语音信号的LPC特征提取
语言是人类创造的,是人类区别于其他地球生命的本质特征之一。语音是语言最本质、最自然、最直接的表现形式或载体,其表现形式为声波—一种由空气分子振动而形成的机械波。人类用语言交流的过程可以看成是一个复杂的通信过程,为了获取便于分析和处理的语音信源,必须将在空气中传播的声波转变为包含语音信息并且记载着声波物理性质的模拟(或数字)电信号,即语音信号,因而语音信号就成为语音的表现形式或载体。
语音识别的研究工作大约开始于上个世纪50年代。1952年贝尔实验室首次研制成功能识别10个英语数字的孤立词语音识别系统——Audry系统。20世纪60年代中期,一系列数字信号处理方法和技术成为语音信号数字处理的理论和技术基础。在方法上,随着电子计算机的发展,以往的以硬件为中心的研究逐渐转化为以软件为主的处理研究。
20世纪70年代,有几项研究成果对语音信号处理技术的进步和发展产生了重大的影响:70年代初,日本人板仓提出动态时间伸缩算法(DTW),使语音识别研究在匹配算法方面开辟了新思路;70年代中期,线性预测技术(LPC)被用于语音信号处理,隐马尔可夫模型(HMM,Hidden Markov Model)法也获得初步成功,该技术后来在语音信号处理的多个方面获得巨大成功;70年代末,Linda,Buzo,Gray和Markel等人首次解决了矢量量化(VQ)码书生成的方法,并首先成功得将矢量量化技术用于语音编码。从此矢量量化技术不仅在语音识别、语音编码和说话人识别等方面发挥了重要作用,而且很快推广到其他许多领域。
80年代,语音识别研究进一步走向深入,首先是声学建模的方式由基于模板的方法全面向统计建模的转变,其次是隐马尔可夫模型和人工神经元网络在语音识别中得到了成功应用,而N元统计语言模型在大词汇听写系统中的应用使得人们突破了大词汇量、连续语音和非特定人这三大障碍,实现了大词汇量连续语音非特定人的语音识别。从此确定了统计方法和模型在语音识别和语言处理中的主流地位。
进入20世纪90年代以来,语音识别在实用化方面取得了许多实质性的研究进展,逐渐由实验室走向实用化。一方面,对声学语言学统计模型的研究逐渐深入,鲁棒的语音识别、基于语音段的建模方法及隐马尔可夫模型与人工神经网络的结合成为研究的热点。另一方面,为了语音识别实用化的需要,讲者自适应、听觉模型、快速搜索识别算法以及进一步的语言模型的研究等课题倍受关注。
随着语音识别技术的进步,其应用越来越广泛,尤其是孤立词语音识别系统应用前景非常广阔,如:语音控制系统,为人们在手动控制以外提供了一种更安全,更方便的控制方法,特别是当系统工作在一些特定的环境或针对一些特殊用户的时候;语音输入系统,用口述代替键盘向计算机输入文字,会给办公自动化和出版界带来革命性的变化;基于对话系统的数据库查询系统,为用户提供了更加友好便捷的数据库检索或查询,可以广泛运用在银行、交易所、民航等机构;除此之外,语音识别还可以用于口语翻译系统、计算机辅助教学、自动身份确认等领域。因此,针对特定人的孤立词语音识别系统具有广泛的实际意义。
端点检测的目的是从包含语音的一段信号中确定出语音的起点以及终点。有效的端点检测不仅能使处理时间减到最小,而且能排除无声段的噪声干扰,从而使识别系统具有良好的识别性能。有学者用一个多话者的数字识别系统做了如下一个实验。首先对所有记录的语音用手工找出准确的端点,得到它们的识别率;然后逐帧(帧长为15ms)加大端点检测的误差,在每次加大误差的同时得到它们的识别率。结果表明在端点检测准确时识别率为93%的系统,当端点检测的误差在+60ms(4帧)时,识别率降低了3%;在+90ms(6帧)时,降低了10%;而当误差在进一步加大时,识别率急剧下降。这说明端点检测的成功与否甚至在某种程度上直接决定了整个语音识别系统的成败[4]。
在设计一个成功的端点检测模块时,会遇到下列一些实际困难:
·信号取样时,由于电平的变化,难于设置对各次试验都适用的阀值。
·取样数据中,有时存在突发性干扰,使短时参数变得很大,持续很短时间后又恢复为寂静特性。应该将其计入寂静段中。
·弱摩擦音时或终点处是鼻音时,语音的特性与噪声极为接近,其中鼻韵往往还拖得很长。
·如果输入信号中有50Hz工频干扰或者A/D变换点的工作点偏移时,用短时过零率区分无声和清音就变的不可靠。
1.1.2 语音的特点
语音信号首先是一个宽带信号,它的频率范围从100Hz一直延伸到8000Hz。但是语音信号是由肺部呼出的气流通过声门形成的激励信号激励声道,再经口唇辐射而产生的。从信号处理的角度来看,可以把语音看成是由白噪声或者周期脉冲激励信号通过一个有色滤波器所产生的。这一过程在时域上看,相当于使样点之间产生了相关性;从频域上看,相当于给频谱加色,使原有的白色谱变成了非平坦的有色谱。此外,在浊音语音段,信号具有周期性,其频谱含有谱线结构。因此,除了谱包络代表的短时相关性外,浊音段还具有长时相关性。
语音的另外一个重要的特点是短时平稳性。语音信号属于非平稳随机过程,但是在短时的条件下又具有平稳的特点。在一段短时间间隔内,语音信号的特征参数能够保持相对的稳定(一般为10~30ms)。语音信号的分析都是建立在短时平稳的基础上的,在分析的时候常用到“短时能量”、“短时过零率”、“短时相关”、“短时频谱”等参数。另外语音信号的相邻短时段的参数变化也不会很大,即它们之间也存在着相关性,这是由于人的发声器官运动速度的有限所决定的。语音信号的频率范围主要集中在300~3400Hz,一般在进行数字化处理的时候采样频率一般采用8KHz,根据不同的需要也可以取其它的一些采样频率进行量化。在采样量化前一般需要对语音信号的低频(低于300Hz)和高频部分(高于3400Hz)作滤除处理。
语音信号简单的可以分为两类。一类是具有短时周期性的浊音,其周期称为基音p(Pitch),其频率称为基音频率(记为f)。对于男性,f大致分布在60~200Hz范围;对于女性和小孩,f大致分布在200~450Hz之间。另一类是具有随机噪声性质的清音,在声门关闭时由口腔压迫其中的空气发出。
1.1.3 歌曲分割合成的研究意义
歌曲是一种特殊的语音,本课题我们将重点研究歌曲的语音分割,下面我们将介绍一下关于歌曲的语音研究。
随着人机语音交互技术的发展,让计算机合成歌曲成为了新的研究热点。计算机合成歌曲一般采用两种方式:第一种方式是朗读+修改的方式,也就是将说话者朗读的语音转换为歌曲,如通过分析语音(日语或英语)和歌曲在声学特征方面的差异,提出了用于修改语音信号的基频、音素时长以及频谱形状等参数的方法,实验证明合成的歌曲有较高的自然度。这种方式要求现场录音,发音是否标准和录音环境的好坏将会影响到合成歌曲的效果,同时录音设备的质量也会影响合成歌曲的自然度。第二种方式是利用语音合成技术,直接将歌词转换为歌曲唱出来。
歌曲在本质上是一种特殊的语音,因此这里重点介绍语音信号处理的研究现状。语音信号处理是建立在语音学和数字信号处理的基础之上的,对语音信号模型进行分析、存储(编码)、传输、识别和合成等方面研究的一门综合性学科。它包括语音编码、语音合成和语音识别三大学科分支,并由此形成了语音存储(编码)技术、语音合成技术和语音识别技术三大实用技术。
这里,我们将研究语音的合成技术来应用到歌曲的合成中。
语音信号的数字化传输一直是通信发展的主要方向之一,语音的数字通信与模拟通信相比,无疑具有更好的效率和性能,这主要体现在:具有更好的话音质量;具有更强的抗干扰性,并易于进行加密;可节省带宽,能够更有效地利用网络资源;更加易于存储和处理。
就语音编码技术而言,它的研究始于1939年Dudley发明的声码器,自70年代起,国外就开始研究计算机网络上的语音通信,当时主要是基于Arpanet网络平台进行的研究和实验。1974年首次分组语音实验是在美国西海岸南加州大学的信息科学研究所和东海岸的林肯实验室之间进行,语音编码为9.6Kbps的连续可变斜率增量调制。1974年12月LPC声码器首次用于分组语音通信实验,数码率为3.SKbps。1975年1月又首次在美国实现使用LPC声码器的分组话音电话会议。20世纪80年代的研究主要集中在局域网上的语音通信,1980年美国政府公布了一种2.4Kbps的LPC编码标准算法LPC-10,这使得在普通电话带宽信道中传输数字电话成为可能。1988年美国又公布了一个4.5Kbps的CELP语音编码标准算法,欧洲推出了一个16Kbps的RELP编码算法,这些算法的音质都能达到很高的质量,而不像单脉冲LPC声码器的输出语音那样不为人们所接受。进入20世纪90年代,随着Interent在全球范围内的兴起和语音编码技术的发展,IP分组语音通信技术获得了突破性的进展和实际应用。最初的应用只是在网络游戏等软件包中传送和存储语音信息,对语音质量要求低,相当于机器人的声音效果。
就语音合成技术而言,目前的研究已经进入文字一语音转换阶段,其功能模块可分为文本分析、韵律建模和语音合成三大模块。其中,语音合成是TTS系统中最基本、最重要的模块。概括起来说,语音合成的主要功能是:根据韵律建模的结果,从原始语音库中取出相应的语音基元,利用特定的语音合成技术对语音基元进行韵律特性的调整和修改,最终合成出符合要求的语音。
语音合成技术经历了一个逐步发展的过程,从参数合成到拼接合成,再到两者的逐步结合,其不断发展的动力是人们认知水平和需求的提高。目前,常用的语音合成技术主要有:共振峰合成、LPC合成拼接合成和LMA声道模型技术。它们各有优缺点,人们在应用过程中往往将多种技术有机地结合在一起,或将一种技术的优点运用到另一种技术上,以克服另一种技术的不足。
2.2京剧的声学分析及音域特征
歌唱音域反映了演员歌唱能力的一个方面,也是艺术嗓音研究的重要指标。西洋唱法的歌唱音域大致是两个八度,例如,女高音:A3-A5, 即220.0~880.0 Hz,女中音:F3-F5,即174.6~698.5 Hz,男高音:A2-A4,即110.0~440.0 Hz,男中音:E2-E4,即82.4~329.4 Hz。花旦和青衣歌唱音域的最高音近1 000 Hz,比女高音880 Hz高近1个音。老旦的演唱主要用真声,其歌唱音域的最高音比女中音高,但比女高音低,介于二者之间。丑、小生、老生和花脸等主要是男声的行当,歌唱音域的最高音至少比男高音440 Hz高一个音,而小生主要是用假声演唱,其歌唱音域的最高音比女高音880 Hz还高半个音。可见,京剧虽然不分声部,但多数属于西洋唱法的高音声部,唱腔的特点之一是调门高。
2.3 基于短时能量和过零率的京剧分割理论介绍
京剧的歌词分割,即将输入的京剧按歌词的发音进行字与字之间的分割,本节研究的算法对于输入信号的检测过程可分为短时能量检测和短时过零率检测两个部分。算法以短时能量检测为主,短时过零率检测为辅。根据语音的统计特性,可以把语音段分为清音、浊音以及静音(包括背景噪声)三种。在本算法中,短时能量检测可以较好地区分出浊音和静音。对于清音,由于其能量较小,在短时能量检测中会因为低于能量门限而被误判为静音;短时过零率则可以从语音中区分出静音和清音。将两种检测结合起来,就可以检测出语音段(清音和浊音)及静音段。由于京剧的特殊性,京剧可以视为特殊的语音信号,所以我们可以考虑使用语音端点检测的方法进行检测,京剧和语音具有一定的相似性。因此在研究京剧分割之前,可以首先对语音信号进行研究。
语音一般分为无声段,清音段和浊音段。一般把浊音认为是一个以基音周期为周期的斜三角脉冲串,把清音模拟成随机白噪声。由于语音信号是一个非平稳态过程,不能用处理平稳信号的信号处理技术对其进行分析处理。但由于语音信号本身的特点,在10~30ms的短时间范围内,其特性可以看作是一个准稳态过程,即具有短时性。因此采用短时能量和过零率来对语音进行端点检测是可行的。
语音信号是一种典型的时变信号,然而如果把观察时间缩短到十毫秒至几十毫秒,则可以得到一系列近似稳定的信号。人的发音器官可以用若干段前后连接的声管进行模拟,这就是所谓的声管模型。
由于发音器官不可能毫无规律地快速变化,因此语音信号是准稳定的。全极点线性预测模型LPC可以对声管模型进行很好的描述,这里信号的激励源是由肺部气流的冲击引起的,声带可以有周期振动也可以不振动,分别对应浊音和清音,而每段声管则对应一个LPC模型的极点。一般情况下,极点的个数在12~16之间,就可以足够清晰地描述语音信号的特征了。LPC是语音分析的重要手段,它能很好地进行谱估计,即可作为语音特征的参数。因此仅用12个LPC系数就能很好地表示复杂语音信号的特征,这就大大降低了信号的冗余度并有效地减少了计算量和存储量,使之成为语音识别和语音压缩的基础。
根据语音信号的产生模型,语音信号S(Z)是一个线性非移变因果稳定系统V(Z)受到信号E(Z)激励后所产生的输出。在时域中,语音信号S(n)是该系统的单位取样响应v(n)和激励信号e(n)的卷积。在语音信号数字处理所涉及的各个领域中,根据S(n)来求得v(n)和e(n)具有非常重要的意义。例如,为了求得语音信号的共振峰就需要知道V(Z)(共振峰频率是V(Z)的各对复共扼极点的频率)。又如,为了判断语音信号是清音还是浊音以及求得浊音情况下的基音频率,就应该知道e(n)或E(Z)。
在实现各种语音编码、识别、合成以及说话人验证和识别等算法时无不需要由v(n)和e(n)的卷积s(n)来求得v(n)和e(n)。由卷积信号求得参与卷积的各个信号是数字信号处理各个领域中普遍遇到的一项共同的任务,解决此任务的算法称为解卷算法。解卷算法的研究是一项十分重要的研究课题,其目的在于用尽可能少的计算代价来获取尽可能准确的V(Z)和E(Z)的估计。
解卷算法的深入研究还引入了很多重要的概念和参数,它们对于编码、识别、合成等许多研究工作和应用技术都是至关重要的。解卷算法可以分成两大类。第一类算法中首先为线性系统V(Z)建立一个模型,然后对模型的参数按照某种最佳准则进行估计,所以这种算法称为参数解卷。
线性预测分析建立于在语音产生的数学模型,指的是一个语音取样的现在值可以用若干个语音取样过去值的加权线性组合来逼近,线性组合中的加权系数称为预测器系数。线性预测的基本问题是由语音信号直接求出一组预测系数,这组系数可以使得一短段语音波形中均方预测误差最小。图2-1所示为语音产生的数字模型简化图:
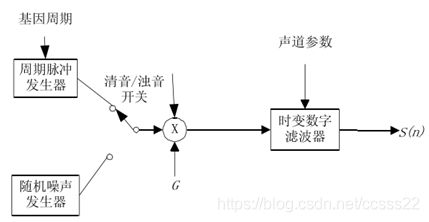
当一个语音信号序列确实是由该数字模型产生,激励源是具有平坦谱包络特性的白噪声(相当于清音)时,应用线性预测误差滤波方法可以求得预测系数和增益,并且H(z)和所分析的语音序列有相同的谱包络特性。
在浊音语音情况下,激励源是间隔为基音周期的冲激序列。基于考虑事实:u(n)是一串冲激组成,意味着大部分时间里它的值是非常小的(零值)。由于采用均方预测误差最小准则来使预测误差e(n)逼近u(n),与u(n)能量很小这一事实并不矛盾,因此为简化运算,我们认为无论是清音还是浊音,上图数字模型都是适合于线性预测分析的。
求上面的线性预测方程组,求解有多种方法,常见的有利用杜宾递推计算的自相关法,利用乔里斯基分解计算协方差法,格型求解法。其中协方差法的优点是精度较高,缺点是不能保证所求得模型的稳定性;自相关法的优点是较简单且结果较稳定,缺点是由于两端的截断效应而精度较低;为了解决精度和稳定性的矛盾,引入正反向预测,基于自相关算法推出了格型结构的逆滤波器,可以直接递推求出线性预测系数。此处只介绍自相关法。
LPC声码器是基于全极点声道模型的,采用LPC分析合成原理,对模型参数和激励参数进行编码传输。LPC声码器遵循二元激励的假设,即浊音语音段采用间隔为基音周期的脉冲序列作为激励,清音语音段采用白噪声序列作为激励。所以声码器只需要对LPC参数,基音周期,增益,清浊音信息进行编码。其结构框图如下所示:
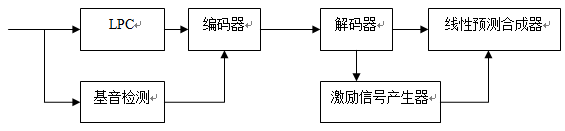
LPC声码器不考虑重建信号波形是否与原来信号的波形相同,而是努力使重建信号具有尽可能高的可懂性和清晰度,所以不进行传输预测残差,只要传输LPC参数和重构激励信号的基音周期和清浊音信息即可。
基于线性预测编码的声码器具有一些非常优良的性能:可以用简洁的模型参数来表征语音信号的频谱幅度、共振峰等信息;其模型是线性的,非常利于分析,提取参数的运算量比较小;具有清晰的物理意义,有利于利用它建立各种编码模型。
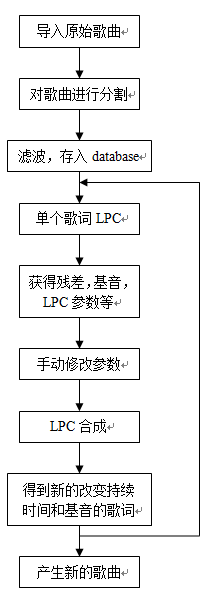
本系统其基本结构框图如下所示:
首先针对一个简单语音信号进行分析,输入语音信号的仿真波形如下所示:

图3.1 输入原始的语音信号
对于输入的语音信号“‘你’‘可’‘以’‘找’‘到’‘更’‘好’‘的’”,这里首先通过短时能量和过零算法对该语音信号进行分割。
由图可以很直观地想到,可以用信号的幅度作为特征,区分静音和语音。只要设定一个门限,当信号的幅度超过该门限的时候,就认为语音开始,当幅度降低到门限以下就认为语音结束。实际上,一般是用短时能量的概念来描述语音信号的幅度的。对于输入的语音信号X(N),其中N为采样点,首先进行帧的操作,将语音信号分成每20~30毫秒一段,相邻两帧起始点之间的间隔为10毫秒,也就是说两帧之间有10~20毫秒的交叠。由于采样频率的差异,帧长和帧移所对应的实际采样点数也是不同的。对于8KHZ采样频率,30毫的帧长对应240点,记为N,而10毫秒的帧移对应80点,记为M。
在进行信号处理之前,首先要对语音信号进行滤波处理。
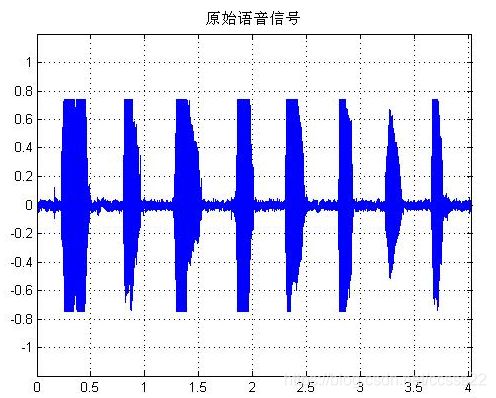
图3.2 滤波之后的语音信号
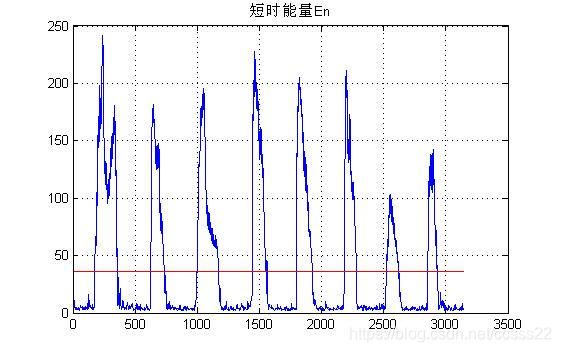
图3.3 计算短时能量及其门限对比图
从上面的仿真结果可以看到,对于简单语音信号,通过短时能量计算,便能得到明显的分割效果,
下面根据短时能量,对信号进行分割,得到如下的分割结果:
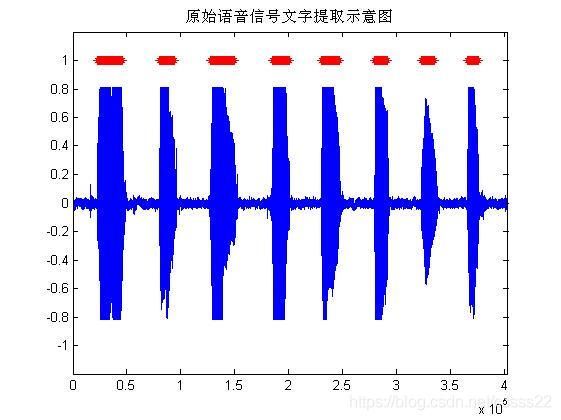
图3.4 原始语音信号的分割结果
从上面的仿真结果可以看到,对于简单的语音的信号,通过短时能量的算法能够得到最后的分割结果。
短时能量分析和过零率分析作为语音信号时域分析中最基本的方法。但是很多情况表明使用单一的一种方法并不能得到理想的检测结果,这是因为短时能量分析是通过能量的高低来区分清音和浊音,不容易确定语音信号片段的起始点;而过零率分析仅仅是表明清音的过零率高于浊音,对噪声的存在比较敏感,如果背景中有反复穿越坐标轴的随机噪声,会产生大量的虚假过零率,影响检测结果。对于背景噪声和清音的区分则显得无能为力。将这两种方法结合起来,通过短时能量分析去除高频环境噪声的干扰,用过零率分析去除低频的干扰,检测效果较好。但综合考虑后,由于这两种方法本身的局限性以及过零率门限值和短时能量门限值的选取,使得检测的范围和精度仅限于单个单词,而对整个句子的检测还达不到令人满意的效果。
首先使用一首歌词之间有明显间隔的歌曲进行测试,下面是其仿真结果图。
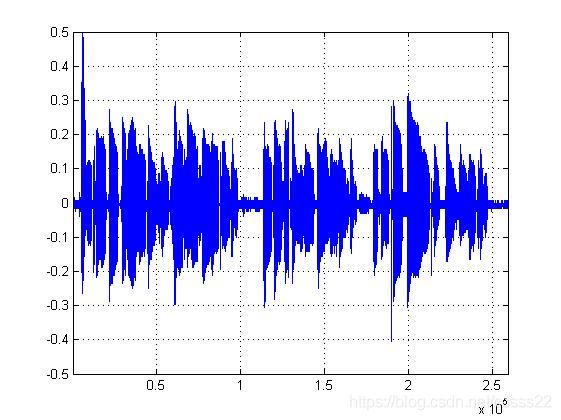
图3.5 输入歌曲一
这里是歌词之间发音比较清晰的歌曲,首先使用这个歌曲进行测试,通过短时能量和过零率进行分析,得到如下的分割结果。
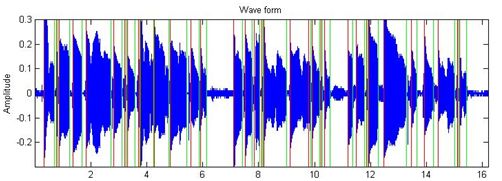
图3.6 经过短时能量分割后的歌曲
从上面仿真结果可以看到,对于间隔较为明显的歌曲端,通过该方法能够较为正确的对歌曲进行分割,但是对于歌曲较为密集的区域,其无法分割出歌词。通过仿真其过零率和短时能量如下图所示:
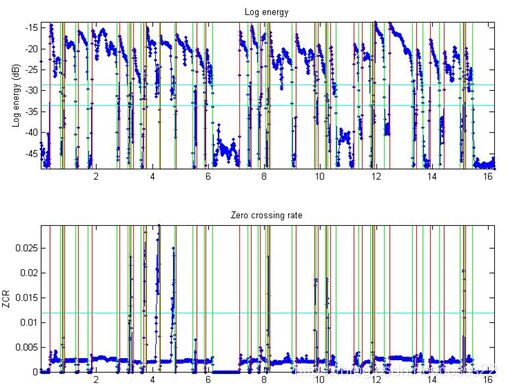
图3.7 短时能量和过零率分割图
从图3.7可见,对于歌词分割较为明显的区域,其短时能量也能分割出来,但是对于歌词较为密集的区域,其短时能量是连接在一起的,这样就无法仅仅通过短时能量来分辨出该区域的歌词分布。
下面通过输入一个另一个歌曲,其时域波形如下所示:
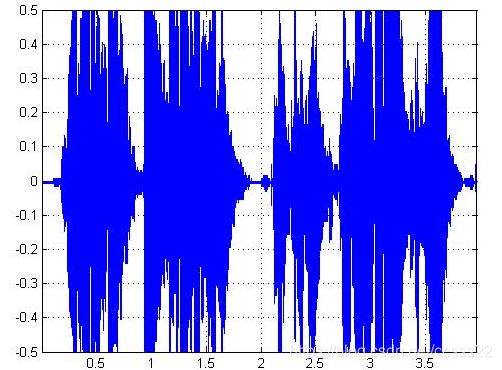
图3.8 测试歌曲二
这个歌曲,其共四个句子,句子与句子之间有明显的间断,但是句子之间,基本无法分辨出单个的歌词,这点可以通过其短时能量来观察,其短时能量仿真波形如下所示:
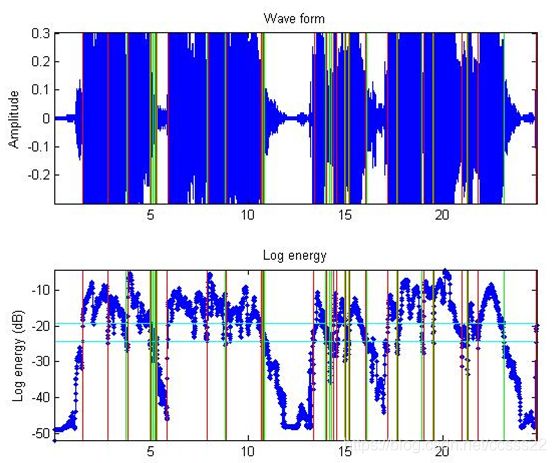

图3.9 歌曲二的分割结果
从图3.9仿真结果可以看到,每个句子之间起能做出明显的风格效果,但是对于句子之间,其虽然也有分割,但是无法做到对每个歌词的分割,这也是短时能量和过零分割的缺陷之一,因此,本课题不考虑使用该方法来对歌曲进行分割。
3.2 基于手动分割的京剧分割
从上面的分割结果可以看到,通过短时能量和过零的方法,并不能对复京剧的歌词进行正确分割,由于本课题的重点是对京剧歌曲的合成,这里暂时采用手动分割的方法对京剧歌曲进行分割。
通过手动分割,将原始的歌曲按如下的格式进行分割并输出。通过分割后,那么原始的歌曲将按下面的格式进行输出:
“输出中文,中文拼音,起始时间,结束时间”
3.3 LPC编解码器的设计与实现
首先将上面讨论得到的歌词作为歌词库存储起来,将其作为歌曲合成的歌词库,然后从歌词库中任意选取一些歌词,改变其基音和持续时间,合成新的歌曲。针对每个歌词进行和运算。
本系统,设计的基于MATLAB的LPC算法流程如下所示:
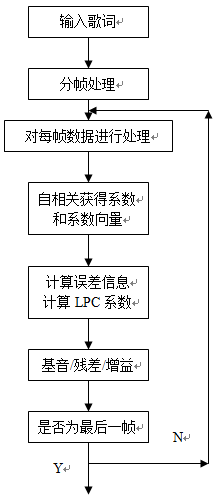
通过LPC算法流程,我们可以得到每个歌词的LPC系数,残差,增益,基音等参数,然后通过修改这些参数的值在进行LPC反变换得到新的歌词。
单独通过一个歌词的仿真,通过该算法,可以得到其LPC系数如下所示:
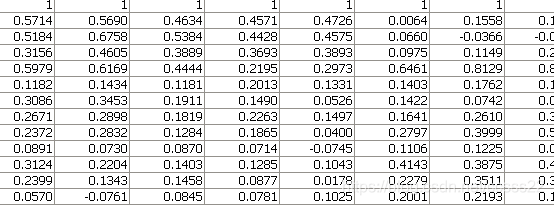
这里采用的是13LPC变换,通过该算法,对于每个歌词,可以得到一组13*x的矩阵数据。通过修改LPC参数的值,就能改变原信号的持续时间和基音大小。注意,这里主要是采用了13阶LPC,所以得到的LPC系数共13行。
下面是一首京剧的分割结果:
猛听的金鼓响画角声震,唤起我破天门壮志凌云。
想当年桃花马上威风凛凛,敌血飞溅石榴裙。
有生之日责当尽,寸土怎能属他人!
番王小丑何足论,我一剑能挡百万兵。
首先通过是用短时能量和过零的方法来进行京剧的分割,通过是用该方法,可以得到其分割结果如下所示:
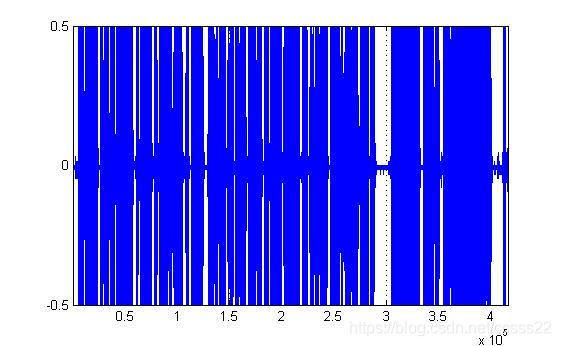
图4.1 京剧歌曲的时域波形
其分割结果如下所示:
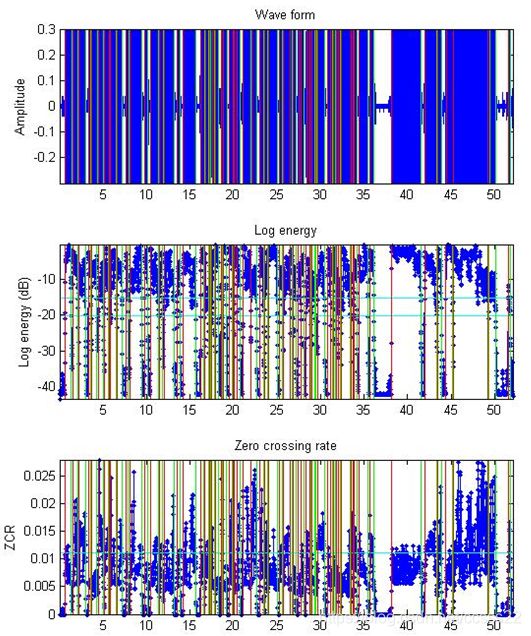
图4.2 利用短时能量和过零算法进行京剧的分割
对照歌词,对每个分割后的结果进行测试,发现通过这种算法,其分割结果不是很精确,因为原始的歌词为69个字,而通过短时能量的方法,其分割结果为64个字,即部分歌词无法正确分割,具体如下所示:
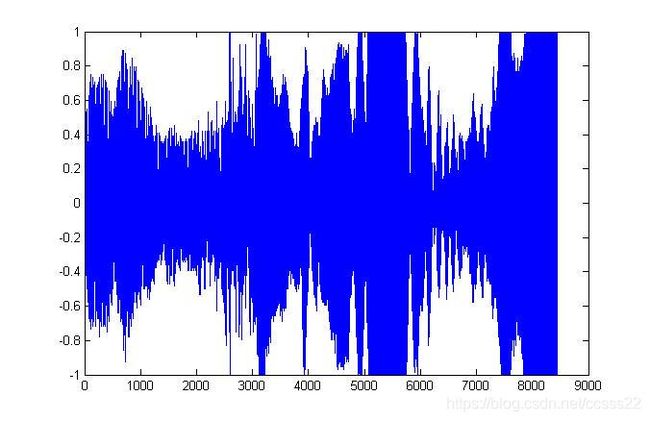
图4.2 歌词“起,我”波形
通过MATLAB的sound指令,可以知道这里是两个字,起,我,但是在分割的结果中,将其作为一个字进行分割了。为了得到根据精确的分割结果,这里采用手动分割的方法。通过分割得到其分割结果如下所示:
表4.1 京剧《穆桂英挂帅》片段分割结果
|
|
京剧 |
| 1 |
猛,meng : [0.50s , 1.44s] 听,ting : [1.44s , 2.19s] 得,de : [2.19s , 3.25s] 金,jin : [3.25s , 3.63s] 鼓,gu : [3.63s , 4.38s] 响,xiang : [4.38s , 5.13s] 画,hua : [5.13s , 5.69s] 角,jiao : [5.69s , 5.88s] 声,sheng : [5.88s , 6.56s] 震,zhen : [6.56s , 7.56s] |
| 2 |
唤,huan : [7.56s , 7.94s] 起,qi : [7.94s , 8.63s] 我,wo : [8.63s , 9.75s] 破,po : [9.75s , 10.38s] 天,tian : [10.38s , 10.75s] 门,men : [10.75s , 11.44s] 壮,zhuang: [11.44s , 11.94s] 志,zhi : [11.94s , 12.06s] 凌,ling : [12.06s , 12.69s] 云,yun : [12.75s , 13.44s] |
| 3 |
想,xiang : [13.44s , 14.19s] 当,dang : [14.19s , 14.88s] 年,nian : [14.88s , 16.19s] 桃,tao : [16.19s , 16.69s] 花,hua : [16.69s , 16.88s] 马,ma : [16.88s , 17.19s] 上,shang : [17.19s , 17.50s] 威,wei : [17.50s , 17.88s] 风,feng : [17.88s , 18.50s] 凛,lin : [18.50s , 18.75s] 凛,lin : [18.75s , 19.38s] |
| 4 |
敌,di : [19.38s , 19.94s] 血,xue : [19.94s , 20.06s] 飞,fei : [20.06s , 20.44s] 溅,jian : [20.44s , 21.00s] 石,shi : [21.00s , 21.44s] 榴,liu : [21.44s , 21.94s] 裙,qun : [21.94s , 22.88s] |
| 5 |
有,you : [22.88s , 23.56s] 生,sheng : [23.56s , 23.94s] 之,zhi : [23.94s , 24.63s] 日,ri : [24.63s , 25.00s] 责,zhe : [25.13s , 25.81s] 当,dang : [25.81s , 26.50s] 尽,jin : [26.50s , 26.88s] 寸,cun : [26.88s , 27.38s] 土,tu : [27.38s , 27.75s] |
| 6 |
怎,zen : [27.75s , 28.38s] 能,neng : [28.38s , 28.75s] 够,gou : [28.75s , 28.94s] 属,shu : [28.94s , 29.38s] 于,yu : [29.38s , 29.56s] 他,ta : [29.56s , 30.31s] 人,ren : [30.31s , 30.81s] |
| 7 |
藩,fan : [30.81s , 31.13s] 王,wang : [31.13s , 31.44s] 小,xiao : [31.44s , 31.69s] 丑,chou : [31.69s , 32.06s] 何,he : [32.06s , 32.38s] 足,zu : [32.38s , 32.63s] 论,lun : [32.63s , 32.88s] |
| 8 |
我,wo : [32.88s , 33.19s] 一,yi : [33.19s , 33.56s] 剑,jian : [33.56s , 33.88s] 能,neng : [33.88s , 35.63s] 挡,dang : [35.63s , 38.13s] 百,bai : [38.13s , 41.88s] 万,wan : [41.88s , 43.13s] 兵,bing : [43.44s , 44.38s] |
我们将这个分割结果作为后期歌曲合成的歌词库。
下面进行新歌曲的合成。假设一组随机选出的歌词,其时域波形如下所示:
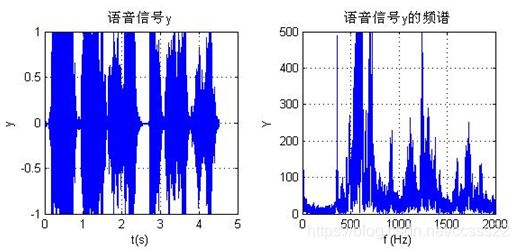
图4.2 原始的歌曲及其频谱图
在不改变任何参数的情况下,通过LPC编解码后可以得到如下的仿真结果:

图4.3 通过LPC编解码后的波形和平铺图
通过上面的仿真可以看到,通过LPC编解码后期时域波形和频谱图基本相似,通过MATLAB中的sound指令,在听觉效果上,基本相同,这说明通过LPC编解码获得较好的合成效果。
改变歌词的持续时间,通过修改LPC编码得到的各个参数,加快歌词播放时间,其仿真效果如下所示:
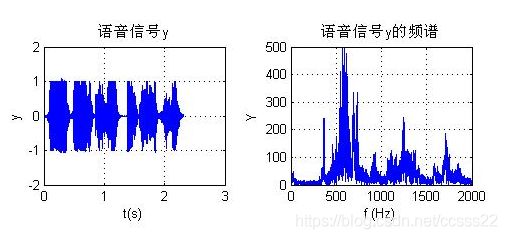
图4.4 加快播放时间后的效果
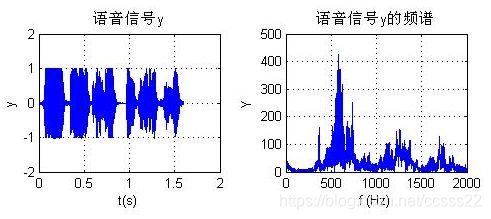
图4.5 加快播放时间后的效果
通过改变歌曲的持续时间,可以看到起时域和频谱波形基本和变换前相同,改变就是时域波形在持续时间上变短了,从而加快的播放速度。
改变歌词的音调,其仿真效果如下所示
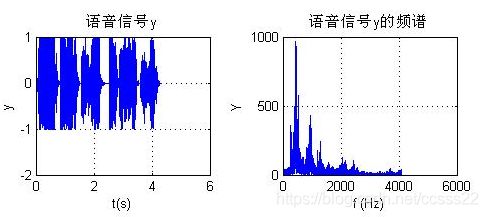
图4.6 改变音调后的仿真图
以上就是通过LPC编解码改变歌曲发声时间,音调的基本仿真结果。