【车牌识别】基于模板匹配算法实现车牌识别matlab源码
【车牌识别】基于模板匹配算法实现车牌识别matlab源码
1 模板匹配算法介绍
随着社会经济的发展,车辆的数量在急剧的增加,交通问题日益突出,这使得智能交通(Intelligent Transportation System,简称ITS)系统成为研究的热点领域,受到了广泛的关注.车牌识别系统(License Plate Recognition,简称LPR)是智能交通领域中重要的研究课题之一. 本文根据车牌图像特点,对车牌识别系统关键环节包括数字图像预处理,车牌定位,车牌字符识别等三部分一一进行了分析研究: (1)本文采用直方图变换,边缘检测,二值化等方法对车牌图像进行了预处理. (2)对车牌定位采用了一种基于灰度图像求取卷积能量极值区域的车牌定位方法.该方法充分利用车牌纹理复杂,对比度鲜明,外型规则等特征构造车辆图像的对比度能量图,然后通过选取包括极值行的连通域定位车牌. (3)采用模板匹配法对车牌字符进行识别.因为有些字符形状在垂直方向上在主峰峰值上接近,但在水平方向上存在着比较大的差异,所以在对垂直方向做匹配效果不明显的时候,对水平方向再进行匹配.
1.1 相似性测度求匹配
模板匹配的实际操作思路很简单:拿已知的模板,和原图像中同样大小的一块区域去对。最开始时,模板的左上角点和图像的左上角点是重合的,拿模板和原图像中同样大小的一块区域去对比,然后平移到下一个像素,仍然进行同样的操作, ……所有的位置都对完后,差别最小的那块就是我们要找的物体。
以上所描述的是相似性测度法求匹配的求解思路,其在计算机中操作的如图2所示。设模板T叠放在搜索图上平移,被模板覆盖搜索图下的那个图像叫做子图Si , j,i , j 为这块子图的左上角像素点在S图的坐标,称为参考点,从图2可知,i , j 的取值范围是:1


在(2) 式中第3项表示模板总能量,是一个与(i , j) 无关的常数;第1项是模板覆盖下子图的能量,它随着(i , j) 的位置缓慢地改变;第2项表示的子图与模板的互相关系,随着(i , j) 的改变而改变,当T和Si , j匹配时这项取值最大。因此可用下列相关函数(3) 作相似性测度。
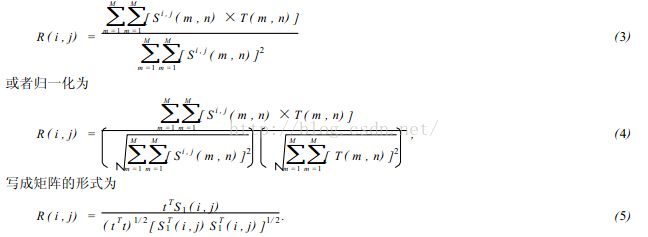
当矢量t 和S1之间的夹角为0时,即当S1(i , j) =kt 时(k为常量) ,有R(i , j) =1,否则R(i , j) <1. 显然R(i , j) 越大,模板T和Si , j就越相似,点(i , j) 就是我们要寻找的匹配点。
1.2 序贯相似性检测的算法
用相关法求匹配的计算量很大,因为模板要在(N- M+1)2个参考位置上作相关计算,除了在匹配点外,其它点作的都是无用功。因此,人们提出一种叫序贯相似性检测的算法,简称SSDA(Sequential SimiliarityDetectionAlgorithm) 其要点是:
在数字图像中,SSDA法用公式(6) 计算图像f ( x, y) 在点(i , j) 的非相似度m(i , j) 作为匹配尺度。式中(i , j) 表示的不是模板中心坐标,而是它左上角坐标。模板的大小为n ×m。
![]()
如果在(i , j) 处图像中有和模板一致的图案时,则m(i , j) 值很小,反之则很大。特别是模板和搜索图下的子图部分,完全不一致的场合下,如果在模板内的各像素与图像重合部分对应的像素灰度差的绝对值依次增加,其和会急剧增大。 因此,在作加法时,如果灰度差的绝对值部分和超过某一阈值时,就认为这个位置不存在和模板一致的图案,从而转移到下一个位置上计算m(i , j)。并且在这模板下的各像素点计算中止,因此能大幅度地缩短计算时间,提高匹配速度。
根据上述思路,我们可以进一步改进SSDA算法。就是把在图像上的模板移动分为粗检索和细检索2个阶段进行。首先进行粗检索,它不是让模板每次移动1个像素,而是每隔若干的像素把模板和图像重叠,并且计算匹配的尺度,从而求出待寻找的图案大致存在的范围。然后在这个范围内,让模板每隔1个像素移动1次,根据匹配的尺度确定寻找图案的所在位置。这样,整体上计算模板匹配的次数减少了,计算时间缩短,匹配的速度提高了。但用这种方法具有漏掉图像中最恰当位置的危险性。
1.3相关算法
2个函数的相关性定义,可用公式(7)表示:
![]()
f*表示f 的复共轭。我们知道相关理论类似卷积理论,F( u, v) 和 H( u, v) 分别表示f ( x, y) 和h( x, y)的傅立叶变换. 根据卷积理论有
![]()
可知卷积是空间域过滤和频率域过滤之间的纽带。相关的重要用途在于匹配。在匹配中,f ( x, y) 是一幅包含物体或区域的图像。如果想要确定f 是否包含有感兴趣的物体或区域,让h( x, y) 作为那个物体的区域(通常称该图像为模板)。如果匹配成功,2个函数的相关值会在h找到f 中相应点的位置上达到最大。从上面分析可知,相关算法可以有2种方法:可在空间域进行,也可在频率域进行。
1.4幅度排序相关算法
这种算法有2个步骤组成:
第1步,把实时图中的各个灰度值按幅度的大小排成列的形式,然后在对它进行二进制(或三进制) 编码,根据二进制排序的序列,把实时图变换为二进制阵列的一个有序的集合{ Cn, n =1,2, …, N}。这一过程称之为幅度排序预处理。
第2步,序贯地将这些二进制序列与基准图进行由粗到细的相关,直到确定出匹配点为止。由于篇幅的限制,这里就不列出例子了。
1.5 分层搜索的序惯判决算法
这种分层搜索算法是直接基于人们先粗后细寻找事物的惯例而形成的,例如,在中国地图上找肇庆的位置时,可以先找广东省这个地域,这过程称为粗相关。然后在这个地域中,再仔细确定肇庆的位置,这叫做细相关。很明显,利用这种方法,可以很快找出肇庆的位置。因为在这过程中省略了寻找广东省以外区域所需的时间,这种方法称为分层搜索的序贯判决法,利用这种思想形成的分层算法具有相当高的搜索速度。限于篇幅,这里只给出这种操作的一般思路。
2 部分代码
clc; %清空命令行
% ==============开始计时==============================
tic
%=====================读入图片=========================
[fn,pn,fi] = uigetfile('..\example\1.jpg','选择图片');%显示检索文件的对话框 fn返回的文件名 pn返回的文件的路径名 fi返回选择的文件类型
I = imread([pn fn]); %读入彩色图像
figure('NumberTitle','off','Name','原始图像');
imshow(I);title('原始图像'); %显示原始图像
%==================加入进度条===========================
waitbar_;
%================图像分割区域(车牌定位)==========================
picture =image_segmentation(I);
threshold=50;
%========================倾斜校正=================
[picture_1,angle] = rando_bianhuan(picture); %倾斜校正 picture 返回校正后的图片 angle 返回倾斜角度
%=========================形态学操作====================
picture_6 = xingtaixue(picture_1);%主要对图像
%=============对图像进一步裁剪,保证边框贴近字体===========
bw = caijian(picture_6);
%=================文字分割 ===================================
image=qiege(bw);
%=================显示分割图像结果================================
bb =zifu_shibie(image);
imshow(picture_1),title ( [bb],'Color','r');
%===================读出声音============================
% duchushengyin(bb);
% ================读取计时===================================
t= toc;
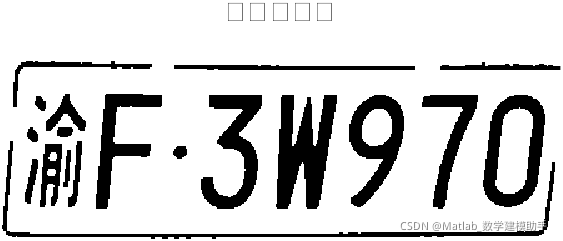
3 仿真结果



4 参考文献
[1]刘屹松. 基于模板匹配车牌识别系统的研究实现[D]. 北方工业大学, 2009.
[2]谢永祥, 董兰芳. 复杂背景下基于HSV空间和模板匹配的车牌识别方法研究[J]. 图学学报, 2014(4):585-589.