的论文进行检索[22]。 受[16]的启发,构建了一个两级关键词树,尽可能全面地收集 S&I-IFD 方面的已发表论文,如图 2 所示。
本文回顾的是小样本&不平衡数据下的智能故障诊断,因此将第一层的检索关键词限定为智能故障诊断。对于 S&I-IFD,由于健康数据量大于故障数据量,有学者将其视为不平衡数据分类的问题[23,24]。另一方面,也有学者将其视为小样本分类问题[12,25,26],即健康数据量与故障数据量设置为相同,以避免数据分布不平衡。因此,将二级检索关键词分为两部分,分别为小样本学习和不平衡数据学习,如图 2 所示。初次检索共收集到 249 篇英文期刊论文。经过进一步的审阅,与本文主题相关的论文有 145 篇,这些论文将成为本篇综述的主要数据来源。此外,在这些论文的引文中,我们发现了 9 篇相关的会议论文,并将其纳入本篇综述的参考文献中。
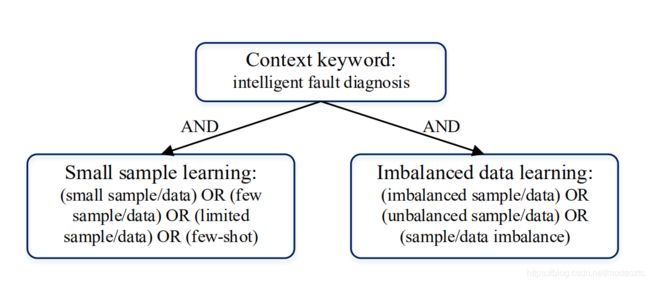
Fig. 2. The two-level keywords tree.
在文献检索过程中,由于关键词的不准确或不完整,可能会出现一些相关文献的缺失。例如,有学者将不平衡的数据视为"倾斜数据"[16]。但在文献检索过程中,我们没有将"倾斜数据"列为检索关键词,这是对文献检索有效性的主要限制和威胁。
Initial Analysis
图 3 为 2010-2020 年 S&I-IFD 相关论文数量。可以看出,2010-2015 年关于 S&I-IFD 的英文期刊论文较少,而 2016 年以来发表的论文数量迅速增加,这主要是由于 GAN 等新型机器学习模型的出现和应用[12]。从图 3 的趋势可以看出,S&I-IFD 是一个很有价值的研究问题,未来几年可能会继续成为研究热点。
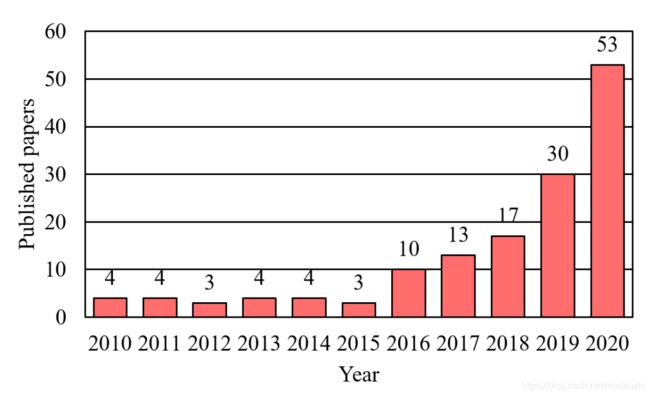
Fig. 3. The publishing trends of S&I-IFD.
Data Augmentation-based Strategy for S&I-IFD
3.1 Motivation
3.2 Data Generation using Generative Models
3.2.1 GAN-based Methods
3.2.2 VAE-based Methods
3.3 Data Over-sampling using Sampling Techniques
3.3.1 SMOTE-based Methods
3.4 Data Reweighting using Transfer Learning
3.4.1 Introduction to Transfer Learning
3.4.2 TrAdaBoost-based Methods
3.5 Epilog
Feature Learning-based Strategy for S&I-IFD
4.1 Motivation
4.2 Feature Extraction using Regularized Neural Networks
4.2.1 DAE and DCNN-based Methods
4.2.1 Other Algorithms-based Methods
4.3 Feature Adaptation using Transfer Learning
4.3.1 TCA and JDA-based Methods
4.3.2 Deep Neural Networks-based Methods
4.4 Epilog
Classifier Design-based Strategy for S&I-IFD
5.1 Motivation
5.2 Fault Classifier Design using Small and Imbalanced Data
5.2.1 SVM-based Methods
5.2.2 Cost-sensitive Classifier-based Methods
5.3 Fault Classifier Design using Transfer Learning
5.3.1 Parameter Transfer-based Methods
5.4 Epilog
Future Challenges and Possible Extensions for S&I-IFD
6.1 How to Improve the Quality of the Augmented Samples in S&I-IFD?
6.2 How to Prevent Transfer Learning-based Approaches from Negative Transfer in S&I-IFD?
6.3 Meta-learning Theory and its Possible Applications in S&I-IFD.
6.4 Zero-shot Learning Theory and its Possible Applications in S&I-IFD.
Conclusions
小样本及不平衡数据下的智能故障诊断是一个极富有研究价值的问题。本文回顾了 S&I-IFD 的研究成果,可分为三类:基于数据增强的策略、基于特征学习的策略和基于分类器设计的策略。具体来说,基于数据增强的策略通过对训练数据样本进行生成、过采样或重新加权的方式,提高对小&不平衡数据的诊断性能。基于特征学习的策略通过正则化神经网络或特征适应,从小&不平衡数据中学习故障特征。基于分类器设计的策略,通过设计适合小&不平衡数据分类的故障分类器,实现高诊断精度。
对于未来的研究,如何提升增强样本的质量是一个需要加强关注的问题。此外,如何防止基于迁移学习的诊断方案出现负迁移,也是工程场景下应用的难题。最后,元学习理论和零样本学习理论在处理 S&I-IFD 问题上有很大的潜力,未来可能会带来研究上的突破。