徒手教你制作运维监控大屏
公司业务的不断发展,紧接而来的是业务种类的增加、服务器数量的增长、网络环境的越发复杂以及发布更加频繁,从而不可避免地带来了线上事故的增多,因此需要对服务器到应用的全方位监控,提前预警。
建立在Zabbix上的服务器监控、基础应用监控(mysql、redis、ES等)、预警功能 基本满足底层的监控预警要求,超过设定的阀值就会提前通知相关人员去解决。
有了Zabbix为什么还需要Grafana?
Zabbix图表聚合功能非常薄弱,这不是它的强项,而且数据源只限定自己的收集器,图表展示类就是Grafana的强项。
日志监控用ELG来查看,Kibana在日志量达到一个级别后展现会出现性能问题,集中展示没有Grafana强大,因此用Grafana代替Kibana。
微服务容器相关的监控用Prometheus生态工具,查看容器应用的CPU、内存、JVM等相关指标。
还有服务的链路监控APM,对分布式应用程序集群的业务运行情况进行追踪、告警和分析的系统,查看微服务间的调用链路状态。
现有整套监控系统现状是各自平台监控内容分散,无法统一实时查看,分散精力,因此需要将各平台主要监控的内容抽出来,统一在一个平台展示。
在公司开发人员资源紧张的情况下,想要快速搭建起一套运维大屏可以使用Grafana。
Grafana 是一个开源的监控数据分析和可视化套件。最常用于对基础设施和应用数据分析的时间序列数据进行可视化分析,也可以用于其他需要数据可视化分析的领域。Grafana 可以帮助你查询、可视化、告警、分析你所在意的指标和数据。可以与整个团队共享,有助于培养团队的数据驱动文化。
Grafana 有强大的社区支持,有丰富的模板插件,足够满足需要的功能特性。几乎可以集成ElasticSearch、Mysql、Zabbix、InfluxDB、Prometheus和OpenTSDB作为数据源。
下面就Grafana对接各平台实践操作过程做详细介绍。
展示服务器可用内存指标
服务器可用内存是一个非常重要的指标,因此需要实时关注,防止出现陡坡式的下滑而被忽略。
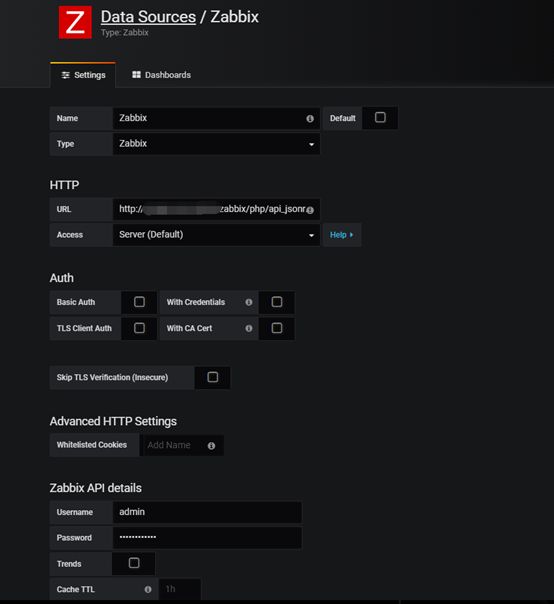
内存信息可从Zabbix中抽取,先添加Zabbix数据源
在Grafana添加数据源,选择Zabbix,然后填写Zabbix的API地址,用户名密码。
url:http://192.168.0.1:8080/zabbix/php/api_jsonrpc.php
保存后,添加一个看板,选择Graph
进入编辑页面

选择Zabbix为数据源

选择Group和Host,对应下拉框是Grafana自动从数据源拉取的内容。


Group对应Zabbix中的群组,Host对应主机,Application对应应用集,item对应是的指标。
这里我们选择想要监控服务器后,选择item对应的可用内存指标:Available memory。

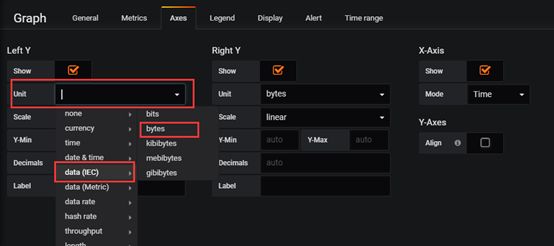
切换到Axes,选择单位
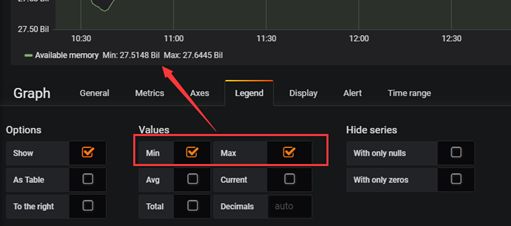
切换到Legend,选择展示最小值和最大值
切换到Display调整线条和背景色的深浅。
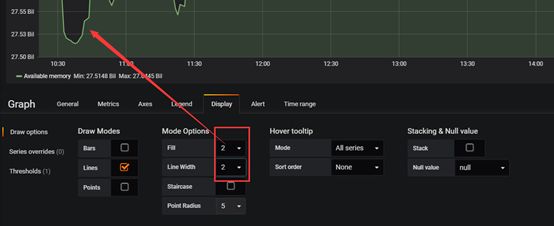
切换到Thresholds设置警戒线,在20G以上是安全的,20G到5G是警告,5G以下就是报警红色(请忽略下面图中的值)。

到此可以看到已经配置完成可看到完整的可用内存走势。

几十台服务器需要一台一台配置?
如果想要看所有服务器的可用内存指标难道需要一台一台添加?
Grafana提供复制功能,制作好一个可按照规则复制,先添加服务器分类

添加

具体内容:

Host选项时因为有Windows服务器,服务器名以B开头,所以先排除以B开头的服务器,这里要说明的是正则是以javascript正则表达式为准的。

保存返回后,就会显示两个下拉框,可以对图形展示进行过滤。

选择上图的Repeat,value选择按照服务器名host指标(上一步配置的)进行横向复制,一行最少24/4=6个。
将监控指标更改为下图所示,item更改为包含memory关键字的,会显示 总内存和可用内存。

保存刷新页面就会将所有服务器的内存展示出来。

其它属性请自行调整。
流量监控
所有服务器的进出流量监控大屏制作步骤参考内存监控内容,不过监控项item改成如下图所示:

日志监控
日志监控包括了业务的访问日志accesslog和自定义info\error log日志。
可以从访问日志中提取某个业务的访问量、响应时长、客户端ip、响应码等等。
这里就其中一个做介绍。
先添加数据源,ElasticSearch,有认证的话需要填写认证信息。

查询访问量最多的前10个服务,用饼形图展示占比。
添加图形组件,选择数据源为上步添加的内容。
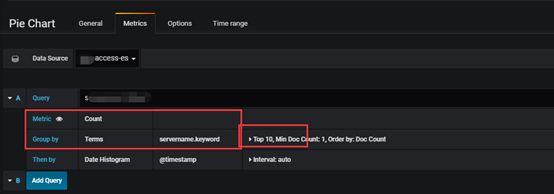
指标选择条数count,按servername(这里记录到ES服务的名称,若有自定义的自行更改)维度统计,选择Top 10。
切换Options,显示total指标到图形右侧。

这样就完成了对接ElasticSearch的图表制作。
与服务访问相关的内容其实Grafana官方有Nginx等相关的看板模板,直接下载模板后选择数据源就可以展现相关的指标,非常漂亮。
如何排除访问量中非业务相关的内容?
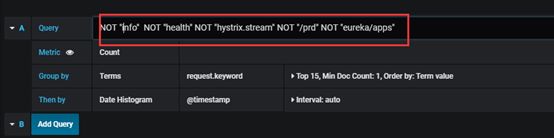
ES的Query语法,非常粗暴直接的方法用NOT排除不关心的内容或干扰内容。
带查询的表格方式展示日志列表
查询日志时可按条件过滤,如只按关心的服务或关键字查询。
添加看板,选择Table。

先添加服务列表和日志等级,关键字输入框


详细内容如下:

第二个参数

Info指标是自己定义的,就不从数据里面读取。
第三个参数选择输入框类型。
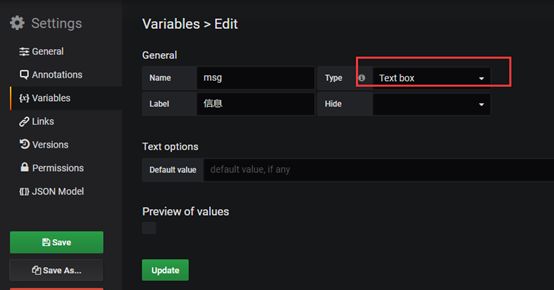
编辑图表,查询内容按以下条件过滤,$代表所选变量。

选择Json Data,然后添加需要展示的列。

由于列名都是code,不太直观,因此可以映射成中文名,切换标签后填写需要映射的列名和中文名,选择类型,可以格式化,可以对值为空时作处理,最后可以对值落入的范围判断进行颜色标示。

最后样式如下:

展示Docker中容器内服务的内存监控
容器内的监控采用的是Prometheus + Cadvisor方案,这里只讲收集后的展示。
添加数据源,指向部署好的Prometheus

Prometheus的查询使用的是PromSQL,PromQL (Prometheus Query Language) 是 Prometheus 自己开发的数据查询 DSL 语言,语言表现力非常丰富,内置函数很多,在日常数据可视化以及rule 告警中都会使用到它。
在页面 http://localhost:9099/graph 中,输入下面的查询语句,查看结果,例如:
http_requests_total{code="200"}
与Mysql的查询对比,模糊查询: code 为 2xx 的数据
// PromQL
http_requests_total{code~="2xx"}
// MySQL
SELECT * from http_requests_total WHERE code LIKE "%2%" AND created_at BETWEEN 1495435700 AND 1495435710;
添加一个图表,选择数据源Prometheus

监控容器内服务内存用方法container_memory_rss,具体语法使用可进入Prometheus页面去查看每个指标,https://songjiayang.gitbooks.io/prometheus/content/promql/summary.html
其它的图表属性设置与前面的设置方法一致,这里不做展开讲,最后保存展示。

实际上不会自己去画每个图表,而是去Grafana模板市场去下载别人上传的模板或官方模板,https://grafana.com/plugins?utm_source=grafana_plugin_list
关于同环比的问题
Gafana没有提供一个同环比展示的图表,这一块也是与每个数据源有关,数据源不支持,Gafana也无法展示,在众多数据源里面PromSQL是基于时间序列的,是可以实现同环比功能的,因此可以先用PromSQL来查询出同环比数据再进行展示。
综合大屏展示
以上内容都是分模块的,现在想把服务器、业务访问流量、容器状态放在一个大屏内显示,每一块都来各自的数据源。
关键在于一块大屏要展示哪些关键信息,摈弃掉无关紧要的内容,下面是其中一个大屏,具体制作方式与上面一样,其中图形大小与布局需要根据投影到大屏上的分辨率有关,需要现场调试。

关于大屏展示的技巧
Grafana提供一个大屏展示轮播功能,几个看板之间自动切换,具体就是Playlists。

给大屏一个名字,和切换间隔,然后将需要轮播的看板加入。
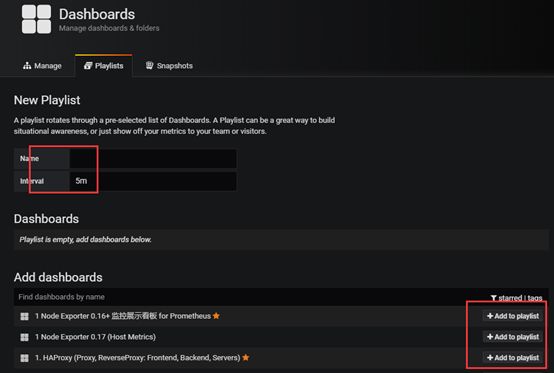
保存后,回到列表,选择播放模式。

与普通模式区别在于,这两种模式下会全屏,隐藏不相关的内容,如地址栏、任务栏和图标,而且图表自适应屏幕大小。两种模式的介绍参考官网:https://grafana.com/docs/reference/playlist/
关于Grafana预警功能
Grafana的预警功能比较薄弱,最大的问题是预警配置不支持模板变量,这就导致如内存低于2G时预警,图表用的是模板内容,含有$host变量就无法预警,只适合于不含变量的图表,没有Zabbix的预警功能方便,因此建议预警用Zabbix来实现。
Grafana还可对接很多数据源,需要自行去探索,有能力的可以进行二次开发,打造自己的监控大屏。