16种常用的数据分析方法-因子分析

因子分析法是指从研究指标相关矩阵内部的依赖关系出发,把一些信息重叠、具有错综复杂关系的变量归结为少数几个不相关的综合因子的一种多元统计分析方法。
是一种旨在寻找隐藏在多变量数据中、无法直接观察到却影响或支配可测变量的潜在因子、并估计潜在因子对可测变量的影响程度以及潜在因子之间的相关性的一种多元统计分析方法
基本思想
根据相关性大小把变量分组,使得同组内的变量之间相关性较高,但不同组的变量不相关或相关性较低,每组变量代表一个基本结构一即公共因子。
为什么做因子分析
举例说明:在实际门店问题中,往往我们会选择潜力最大的门店作为领航店,以此为样板,实现业绩和利润的突破及未来新店的标杆。选择领航店过程中我们要注重很多因素,比如:
↘所在小区的房价
↘总面积
↘户主年龄分布
↘小区户数
↘门店面积
↘2公里范围内竞争门店数量等
收集到所有的这些数据虽然能够全面、精准的确定领航店的入选标准,但实际建模时这些变量未必能够发挥出预期的作用。主要体现两方面:计算量的问题;变量间的相关性问题。
这时,最简单直接的方案就是削减变量个数,确定主要变量,因子分析以最少的信息丢失为前提,将众多的原有变量综合成少数的综合指标。
因子分析特点
因子个数远小于变量个数;
能够反应原变量的绝大数信息;
因子之间的线性关系不显著;
因子具有命名解释性
因子分析步骤
1.原有变量是否能够进行因子分析;
2.提取因子;
3.因子的命名解释;
4.计算因子得分;五、综合评价
因子与主成分分析的区别
相同:都能够起到处理多个原始变量内在结构关系的作用
不同:主成分分析重在综合原始变适的信息.而因子分析重在解释原始变量间的关系,是比主成分分析更深入的一种多元统计方法
因子分析可以看做是优化后的主成分分析,两种方法有很多共通的地方,但应用方面各有侧重。
因子分析应用场景
因子分析方法主要用于三种场景,分别是:
l信息浓缩:将多个分析项浓缩成几个关键概括性指标。比如将多个问卷题浓缩成几个指标。如果偏重信息浓缩且关注指标与分析项对应关系,使用因子分析更为适合。
l权重计算:利用方差解释率值计算各概括性指标的权重。在信息浓缩的基础上,可进一步计算每个主成分/因子的权重,构建指标权重体系。
l综合竞争力:利用成分得分和方差解释率这两项指标,计算得到综合得分,用于综合竞争力对比(综合得分值越高意味着竞争力越强)。此类应用常见于经济、管理类研究,比如上市公司的竞争实力对比。
因子分析案例
现在有 12 个地区的 5 个经济指标调查数据(总人口、学校校龄、总雇员、专业服务、中等房价),为对这 12 个地区进行综合评价,请确定出这 12 个地区的综合评价指标。(综合竞争力应用场景)
同一指标在不同地区是不同的,用单一某一个指标难以对12个地区进行准确的评价,单一指标只能反映地区的某一方面。所以,有必要确定综合评价指标,便于对比。因子分析方法就可以应用在这个案例中。
5 个指标即为我们分析的对象,我们希望从这5个可观测指标中寻找出潜在的因素,用这些具有综合信息的因素对各地区进行评价。
下图spss因子分析的操作界面主要包括5方面的选项,变量区只能选择数值型变量,分类型变量不能进入该模型。
spss软件为了消除不同变量间量纲和数量级对结果的影响,在该过程中默认自动进行标准化处理,因此不需要对这些变量提前进行标准化处理。
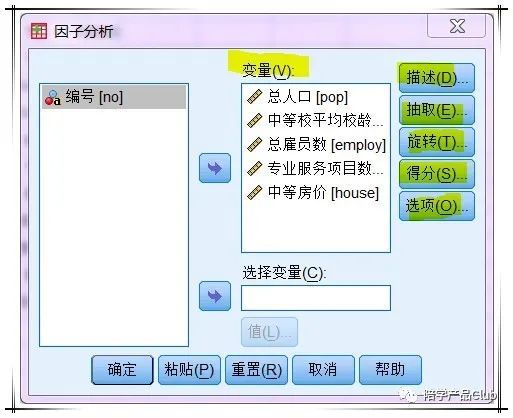
描述统计选项卡
希望看到各变量的描述统计信息,要对比因子提取前后的方差变化,选定“单变量描述性”和“原始分析结果”;
现在是基于相关矩阵提取因子,所以,选定相关矩阵的“系数和显著性水平“,
另外,比较重要的还有 KMO 和球形检验,通过KMO值,我们可以初步判断该数据集是否适合采用因子分析方法,kmo结果有时并不会出现,这主要与变量个数和样本量大小有关。
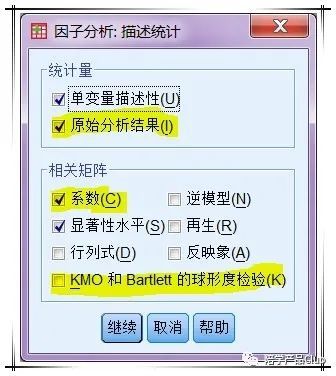
抽取选项卡:在该选项卡中设置如何提取因子
提取因子的方法有很多,最常用的就是主成分法。
因为参与分析的变量测度单位不同,所以选择“相关矩阵”,如果参与分析的变量测度单位相同,则考虑选用协方差矩阵。
经常用到碎石图对于判断因子的个数很有帮助,一般都会选择该项。关于特征值,一般spss默认只提取特征值大于1的因子。收敛次数比较重要,可以从首次结果反馈的信息进行调整。

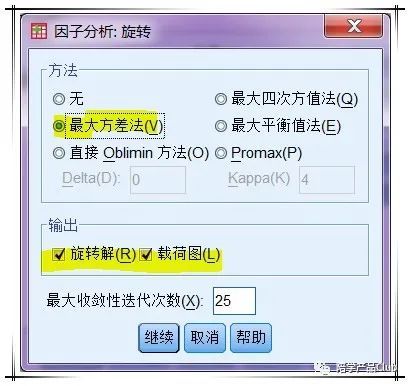
因子旋转选项卡
因子分析要求对因子给予命名和解释,是否对因子旋转取决于因子的解释。
旋转就是坐标变换,使得因子系数向1 和 0 靠近,对公因子的命名和解释更加容易。旋转方法一般采用”最大方差法“即可,输出旋转后的因子矩阵和载荷图,对于结果的解释非常有帮助。
如果不经旋转因子已经很好解释,那么没有必要旋转,否则,应该旋转。
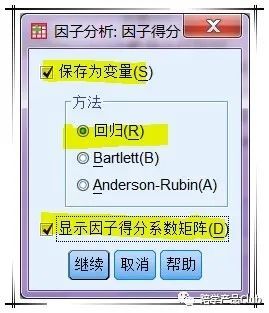
保存因子得分
要计算因子得分就要先写出因子的表达式。因子是不能直接观察到的,是潜在的。但是可以通过可观测到的变量获得。
因子分析模型是原始变量为因子的线性组合,现在我们可以根据回归的方法将模型倒过来,用原始变量也就是参与分析的变量来表示因子。从而得到因子得分。因子得分作为变量保存,对于以后深入分析很有用处。
结果解读:验证数据是否适合做因子分析
参考kmo结果,一般认为大于0.5,即可接受。同时还可以参考相关系数,一般认为分析变量的相关系数多数大于 0.3,则适合做因子分析;
KMO=0.575 检验来看,不是特别适合因子分析,基本可以通过。
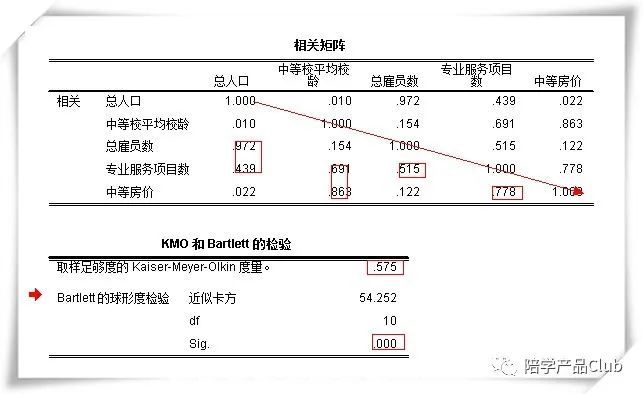
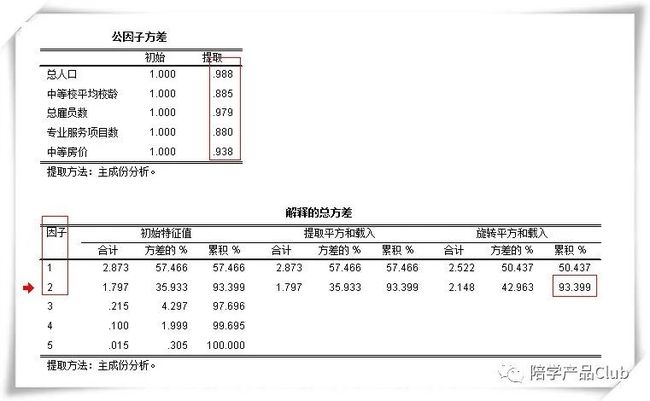
结果解读:因子方差表
提取因子后因子方差的值均很高,表明提取的因子能很好的描述这 5 个指标。
方差分解表表明,默认提取的前两个因子能够解释 5 个指标的 93.4%。碎石图表明,从第三个因子开始,特征值差异很小。综上,提取前两个因子。

结果解读:因子矩阵
旋转因子矩阵可以看出,经旋转后,因子便于命名和解释。
因子 1主要解释的是中等房价、专业服务项目、中等校平均校龄,可以命名为社会福利因子;
因子 2 主要解释的是其余两个指标,总人口和总雇员。可以命名为人口因子。
因子分析要求最后得到的因子之间相互独立,没有相关性,而因子转换矩阵显示,两个因子相关性较低。可见,对因子进行旋转是完全有必要的。


结果解读:因子系数
因子得分就是根据这个系数和标准化后的分析变量得到的。在数据视图中可以看到因子得分变量。
结论
经过因子分析实现了目的,找到了两个综合评价指标,人口因子和福利因子。
从原来的 5 个指标挖掘出 2 个潜在的综合因子。可以对12 个地区给出客观评价。

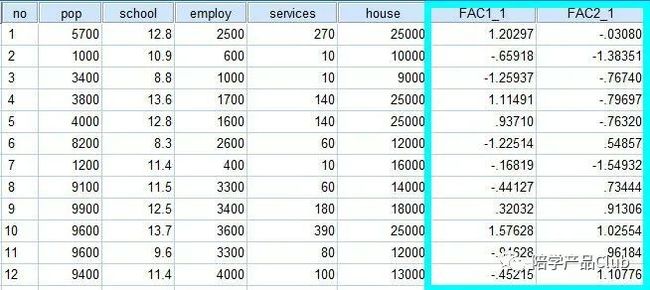
可以根据因子1或因子2得分,对这12个地区进行从大到小排序,得分高者被认为在这个维度上有较好表现。