深度学习从入门到精通——pandas的基本使用
kid_diction = {
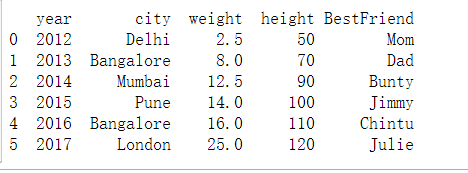
'year': [2012, 2013, 2014,2015,2016,2017],
'city': ['Delhi', 'Bangalore', 'Mumbai', 'Pune', 'Bangalore', 'London'],
'weight': [2.5, 8, 12.5, 14, 16, 25],
'height': [50, 70, 90, 100, 110, 120]}
kid = pd.DataFrame(kid_diction, columns=['year', 'city', 'weight', 'height'])
print(kid)

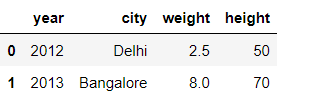
查看前两行
kid.head(2)
查看最后两行
print(kid.tail(2))
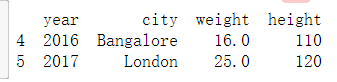
查看基本信息
kid.info()

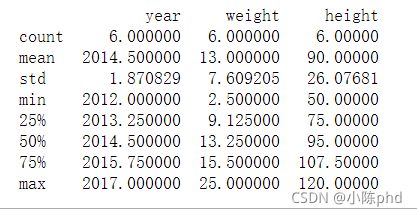
基本数据描述
print(kid.describe())
数据查询
print(kid.iloc[0:4, :2])
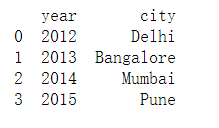
查询城市数据
print(kid['city'])

数据求和
kid['weight'].sum()
![]()
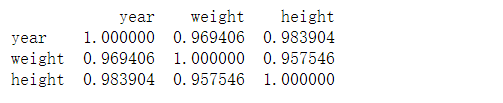
相关系数矩阵
print(kid.corr())
删除一行数据
print(kid.drop('city', axis= 1)) # removing city column , axis =1 means column

增加一列数据
kid['BestFriend'] = ['Mom','Dad','Bunty','Jimmy','Chintu','Julie'] # Adding a new column
print(kid)
pandas 清洗数据
数据生成,例如有nan的数据
import numpy as np
from pandas import Series,DataFrame
import pandas as pd
#Now we'll learn how to deal with missing data, a very common task when analyzing datasets!
data = Series(['one','two', np.nan, 'four'])

# 判断查询空值
data.isnull()
删除空值数据
data.dropna()

部分缺失或者全部缺失处理
# In a DataFrame we need to be a little more careful!
import pandas as pd
dframe = pd.DataFrame([[1,2,3],[np.nan,5,6],[7,np.nan,9],[np.nan,np.nan,np.nan]])

clean_dframe = dframe.dropna()

全部缺失的数据进行删除
print(dframe.dropna(how='all'))

指定数据列删除
#Or we can specify to drop columns with missing data
print(dframe.dropna(axis=1))
'''
Empty DataFrame
Columns: []
Index: [0, 1, 2, 3]'''
根据缺失个数来进行删除
#For example if we only want rows with at least 3 data points
dframe2 = DataFrame([[1,2,3,np.nan],[2,np.nan,5,6],[np.nan,7,np.nan,9],[1,np.nan,np.nan,np.nan]])
print(dframe2.dropna(thresh=2))
删除前
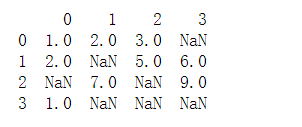
删除后

数据补全操作
常值填充
print(dframe2.fillna(1))
根据不同的列来进行填充补值
print(dframe2.fillna({
0:0,1:1,2:2,3:3}))

在原数据上进行修改操作
inplace 操作
dframe2.fillna(0,inplace=True)
#Now let's see the dframe
print(dframe2)
数据替换操作
所有列
print(dframe2.replace(1,'one'))

指定特定的列
print(dframe.replace([2,3],['two','three']))

过滤,排序,分组操作
generate data
import numpy as np
import pandas as pd
from pandas import DataFrame, Series
#Let's make a dframe
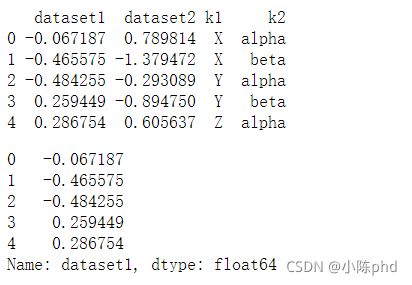
dframe = pd.DataFrame({
'k1':['X','X','Y','Y','Z'],
'k2':['alpha','beta','alpha','beta','alpha'],
'dataset1':np.random.randn(5),
'dataset2':np.random.randn(5)})
#Show
print(dframe)
dframe['dataset1']
根据某个键排序
#Lets grab the dataset1 column and group it by the k1 key
group1 = dframe['dataset1'].groupby(dframe['k1'])
#Show the groupby object
group1 = np.array(group1)
print(group1)

利用多个键排序
#We'll make some arrays for use as keys
cities = np.array(['NY','LA','LA','NY','NY'])
month = np.array(['JAN','FEB','JAN','FEB','JAN'])
#Now using the data from dataset1, group the means by city and month
dframe['dataset1'].groupby([cities,month]).mean()

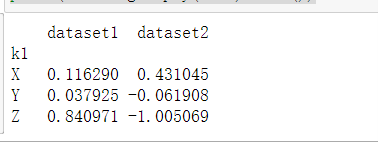
查看排序后均值
print(dframe.groupby('k1').mean())
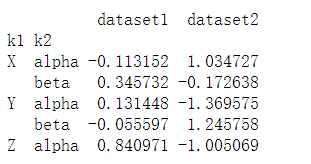
print(dframe.groupby(['k1','k2']).mean())
统计分组元素的个数
dframe.groupby(['k1']).size()

合并数据
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
# Let's make a dframe
dframe1 = DataFrame({
'key':['X','Z','Y','Z','X','X'],'data_set_1': np.arange(6)})
#Show
print(dframe1)

数据段2
dframe2 = DataFrame({
'key':['Q','Y','Z'],'data_set_2':[1,2,3]})
#Show
print(dframe2)
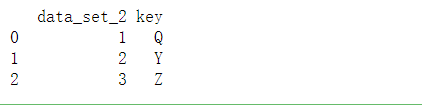
merge
print(pd.merge(dframe1,dframe2))

print(pd.merge(dframe1,dframe2,on='key'))

左对齐
print(pd.merge(dframe1,dframe2,on='key',how='left'))

右对齐
print(pd.merge(dframe1,dframe2,on='key',how='right'))

笛卡尔积,两边都有
print(pd.merge(dframe1,dframe2,on='key',how='outer'))

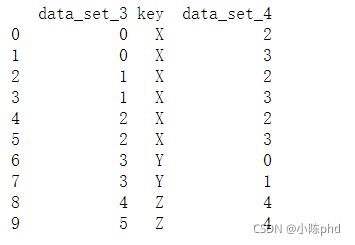
# Nnote that these DataFrames contain more than one instance of the key in BOTH datasets
dframe3 = DataFrame({
'key': ['X', 'X', 'X', 'Y', 'Z', 'Z'],
'data_set_3': range(6)})
dframe4 = DataFrame({
'key': ['Y', 'Y', 'X', 'X', 'Z'],
'data_set_4': range(5)})
#Show the merge
print(pd.merge(dframe3, dframe4))
# Dframe on left
import pandas as pd
df_left = pd.DataFrame({
'key1': ['SF', 'SF', 'LA'],
'key2': ['one', 'two', 'one'],
'left_data': [10,20,30]})
#Dframe on right
df_right = pd.DataFrame({
'key1': ['SF', 'SF', 'LA', 'LA'],
'key2': ['one', 'one', 'one', 'two'],
'right_data': [40,50,60,70]})
#Merge
print(pd.merge(df_left, df_right, on=['key1', 'key2'], how='outer'))
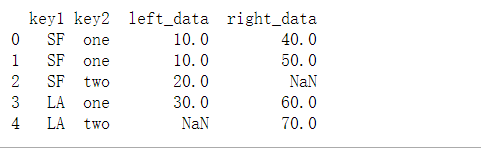
# pandas automatically adds suffixes to them
print(pd.merge(df_left,df_right,on='key1'))

指定后缀
# We can also specify what the suffix becomes
print(pd.merge(df_left,df_right, on='key1',suffixes=('_lefty','_righty')))
