浅谈编程范式
| 前言
相信绝大部分开发人员、DBA都听过范式这个词,在MySQL中有第一范式、第二范式、第三范式、BCNF范式等,在开发中也有相应的范式,专业词汇叫编程范式(ProgrammingParadigm)。由于笔者能力、精力都有限,本篇主要通过针对同一业务场景,基于编程范式的概念,核心原理以及用例实现来对比不同范式及其实现业务功能的差异。
范式分类
如图1所示,范式可以简单分为三类:

图1: 范式的简单分类
范式和语言的关系
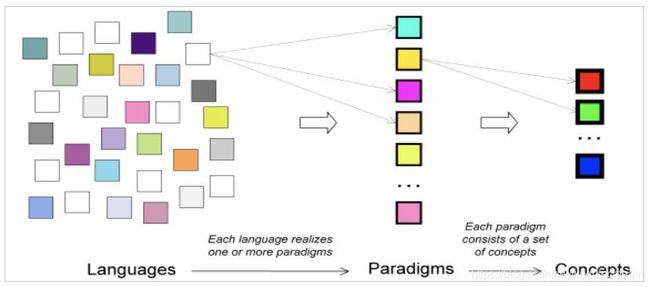
图2: 范式和语言的关系
与成百种编程语言相比,编程范式要少得多,如图2所示,共有27种范式。多数范式之间仅相差一个或几个概念,比如图中的函数编程范式,在加入了状态(state)之后就变成了面向对象编程范式。
| 编程范式

图3: 华山派剑气之争
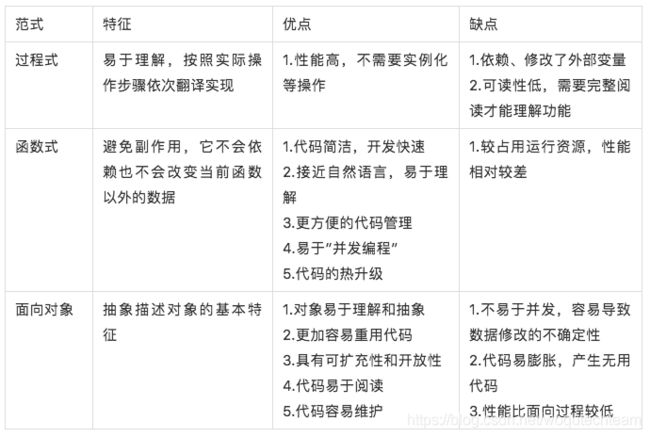
过程式编程的核心在于模块化,在实现过程中使用了状态,依赖了外部变量,导致很容易影响附近的代码,可读性较少,后期的维护成本也较高。
函数式编程的核心在于“避免副作用”,不改变也不依赖当前函数外的数据。结合不可变数据、函数是第一等公民等特性,使函数带有自描述性,可读性较高。
面向对象编程的核心在于抽象,提供清晰的对象边界。结合封装、集成、多态特性,降低了代码的耦合度,提升了系统的可维护性。
不同的范式的出现,目的就是为了应对不同的场景,但最终的目标都是提高生产力。就如华山派的剑宗、气宗之别,剑宗认为“剑为主,气为辅”,而气宗则反之。每个范式都会有自己的”心法”,但最终殊途同归,达到至高境界后则是剑气双修。
| 小结
阅读完之前内容后,相信各位读者对编程范式有了初步的理解,那么接下来就和笔者一起来实现业务的真实需求。
| 需求
-
1.解析并收集shannon, fio 两种 flash卡的温度、寿命等信息。
-
2.对实现代码进行单元测试
在用过程式实现之前,笔者先给大家介绍下什么叫过程式编程。
| 过程式编程(Procedural)
过程式编程和面向对象编程的区别并不在于是否使用函数或者类,也就是说用到类或对象的可能是过程式编程,只用函数而没有类的也可能是面向对象编程。那么他们的区别又在哪儿呢?
面向过程其实是最为实际的一种思考方式,可以说面向过程是一种基础的方法,它考虑的是实际地实现。一般的面向过程是从上往下步步求精,所以面向过程最重要的是模块化的思想方法。当程序规模不是很大时,面向过程的方法还会体现出一种优势。因为程序的流程很清楚,按着模块与函数的方法可以很好的组织。
关键部分实现代码
def get_shannon_info(output):
"""获取shannon类型flash卡信息
"""
def check_health():
time_left = float(sub_info["life_left"])
if time_left < DISK_ALARM_LIFETIME:
message = "time left is less than {}%".format(DISK_ALARM_LIFETIME)
return message
temperature = float(sub_info["temperature"].split()[0])
if temperature > DISK_ALARM_TEMPERATURE:
message = "temperature is over than {} C".format(DISK_ALARM_TEMPERATURE)
return message
return "healthy"
result = {}
all_info = _get_shannon_info(output)
for info in all_info:
sub_info = {}
sub_info["available_capacity"] = info.get("disk_capacity", "")
sub_info["device_name"] = info.get("block_device_node", "")
sub_info["firmware_version"] = info.get("firmware_version", "")
sub_info["interface"] = "PCIe"
sub_info["life_left"] = str(info.get("estimated_life_left", "").replace("%", ""))
sub_info["pcie_id"] = info.get("pci_deviceid", "")
sub_info["pcie_length"] = ""
sub_info["pcie_type"] = ""
sub_info["physical_read"] = info.get("host_read_data", "")
sub_info["physical_write"] = info.get("total_write_data", "")
sub_info["serial_number"] = info.get("serial_number")
sub_info["temperature"] = info.get("controller_temperature")
sub_info["type"] = info["type"]
sub_info["error_msg"] = check_health()
sub_info["status"] = "ok" if sub_info["error_msg"] == "healthy" else "error"
if sub_info["serial_number"]:
result[sub_info["serial_number"]] = sub_info
else:
result[sub_info["device_name"]] = sub_info
return result代码问题
-
1.逻辑冗长,局部修改必须阅读整段代码
-
2.对外部变量有依赖
-
3.内部存在共享变量
-
4.函数内部存在临时变量
测试代码
过程式的测试代码效果远不如函数式有效,过程式的实现逻辑过于冗长,导致测试效果并不够好。
| 函数式编程(Functional)
当谈论函数式编程,会提到非常多的“函数式”特性。提到不可变数据,第一类对象以及尾调用优化,这些是帮助函数式编程的语言特征。提到mapping(映射),reducing(归纳),piplining(管道),recursing(递归),currying(科里化),以及高阶函数的使用,这些是用来写函数式代码的编程技术。提到并行,惰性计算以及确定性,这些是有利于函数式编程的属性。
最主要的原则是避免副作用,它不会依赖也不会改变当前函数以外的数据。
声明式的函数,让开发者只需要表达 “想要做什么”,而不需要表达 “怎么去做”,这样就极大地简化了开发者的工作。至于具体 “怎么去做”,让专门的任务协调框架去实现,这个框架可以灵活地分配工作给不同的核、不同的计算机,而开发者不必关心框架背后发生了什么。
关键部分实现代码
def get_shannon_info(output):
"""查询shannon类型flash卡信息
"""
lines = checks_string_split_by_function(output, is_shannon_flash_device)
info = map(parser_shannon_info, lines)
# map(lambda x: x.setdefault("type", "shannon"), info)
for item in info:
item["type"] = "shannon"
data = map(modify_the_properties, info)
return reduce(combining_data, map(convert_data_format, data))以上代码带有自描述性,通过函数名就可知在做什么,这也是函数式的一个特性: 代码是在描述要干什么,而不是怎么干。
测试代码
@pytest.mark.parametrize("line, result", [
("Found Shannon PCIE", False),
("Found Shannon PCIE Flash car", False),
("Found Shannon PCIE Flash card a", True),
("Found Shannon PCIE Flash card", True),
("Found Shannon PCIE Flash card.", True),
])
def test_is_shannon_flash_device(line, result):
assert functional.is_shannon_flash_device(line) == result
@pytest.mark.parametrize("line, result", [
("a=1", True),
("b=2", True),
("c=2333", True),
("d x=abcde", True),
("Found Shannon PCIE=1", True),
("abcdedfew=", False),
("Found Shannon PCIE", False),
(" =Found Shannon PCIE", False),
("=Found Shannon PCIE", False),
("Found Shannon PCIE=", False),
("Found Shannon PCIE= ", False),
])
def test_is_effective_value(line, result):
assert functional.is_effective_value(line) == result
@pytest.mark.parametrize("line, result", [
("a=1", {"a": "1"}),
("b=2", {"b": "2"}),
("a=a", {"a": "a"}),
("abc=a", {"abc": "a"}),
("abc=abcde", {"abc": "abcde"}),
])
def test_gets_the_index_name_and_value(line, result):
assert functional.gets_the_index_name_and_value(line) == result
@pytest.mark.parametrize("output, filter_func, result", [
("abcd\nbcd\nabcd\nbcd\naa\naa", lambda x: "a" in x, ["abcd\nbcd", "abcd\nbcd", "aa", "aa"]),
(open(os.path.join(project_path, "fixtures", "shannon-status.txt")).read(), functional.is_shannon_flash_device, [
open(os.path.join(project_path, "fixtures", "shannon-sctb.txt")).read(),
open(os.path.join(project_path, "fixtures", "shannon-scta.txt")).read()
])
])
def test_checks_string_split_by_function(output, filter_func, result):
assert functional.checks_string_split_by_function(output, filter_func) == result| 面向对象编程(Object-Oriented)
并不是使用类才是面向对象编程。如果你专注于状态改变和密封抽象,你就是在用面向对象编程。类只是帮助简化面向对象编程的工具,并不是面向对象编程的要求或指示器。封装是一个过程,它分隔构成抽象的结构和行为的元素。封装的作用是分离抽象的概念接口及其实现。类只是帮助简化面向对象编程的工具,并不是面向对象编程的要求或指示器。
随着系统越来越复杂,系统就会变得越来越容易崩溃,分而治之,解决复杂性的技巧。面对对象思想的产生是为了让你能更方便的理解代码。有了那些封装,多态,继承,能让你专注于部分功能,而不需要了解全局。
关键部分实现代码
class IFlash(six.with_metaclass(abc.ABCMeta)):
def __init__(self):
pass
@abc.abstractmethod
def collect(self):
"""收集flash卡物理信息
"""
pass
class FlashShannon(IFlash):
"""宝存的Flash卡
"""
def __init__(self, txt_path, command, printer):
super(FlashShannon, self).__init__()
self.txt_path = txt_path
self.command = command
self.printer = printer
def collect(self):
result = {}
for info in self._get_shannon_info():
life_left = str(info.get("estimated_life_left", "")).replace("%", "")
temperature = info.get("controller_temperature", "")
error_msg = self._get_health_message(life_left, temperature)
sub_info = {
"available_capacity": info.get("disk_capacity", ""),
"device_name": info.get("block_device_node", ""),
"firmware_version": info.get("firmware_version", ""),
"interface": "PCIe",
"life_left": life_left,
"pcie_id": info.get("pci_deviceid", ""),
"pcie_length": "",
"pcie_type": "",
"physical_read": info.get("host_read_data", ""),
"physical_write": info.get("total_write_data", ""),
"serial_number": info.get("serial_number", ""),
"temperature": temperature,
"type": info["type"],
"error_msg": error_msg,
"status": "ok" if error_msg == "healthy" else "error"
}
if sub_info["serial_number"]:
result[sub_info["serial_number"]] = sub_info
else:
result[sub_info["device_name"]] = sub_info
return result
class FlashFio(IFlash):
"""fio的Flash卡
"""
def __init__(self, txt_path):
super(FlashFio, self).__init__()
self.txt_path = txt_path
def collect(self):
disk_info = {}
adapter_info = self._get_adapter_info()
for info in adapter_info:
serial_number = info["fio_serial_number"]
for io in info["iomemory"]:
data = self._combining_io_memory(io)
data["serial_number"] = serial_number
disk_info[serial_number] = data
return disk_info| 编程范式带来的好处
范式就像武功心法,可以更快的练成绝世神功,但还是离不开基础功。代码也一样,通过遵循相关范式和良好的设计后,会带来可读性、扩展性和可维护性更好的代码,进而提升软件的质量。
| 总结
命令式编程、面向对象编程、函数式编程,虽然受人追捧的时间点各不相同,但是本质上并没有优劣之分。 面向对象和函数式、过程式编程也不是完成独立和有严格的界限,在抽象出各个独立的对象后,每个对象的具体行为实现还是有函数式和过程式完成。
现代的程序员应该很少有门派之见了,应该集百家之所长,学习其它范式(语言)的优秀设计理念,集成到自己的代码(产品、语言)中,提升工作效率。
| 致谢
-
简述编程范式:https://ginqi7.github.io/posts/brief-description-of-programming-paradigm.html
-
编程范型:https://zh.wikipedia.org/wiki/%E7%BC%96%E7%A8%8B%E8%8C%83%E5%9E%8B
-
学习编程之概述—从编程范式开始:http://dataunion.org/23223.html
-
面向对象编程 VS 函数式编程:http://blog.swanspace.org/oo_vs_fp/
| 作者简介
黄剑冬·沃趣科技高级开发工程师
人生苦短,我用Python。Python开发爱好者,毕业后一直从事Python相关开发工作,对Python生态有一定理解。主要负责QData相关产品的研发工作。