爬虫笔记41之反爬系列四:字体反爬、JS反爬
一、字体反爬
1、什么是字体反爬?
开发者创作了一种字体(字体代号);网页中显示的就是这种字体代号。
字体反爬也叫CSS反爬,就是因为这个字体是隐藏在我们css文件当中的一个.ttf文件。
2、如何解决字体反爬?(思路:先获取这些文本内容,然后在解决字体的问题)
(1)先找到.ttf文件,需并把它转换成xml文件;
(2)分析xml文件 + FontCreator(360应用市场搜索下载即可);
(3) 找出字体对应的映射关系,和真实的字体做替换。
3、案例
需求:爬取文字字体内容
思路:我们先获取这些文本内容,然后在解决字体的问题。
目标url https://club.autohome.com.cn/bbs/thread/665330b6c7146767/80787515-1.html
第一步 页面分析
(1)爬取要素是否在网页源码中:
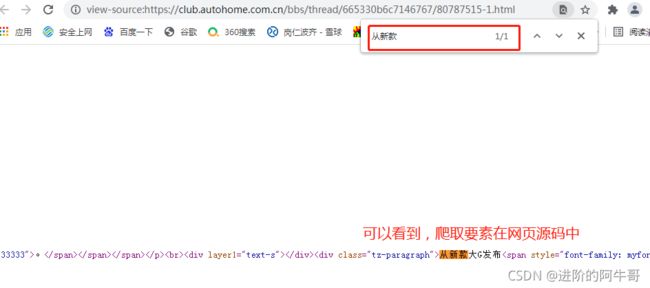
(2)文本内容://div[@class=“tz-paragraph”]
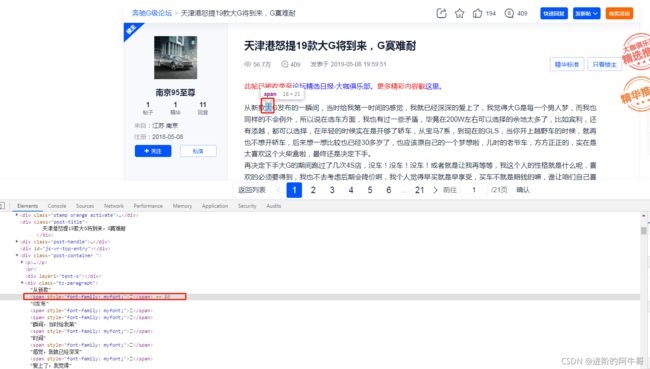
第二步 实现步骤
(1)获取文本内容:

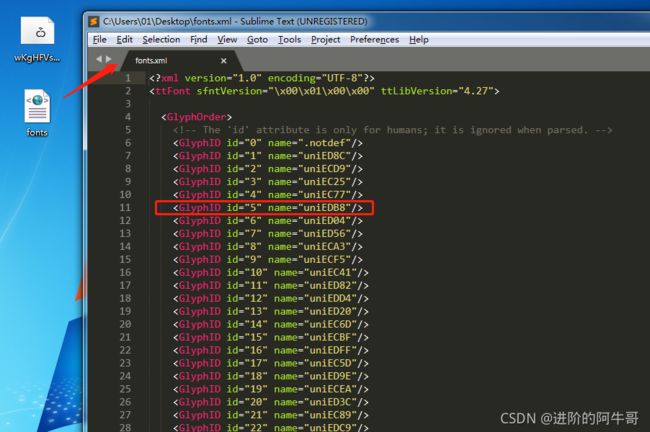
我们猜测:\uedb8 → 大 ;\ueca3 → 了
(2)解决字体问题:
右键查看网页源码,ctrl+f,搜索ttf,得到一个url连接(//k3.autoimg.cn/g1/M02/D0/99/wKgHFVsUz1eAH_VRAABj9PS-ubk57…ttf)
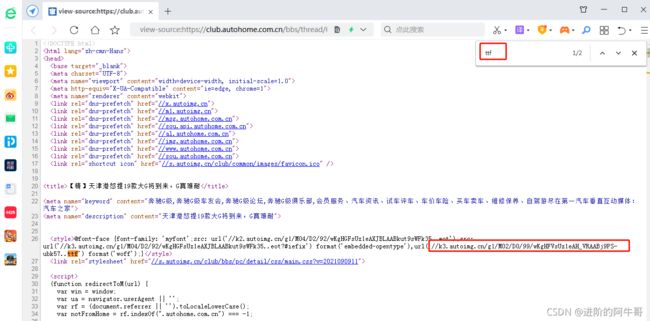
我们打开这个连接,下载得到ttf文件:

我们可以在FontCreator中打开这个ttf文件,如下图:(后面构建字体列表的顺序就是由此而来)

接着我们通过fontTools模块将ttf文件保存为xml文件,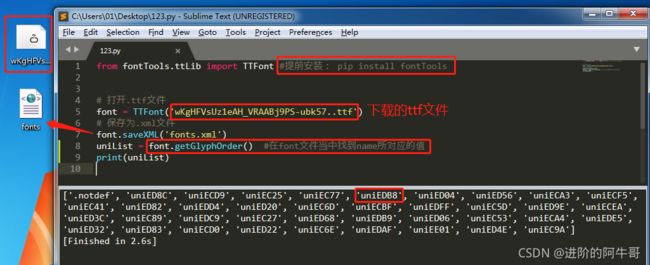
并在sublime中打开查看该文件:
我们接下来:
- 构建编码列表
- 构建字体列表
- 编码与字体一一对应做替换
补充:
python内置函数:eval()
eval() 函数用来执行一个字符串表达式,并返回表达式的计算结果。
语法:eval(expression[, globals[, locals]])
参数
expression – 表达式。
globals – 变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。
locals – 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
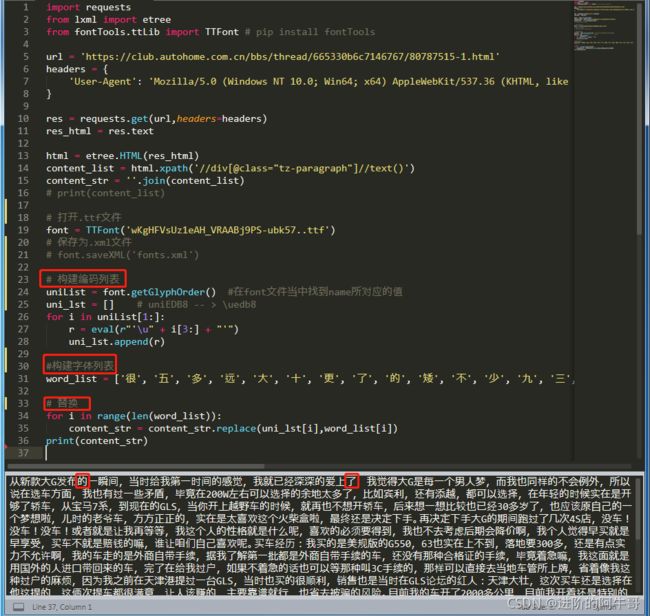
完整代码:
import requests
from lxml import etree
from fontTools.ttLib import TTFont # pip install fontTools
url = 'https://club.autohome.com.cn/bbs/thread/665330b6c7146767/80787515-1.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36'
}
res = requests.get(url,headers=headers)
res_html = res.text
html = etree.HTML(res_html)
content_list = html.xpath('//div[@class="tz-paragraph"]//text()')
content_str = ''.join(content_list)
# print(content_list)
# 打开.ttf文件
font = TTFont('wKgHFVsUz1eAH_VRAABj9PS-ubk57..ttf')
# 保存为.xml文件
# font.saveXML('fonts.xml')
# 构建编码列表
uniList = font.getGlyphOrder() #在font文件当中找到name所对应的值
uni_lst = [] # uniEDB8 -- > \uedb8
for i in uniList[1:]:
r = eval(r"'\u" + i[3:] + "'")
uni_lst.append(r)
#构建字体列表
word_list = ['很', '五', '多', '远', '大', '十', '更', '了', '的', '矮', '不', '少', '九', '三', '八', '一', '右', '坏', '近', '着', '呢', '左', '是', '长', '六', '上', '短', '七', '高', '二', '得', '好', '下', '和', '四', '地', '小', '低']
# 替换
for i in range(len(word_list)):
content_str = content_str.replace(uni_lst[i],word_list[i])
print(content_str)
二、JS反爬
js反爬,它的分析流程和处理流程都是非常复杂和漫长
如何学习js反爬?
(1) 精通JS语言(你能够熟知js这门语言的基本语法)
(2)精通JS中常见的加密算法(并不一定都是算法)
(3)套路经验(调试JS代码)
1、 环境搭建
(1)node.js开发环境(node -v)
(2) 准备js调试工具 (发条js调试工具)
(3)安装一个PyeXECjs模块: pip install PyeXECjs
第二个 说明JS中常见的算法(自己拓展)
1 md5加密算法 线性散列算法 可以产出一个128位的散列值 用于确保信息传输完整的一致性
经过md5加密后产生的是一个固定长度的数据(32位、16位)
2 DES/AES加密
统称为 对称加密 加密运算和解密运算使用的是同样的密钥
密钥:一组随机的字符串
对称:车钥匙
AES/DES的区别
- 加密后的密文长度不同
DES加密后的密文长度是8的整数倍
AES加密后端密文长度是16的整数倍 - 应用场景不同
一般的企业用DES足够
需求更高可以使用AES
encrypt() 加密 decrypt()解密
RSA加密
非对称加密
有2个密钥 - 公开密钥(publickey 公钥)
- 私有密钥(privatekey 私钥)
公钥和私钥是一对 如果用对应的公钥进行加密只有用对应的私钥才可以进行解密
setPublickey() setPrivateKey()
Base64伪加密
第三个 案例
微信公众平台js算法逆向
套路总结
1 如何解决 密码js逆向的问题
2 我们要结合断点 来进行一些相关的测试以及调试
3 通过点击 search选项 搜索关键字pwd 我们发现了一个loginpagexxx.js数据
4 在这个js代码当中 先格式化代码 然后继续搜索关键字 pwd
5 通过分析 这个u函数就是进行我们密码加密的实现
6 然后我们在js代码当中 复制u函数的实现 但是带考虑到逻辑的实现关系 我们去把它对应的关系一并复制
发现一个错误 'n’未定义 var n = {}
7 改写了函数 进行调用 运行看效果
8 调用 execjs模块进行python代码的实现
总结:
1 经过分析我们要找的关键字是pwd 不要全局搜索
逐个js文件分析 login字眼
2 分析调试Js代码
可以把怀疑的代码打断点 进行测试
通过断点测试 定位出相应的可能做了Js加密的逻辑
3 点击看一下它的内部实现
经过分析 测试我们需要哪些 Js逻辑代码
4 通过Js代码调试工具 不断的尝试 保证js语法没有错误
一般做js的同学 一打开网站 找那个 不知道 知道找那个 不知道怎么分析 知道怎么分析 调试不出来