阅读《深入理解Kafka核心设计与实践原理》第一、二章
文章目录
- 1. 基本概念
- 2. 生产者
-
- 2.1必要的参数配置
- 2.2 消息的发送
- 2.3 分区器
- 2.4 生产者拦截器
- 3. 原理分析
-
- 3.1 元数据的更新
- 3.2 重要的生产者参数
1. 基本概念
kafka系统架构如图:
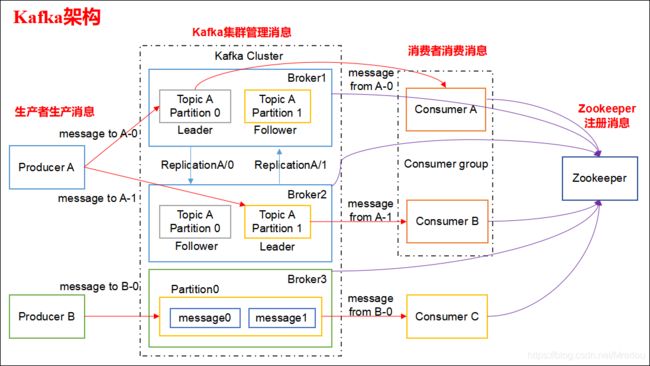
Kafka 架构分为以下几个部分
- Producer :消息生产者,就是向 kafka broker 发消息的客户端。
- Consumer :消息消费者,向 kafka broker 取消息的客户端。
- Topic :可以理解为一个队列,一个 Topic 又分为一个或多个分区。
- Consumer Group:这是 kafka 用来实现一个 topic 消息的广播(发给所有的 consumer)和单播(发给任意一个 consumer)的手段。一个 topic 可以有多个 Consumer Group。
- Broker :一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
- Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker上,每个 partition 是一个有序的队列。partition 中的每条消息都会被分配一个有序的id(offset)。将消息发给 consumer,kafka 只保证按一个 partition 中的消息的顺序,不保证一个 topic 的整体(多个 partition 间)的顺序。
- Offset:是消息在分区中的唯一标识,kafka通过他保证消息在分区的顺序性,kafka只保证消息在分区有序而不是主题有序。kafka 的存储文件都是按照 offset.kafka 来命名,用 offset 做名字的好处是方便查找。例如你想找位于 2049 的位置,只要找到 2048.kafka 的文件即可。当然 the first offset 就是 00000000000.kafka。
- leader: partition的 leader ,leader 有 replication 数,leader副本负责处理读写请求,follower副本负责与leader副本的消息同步,Isr 机制,leader在broker 上,加入broker 挂掉,会在isr 里 找一个作为leader。
- AR:(Assign Replicas)分区中的所有的副本
- ISR: (In Sync Replicas) 所有与leader副本保持一定程度同步的副本。
- OSR:(Out-of-Sync Replicas) 超出一定同步范围的副本。
- HW:High Watermark高水位,消费者只能拉取到这个offset之前的消息。
- LEO: 当前日志文件中下一条待写入消息的offset。
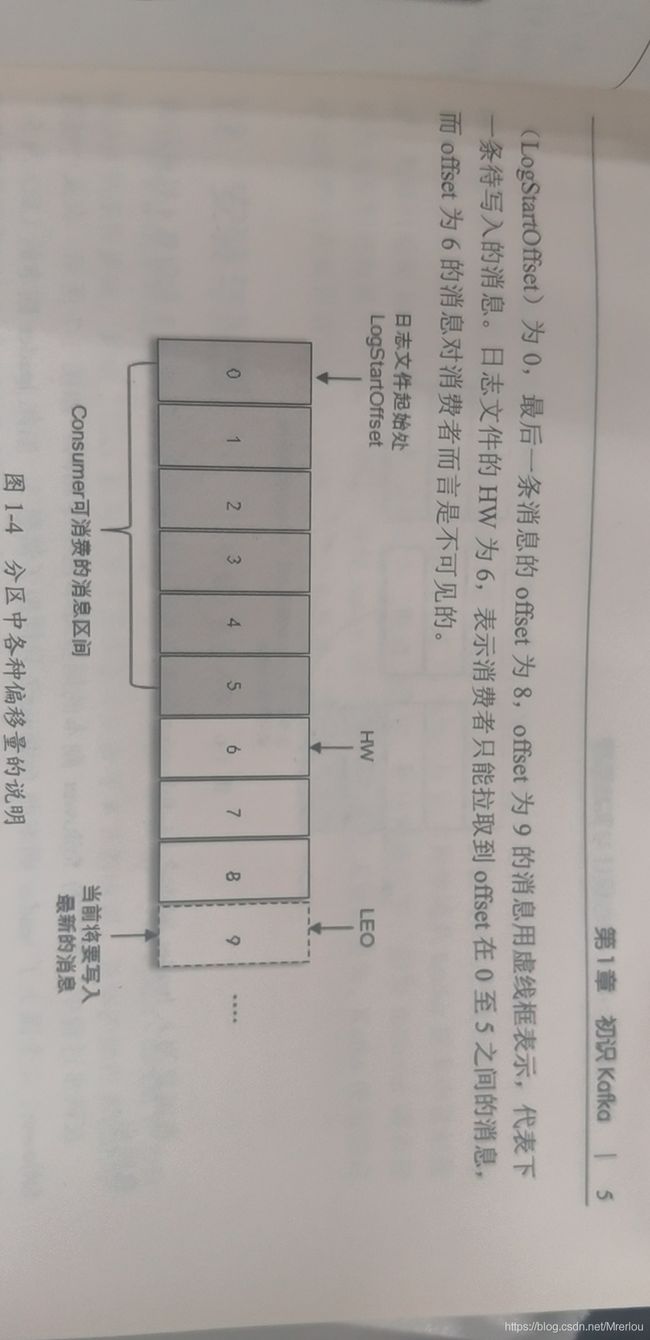
很多资料将offset为5的位置看作HW,而把offset为8的位置看作LEO,是错误的
AR = ISR + OSR
副本处于不同的broker中,当leader副本出现故障时,从follower副本重新选举新的leader副本对外提供服务。kafka通过多副本机制实现故障转移,当kafka集群中某个broker失效仍能保证服务可用。
生产者和消费者只与leader副本进行交互,而follower副本只负责与leader副本进行消息的同步,很多时候follower副本中的消息相对leader副本而言有一定的滞后。
kafka消费端也具备一定的容灾能力。Consumer使用拉(pull)模式从服务端拉取消息,并且保存消费的具体位置,当消费者宕机后恢复上线可以根据之前保存的消费位置重新拉取需要的消息进行消费。
2. 生产者
生产者就是负责向kafka发送消息的应用程序。一个正常的生产逻辑的步骤为:
- 配置生产客户端参数及创建相应的生产者实例
- 构建待发送的消息
- 发送消息
- 关闭生产者实例
构建消息对象ProducerRecord,ProducerRecord类的定义属性如下:
- topic //发往的主题
- partition //发往消息的分区号
- headers //消息头部
- key //键
- value //值
- timestamp //消息的实践戳
消息以主题为单位进行分类,而这个key可以让消息再进行二次分类,同一个key会被划分到同一个分区。
2.1必要的参数配置
- bootstrap.servers 连接的kafka地址
- key.serializer和value.serializer broker端接收的消息必须以字节数组(byte[])的形式存在。
kafkaProducer是线程安全的,可以在多个线程中共享单个KafkaProducer实例。
2.2 消息的发送
创建生产者实例和构建消息之后,就可以发送消息了,发送消息的有3中模式:
- 发后即忘(只管往kafka中发送消息,并不关心消息是否正确到达) 性能最高,可靠性最差.
- 同步(sync) 可靠性高,消息要么成功,要么失败进行异常处理,性能很差,需要阻塞等待一条消息发送完之后才能发送下一条.
- 异步(async)
同步发送消息只需要通过
Future<RecordMetadata> = producer.send(record).get()
get() 会阻塞等待Kafka的响应,知道消息发送成功,或者消息发生异常,如果发生异常需要捕获异常并交由外层逻辑处理.
参考java Future类的get方法.
https://www.cnblogs.com/cz123/p/7693064.html
异步发送消息:
一般是在send()方法里面指定一个callback的回调函数,使用callback,kafka有回应就会回调,要么发送成功,要么抛出异常.
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception != null) {
exception.printStrackTrace();
}else {
System.out.println(metadata.topic() + "-" + metadata.offset());
}
}
});
对于同一个分区而言,消息1于消息2之前发送,那么KafkaProducer可以保证对应的callback1在callback2之前调用,也就是回调函数也可以保证分区有序.
KafkaProducer一般会发生两种类型的异常: 可重试异常和不可重试异常. 常见的异常如分区leader副本不可用,这个异常通常发生在leader下线而新的leader正在选举中,重试之后可以重新恢复, 不可重试异常例如: 发送消息太大,kafka不会对该消息进行任何重试,直接抛出异常.
生产者使用的序列化器和消费者使用的反序列化器是需要一一对应的.
生产者需要用序列化器把对象转化成字节数组才能通过网络发送给kafka,而在对侧消费者需要用反序列化器把从Kafka中收到的字节数据转换成相应的对象.kafka提供了StringSerializer,ByteArray,ByteBuffer,Double,Integer等,除此之外可以选择使用Avro,JSON,ProtoBuf,或者也可以使用自定义类型(如对象)
2.3 分区器
分区器的作用就是为消息分配分区
消息在通过send()方法发往broker的过程中, 有可能经过拦截器,序列化器和分区器的一系列作用之后才能真正发往broker. 拦截器不必要,序列化器是必需的.如果消息指定了partition字段,那么就不需要分区器,如果没有指定partition字段,那么久依赖分区器,根据key这个字段来计算partition的值.
kafka有默认的分区器,如果key不为null,分区器会对key进行哈希,如果key为null, 那么消息将会以轮训的方式发往主题内的各个可用分区.
2.4 生产者拦截器
可以在消息发送前做一些准备工作,按照某个规则过滤不符合要求的消息,修改消息的内容.KafkaProducer不仅可以指定一个拦截器,还可以指定多个拦截器以形成拦截链.
3. 原理分析
如果生产者客户端需要向很多分区发送消息,可以将buffer.memory参数适当调大以增加整体的吞吐量.
消息在网络上都是以字节的形式传输,在发送之前需要创建一块内存区域来保存对应的消息.kafka生产者客户端中,通过nio.ByteBuffer来实现消息内存的创建和释放
3.1 元数据的更新
我们创建一条消息会使用如下方式:
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "Hello, Kafka");
kafkaProducer要将此消息追加到指定主题的某个分区所对应的leader副本之前,首先需要知道主题的分区数量,然后经过计算得出目标分区**,需要知道目标分区的leader副本所在的broker节点的地址,端口信息等,这些信息都属于元数据信息.**
元数据是指kafka集群的元数据,这些元数据记录了集群中有哪些主题,这些主题有哪些分区,每个分区的leader副本分配在那个节点,follower副本分配在那些节点上,那些副本在AR,ISR等集合中.
3.2 重要的生产者参数
acks 用来指定分区中必须要有多少个副本收到这条消息,之后生产者才会认为这条消息成功写入.涉及到可靠性和吞吐量之间的权衡.
- acks = 1。默认值为1。leader写入成功,响应成功。还是会丢数据。
- acks = 0。生产者发送消息之后不需要等待响应。吞吐量大
- acks = -1或 acks = all。生产者在发送消息之后,需要等待ISR中的所有副本都成功写入消息之后,响应成功。最强的可靠性。
- acks = -1 + min.insync.replicas 最少几个接受成功可以响应,更高的消息可靠性。
max.request.size 限制生产者客户端能发送消息的最大值。
retries 和 retry.backoff.ms 重试次数和重试时间,对于一些临时异常,如网络抖动,leader副本选举,以免生产者过早的放弃重试。
compression.type 指定压缩方式,默认为null,可以配置gzip,snappy,lz4
receive.buffer.bytes 设置socket接受消息缓存区的大小,默认32k,设置为-1,使用操作系统默认值,如果producer和kafka处于不同的机房,可以适当调大这个参数值。