如此高效!数据科学中这4款 Python 神器真的很棒!
大家好,今天给大家分享在数据科学领域中非常棒的4款 Python 神器,它们可以简化我们的工作,让我们的工作更轻松!
废话不多说,我们开始学习吧!欢迎收藏、点赞,文末提供技术交流群。
1、Mito
Mito 是一种电子表格,它可以帮你以10倍的速度完成Python分析。你可以在 Jupyter notebook 中调用 Mito,每次在前端编辑都将生成 Python 代码。
要安装 Mito,请使用以下三个命令:
python -m pip install mitoinstaller
python -m mitoinstaller install
python -m jupyter lab
然后打开Mitosheet界面:
import mitosheet
mitosheet.sheet()
你可以通过从工具栏中选择数据透视按钮,然后选择行、列、值和聚合类型来配置 Mito 数据透视表。
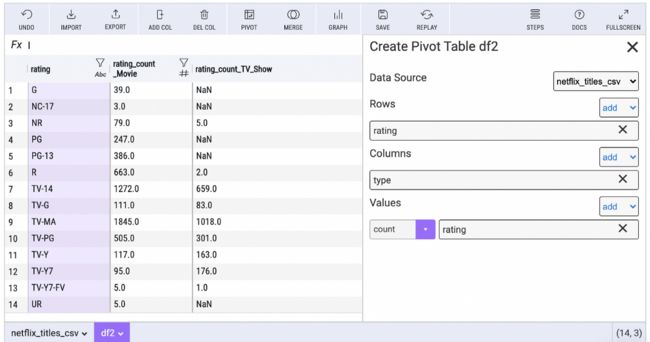
Mito 中的每次编辑都会在下面的代码单元格中生成等效的 Python。 与不断前往 Stack Overflow 寻找正确语法相比,这是一种更快的生成代码的方式。
上面的数据透视表生成此代码并自动对其进行注释!

Mito 不只是为数据透视表生成代码。 在 Mito 中,你可以合并数据集、过滤、排序、使用函数、查看汇总统计数据等等——而且 Mito 将为这些编辑中的每一个生成等效的 Python。
要创建 Plotly 图表,用户所要做的就是单击图表按钮并选择它们的轴。
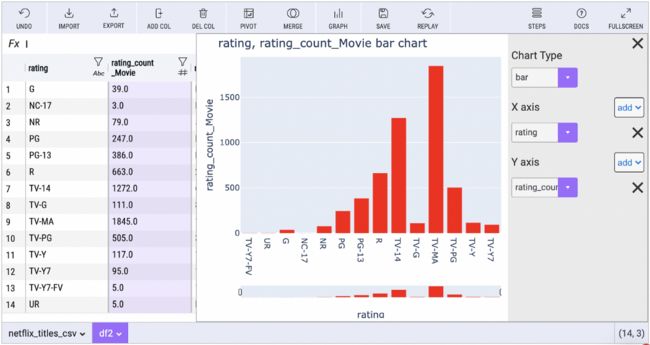
2、Plotly
Plotly 是一款非常棒的可视化库,它是快速轻松地制作交互式图表和图形的最佳软件包。像 matplotlib 和 seaborn 这样的包当然也很直观,但它们缺乏使 Plotly 如此强大的交互性。
要安装 Plotly,请运行以下命令:
$ pip install plotly==5.2.1
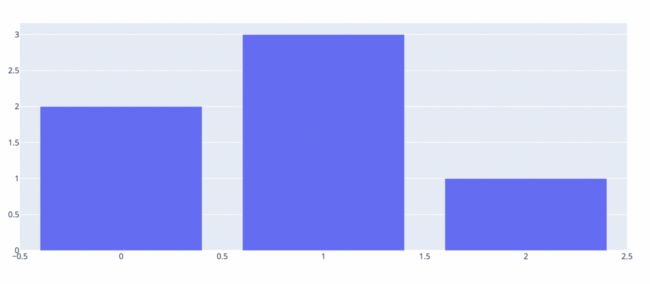
在 Plotly 中,有大量交互式图表可供选择,有更简单的图表,其中更改条形的颜色是交互性。
import plotly.graph_objects as go
fig = go.Figure(data=go.Bar(y=[2, 3, 1]))
fig.show()
他们还提供更高级的动态图表:
2、Tensorflow
Tensorflow 是一个开源的机器学习包,最初由谷歌开发。它使 Python 中的机器学习变得更容易访问,并且随着新更新的出现而继续这样做。
要导入包,请运行以下命令
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
下面是一个可以使用 Tensorflow 运行的简单模型的示例:
class SimpleModule(tf.Module):
def __init__(self, name=None):
super().__init__(name=name)
self.a_variable = tf.Variable(5.0, name="train_me")
self.non_trainable_variable = tf.Variable(5.0, trainable=False, name="do_not_train_me")
def __call__(self, x):
return self.a_variable * x + self.non_trainable_variable
simple_module = SimpleModule(name="simple")
simple_module(tf.constant(5.0))
Tensorflow 允许你轻松构建神经网络。
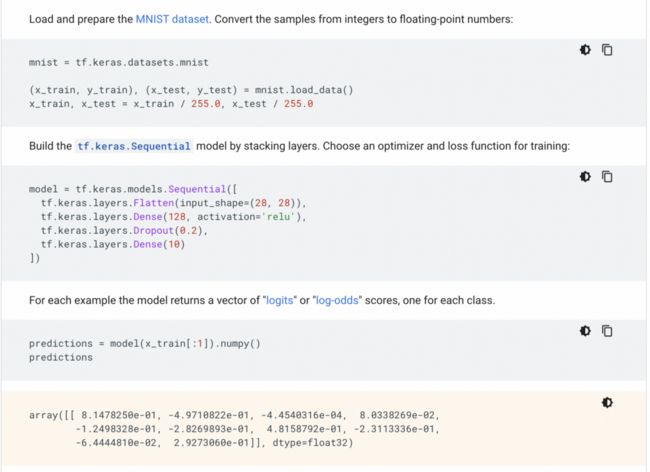
4、Selenium
网络抓取可以是某些数据科学工作流程的一个组成部分。Selenium 使这个过程变得更加容易。
要安装软件包,请运行以下命令:
pip install selenium
使用 selenium,你可以选择要抓取的页面:
driver.get("URL")
你可以使用包提供的不同策略来抓取所需的数据。
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
