1. 数据类型
byte 1 字节
short 2 字节
int 4 字节 (-128 - 127)
long 8 字节
double 8 字节
float 4 字节
char 2 字节
boolean 1 字节
2. 类型转换
自动转换
当容量小的数据类型变量与容量大的数据类型变量做运算
时,结果自动提升为容量大的变量
byte, char, short < int < long < float < double
当 byte, char, short 做运算时 结果最小要用 int 接收
强制转换
自动转换的逆过程,将大的数据类型变量转换成小的类型
变量,需要强制转换符(),但可能会出现精度降低或溢出
3. &和&&的区别
相同点
二者的值都一样
符号左边的值为 true 时继续执行右边的运算
不同点
&左边的值为 false 时,继续执行左边的运算
&&左边的值为 false 时,不在执行右边的运算
4. | 和 || 的区别
相同点
二者的结果一样
符号左边的值为 false 时继续执行右边的运算
不同点
| 左边的值为 true 时,继续执行右边的运算
|| 左边的值为 true 时,不在执行右边的运算
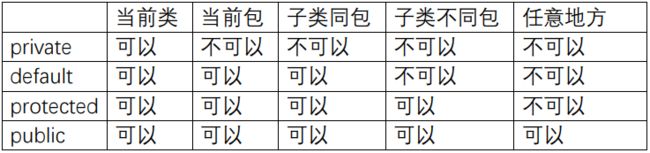
5. 访问权限修饰符
6. 抽象
abstract 修饰的类为抽象类
抽象类不能实例化
想要使用抽象类只能通过继承的方式
抽象类中可以有普通方法也可以有抽象方法
abstract 修饰的方法为抽象方法
抽象方法没有方法体
一个类如果继承抽象类必须要重写其抽象方法,除非子类
也为抽象方法
7. 重写和重载的区别
1. 重写发生在父子类继承关系中,而重载发生在同一个类中
2. 重写父类的非静态非私有的方法,而重载没要求
3. 重写的返回值要一致,而重载和返回值无关
4. 重写的参数列表要一致,而重载的参数列表中的参数数量
和参数类型和参数顺序其中一个不同就可以
5. 重写时子类的访问权限不得小于父类,重载没要求
6. 重写时子类不得抛出比父类大或者比父类多的异常,重载
没要求
8. switch
1. switch 中的表达式只能时如下六种类型:
int, char, byte, short, 枚举(JDK1.5), String(JDK1.7)
2. case 后边只能声明变量不能声明范围
3. case 后边的变量与 switch 的表达式匹配的话就执行下边代
码段
4. break 是中断匹配下一个 case, 可选的
5. default 也是可选的,相当于 else 当 case 匹配都不成功的
时候执行 default 下面代码,位置灵活的
6. switch 与 if(){}else{} 相比效率高
9. 接口和抽象类的区别
1. 实现接口的关键字为 implements,抽象类的关键字是
abstract
2. 一个类可以实现多个接口,但只能继承一个抽象类
3. 接口中只能定义方法,而抽象类可以有方法的实现
4. 接口强调的是特定功能的实现,抽象类强调的是所属关系
5. 接口的成员变量默认为 public static final 要赋初始值,不
能修改, 抽象类成员变量默认为 default
10. ==与 equals()的区别
1. ==是比较运算符, 可以比较基本数据类型和引用数据类型,
比较基本数据类型时是比较两个值是否一致,类型不做比较,比较
引用数据类型时比较的是两个数据的地址是否一致
2. equals 是 Object 类的方法,用来比较两个引用数据类型的值
是否一致
11. throw 和 throws 的区别
1. throw 是抛出异常对象,用于方法体内
2. throws 是声明异常类,用于方法体与参数列表之间,表示
抛出异常类,调用声明了异常的方法需要处理异常
12. final, finally, finalize 的区别
final 修饰的变量是常量,不能被修改,必须要有初始值
final 修饰的方法不能被重写,但可以被重载
final 修饰的类不能被继承
finally 是与 try{}catch(){}连用的语句,finally 一定会执行
finalize 是 Object 中的方法,在 CG 垃圾回收的时候调用
13. 单例
## 饿汉式
public class Single {
private static Single sin = new Single();
public static Single get() {
return sin;
}
}
## 懒汉式
public class Single {
private static Single sin = null;
public static Single get() {
if(sin==null) {
sin = new Single();
}
return sin;
}
}
## 双重判定锁
public class Single {
private static Single sin = null;
public static Single get() {
if(sin==null) {
synchroniza(Single.class) {
if(sin==null) {
sin = new Single();
}
}
}
return sin;
}
}
14. String str = new String(“abc”)创建几 个对象
两个对象,一个对象是 str = “abc”常量池中的值的对象,另
一个是 new String();在堆中开辟的空间
15. String 类能不能被继承
不能,因为 String 类是被 final 修饰的类
16. String, StringBuffer, StringBuilder 区别
String: 是不可变的字符串类型,效率低,不能被继承
StringBuffer: 是可变的字符串类型,效率高于 String,线程安
全的
StringBuilder: 是可变的字符串类型,效率高与 StringBuffer,
线程不安全的
17. ArrayList
1. ArrayList 默认长度是 10,如果添加元素超过 10 那么默认
扩展原来的 1.5 被长度
2. ArrayList 底层储存的是 Object[]数组
3. 调用 add()方法时才会创建一个长度为 10 的 Object[]数组,
然后把数据储存在 Object[]里
18. ArrayList,LinkedList,Vector 区别
ArrayList 底层是长度为 10 的 Object[]数组,线程不安全
LinkedList 底层是使用双向链表储存,线程不安全
Vector 底层也是 Object[]数组,效率低,线程安全
ArrayList: 存取速度快,删除插入速度慢
LinkedList: 存取速度慢,删除插入速度快
19. Set 和 List 区别
Set 无序 无下标,不可重复的
List 有序 有下标,可重复的
20. Collection,Collections,Set,List 区别
Set,List 都是借口,他们都继承 Collection 接口,Set 是无序
无下标的,List 是有序有下标的
Collection 是 Set,List 的顶层接口,Collections 是一个封装
众多操作接口的静态方法的工具类,构造方法是私有的不能实例化
21. Map
HashMap:线程不安全的,效率高,key-value 可以储存 null
值
LinkedHashMap:HashMap 的子类,可以保证插入数据的顺
序和输出的顺序一致,原理是在 HashMap 底层结构基础上,添加了
一对指针,指向前一个和后一个元素,频繁的遍历操作 xiaolü 高于
HashMap;
TreeMap:是按照 key 值升序排序的,可以通过 comparable
和 comparator 来指定排序,底层基于红黑树
HashTable:线程安全的,效率低,不可以储存 null 值
22. HashMap 底层原理
new hashMap(); 实例化后,底层创建一个长度为 16 的 Entry[]
一维数组
执行 put(key, value)方法时:
先调用 key 所在类的 hashCode 方法,来计算出哈希值,通
过哈希值来计算出所在 Entry[]数组中的存放位置,如果此位置上数
据为空,key-value 添加成功
如果此位置上的数据不为空,那么就意味着此位置上有一个
或多个数据(链表形式存放),此时就要比较 key 和此位置上的数据
的哈希值,如果哈希值不相同,则 key-value 添加成功
如果哈希值相同那么就用 equals 方法比较 key 和此位置上的
数据,如果为 false,则 key-value 添加成功
如果为 true,则把 value 值替换掉
*注:此时的 key-value 和此位置上的数据是以链表方式储存
的,在不断添加后,当超出临界值且此位置上数据不为空时,会以
原来的容量扩充 2 倍,在将原有的数据复制过来
JDK1.7 早期版本,在实例化后创建长度为 16 的数组
JDK1.7 后期和 JDK1.8,在执行 put 方法后创建长度 16 的数
组
JDK1.8 底层时 Node[]数组不是 Entry[]数组
JDK1.7 底层结构是 数组+链表
JDK1.8 底层结构是 数组+链表+红黑树
当链表元素数目到 8 个,同时 HashMap 的数组长度要大于64,
链表才会转红黑树,否则都是做扩容。
loadFactor:负载因子 默认值 0.75;
threshold:能容纳键值对的临界值;
threshold 计算公式: 数组长度*负载因子;
size:HashMap 实际存在键值对的数量;
HashMap 默认容量为 16;
modCount:用来记录 HashMap 内部结构发生变化的次数
23. Java 序列化机制是什么
对象的序列化机制是指将内存中的 Java 对象转成平台无关的
二进制流,将此二进制流持久的保存在磁盘上,在网络上可将此二
进制流传输到另一个网络节点上,当其他程序获取此二进制流可恢
复到源流的 Java 对象
24. 序列化和反序列化
序列化:将 Java 内存中的对象保存在硬盘中,或者以网络的
形式传输出去;
反序列化:将硬盘中的 Java 对象还原到内存中;
25. 进程和线程区别
进程:
正在进行或执行的程序,当程序执行时,会在内存中
开辟出一个运行空间,程序会在此运行空间运行,进程就是程序的
运行空间,进程的作用就是给程序开辟出一个运行空间
线程:
运行空间开辟出后,就会在运行空间执行程序,所谓
的执行程序就是在指定的入口按照一定的执行顺序来执行程序的代
码内容,一个线程就是一个执行路径,线程的作用就是执行程序
进程可以有多个线程
26. 线程的实现方式
1. 继承 Thread 类
2. 实现 Runnable 接口
3. 实现 Callable 接口
4. 线程池 Spring 线程池
27. 线程的生命周期
1. 新建
2. 就绪
3. 运行
4. 阻塞
等待阻塞:执行 wait()方法时
同步阻塞:获取同步锁失败时
其他阻塞:执行 sleep 方法或 join 方法时发出了 I/O
请求时发生阻塞
5. 死亡
28. wait();和 sleep();区别
1. wait 方法是 Object 类的方法,sleep 方法是 Thread 类的方法
2. sleep 可以在任意地方调用,wait 要在同步代码块或同步方法
中调用
3. sleep 和 wait 都在同步代码块和同步方法调用时,sleep 不释
放锁,wait 释放锁
29. synchronized 和 ReenTrantLock 区别
1. synchronized 是 Java 关键字,Lock 是接口
2. synchronized 发生异常时会自动释放锁,Lock 不会,会发
生死锁现象,所以要再 finally 里调用 unLock 方法
3. Lock 可以在等待锁的线程响应中断,synchronized 会一直
等待下去,不会响应中断
4. Lock 可以知道有没有获取到线程锁,synchronized 不能
5. Lock 可以提高多线程读操作的效率
30. 反射获取 Class 类方法
1. 通过类名点 class 获取
2. 通过实例调用 getClass 方法获取
3. 通过类名调用 forName();方法获取
4. 通过类加载器获取 this.getClass().getClassLoader().loadClass();
31. 多态
多态是同一个行为具有多个不同表现形式或形态的能力。
多态就是同一个接口,使用不同的实例而执行不同操作
条件:继承,重写,父类引用指向子类对象