上海市高等学校信息技术水平二三级python 模拟题 编程
1. 数据分析题(17分):
流行病学通常关注单日治愈患者例数增长(即当日治愈例数减去前日治愈例数),并以单日治愈患者例数最高增长点作为疫情向好发展的标志点。“c:/素材/mousheng.txt”文件是以逗号分隔的2020年1月22日至3月22日某省发生新冠肺炎疫情变化数据文本文件(如图所示,提示:已按日期递增排序,有标题行)

请编写程序,找出单日治愈例数增长最高日期,若有并列最高增长日,则选择并列的最后一日。 运行结果如图所示,按图示的格式输出结果。程序保存在C:\KS目录下,名为4_1.py。

f = open("C:/素材/covid19mousheng.txt")
s = f.read()
sh = s.split('\n')
sh = sh[1:]
max = 0;year = 0;month = 0;day = 0
sh[0] = sh[0].split(',')
for i in range(1,len(sh)-1):
sh[i] = sh[i].split(',')
m = int(sh[i][4]) - int(sh[i-1][4])
if(m >= max):
max = m
a = sh[i][0].split('/')
year = a[2]
month = a[0]
day = a[1]
print("%s年%s月%s日为某省单日治愈增长最高日,较前日增长%d例"%(year,month,day,max))2. 运算题(18分):
计算结果由两部分构成:
(1) 已知

输入正整数n,用多项式的前n项之和计算p值。
(2)c:\素材\scre2020-1.5.tar.gz是某第三方智能算法包,其中包含两个函数zna(x)和znb(x),传入参数为数值类型,输出结果为字符串。请导入第三方包scre, 将第三方智能算法包的安装界面截图,保存为c:\ks\setup.jpg,并代入多项式计算结果,计算scre.zna(p)。(注:因浮点运算顺序不同的舍入误差,结果可能与样图有差异,样图仅供参考)

导入第三方包:找到setup.py文件,python setup.py install
import math
import sys
import scre
def calP(x):
sum = 0
for i in range(1,x+1):
sum = sum + 1/(i*i)
p = math.sqrt(sum * 6)
print("用多项式计算p的结果为 %s"%p)
print("最终结果为%s"%(scre.zna(p)))
if __name__ == '__main__':
while(1):
n = int(input("请输入正整数(输入0退出程序):"))
if n == 0:
sys.exit(0)
calP(n) 3. 图形绘制题(15分):
编写一个完整的程序,要求如下:
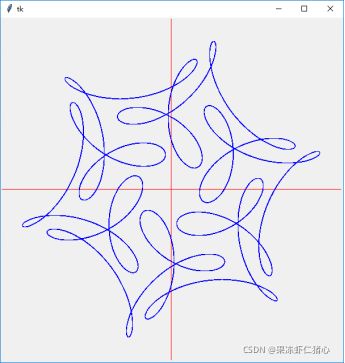
创建正方形画布,以画布中心为原点画出坐标轴,并按以下公式绘制函数曲线:
x = wh×(cos(t)+(1/2)×cos(7t)+(1/3)×sin(17t))/2
y = hh×(sin(t)+(1/2)×sin(7t)+(1/3)×cos(17t))/2
其中wh、hh的取值分别为画布的半宽和半高,t的取值范围为0至2π,步长为0.01。图形绘制结果如图所示。
程序保存在C:\KS目录下,名为 4_3.py。
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import numpy as np
h = 10
plt.figure(figsize = (h,h))
t = np.arange(0,2*np.pi,0.01)
x = h/2 * (np.cos(t) + (1/2)*np.cos(7*t) + (1/3)*np.sin(17*t))/2
y = h/2 * (np.sin(t) + (1/2)*np.sin(7*t) + (1/3)*np.cos(17*t))/2
plt.plot(x,y,color = 'blue')
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.spines['left'].set_color('red')
ax.spines['bottom'].set_color('red')
ax.spines['left'].set_position(('data',0)) #移到数字0位置
ax.spines['bottom'].set_position(('data',0))
ax.xaxis.set_major_locator(ticker.NullLocator()) #不显示刻度线
ax.yaxis.set_major_locator(ticker.NullLocator())
plt.savefig('4_3.png')
plt.show()4. 数据库应用题(12分):
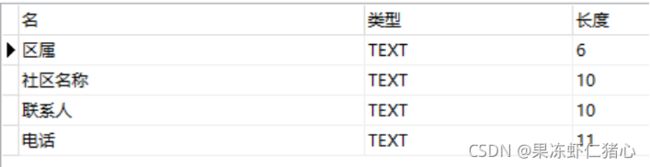
为打赢疫情防控的总体战、阻击战,建立了部分社区防疫联系人数据库。其sqlite数据库文件是c:\素材\fangyi.db,包含lianxi表,其中字段均为TEXT型(如图所示)
 请编写程序,实现输入社区名称,输出该社区联系人、电话查询结果。程序保存在C:\KS目录下,名为 4_4.py。
请编写程序,实现输入社区名称,输出该社区联系人、电话查询结果。程序保存在C:\KS目录下,名为 4_4.py。
运行结果举例如下:

import sqlite3
import sys
conn = sqlite3.connect("C:/素材/fangyi.db")
c = conn.cursor() #打开游标
sql = "Select * from lianxi"
res = c.execute(sql)
arr = res.fetchall()
a = list(arr)
while(1):
t = input('请输入社区名称:(输入0退出程序)' + '\n')
if t == '0':
sys.exit(0)
for i in range(0,len(a)):
if(t == a[i][1]):
print("联系人 电话")
print(a[i][2]," ",a[i][3])
c.close()
conn.close()5. 文本分析题(13分):
C:\素材文件夹中h.txt为已爬取的某新闻网站的静态html文本文件,其中新闻链接和标题的呈现特点是“http开头的地址" mon="ct=1&a=2&c=top&pn=1-2位数字" target="_blank">标题”,请利用正则方法,筛选其中新闻链接和标题,保存在C:\KS\news.csv(结果示例如图),程序保存在C:\KS目录下,名为 4_5.py。

import re
import csv
csvFile = open("c.csv", "w",newline='')
writer = csv.writer(csvFile)
f = open("C:/素材/h.txt")
content = f.read()
url = r'(.*?)'
link = re.findall(url, content, re.I|re.S|re.M) #有点问题,有些标题含有...不知道怎么去掉
for url in link:
writer.writerow([url[0],url[1]])
print(url)
csvFile.close()
这些代码都是在准备python考试过程中自己慢慢摸索的,可能还有很多需要改进的地方。