利用Tensorflow构建生成对抗网络GAN以生成数据
使用生成对抗网络(GAN)生成数据
本文主要内容
-
介绍了自动编码器的基本原理
-
比较了生成模型与自动编码器的区别
-
描述了GAN模型的网络结构
-
分析了GAN模型的目标核函数以及训练过程
-
介绍了利用Google Colab进行模型训练的基本步骤
-
设计并实现了简单的GAN网络,进行了网络训练以及模型评估
from IPython.display import Image
%matplotlib inline
生成对抗网络的简单介绍
首先从自动编码器开始–autoencoders
Image(filename='images/17_01.png', width=500)
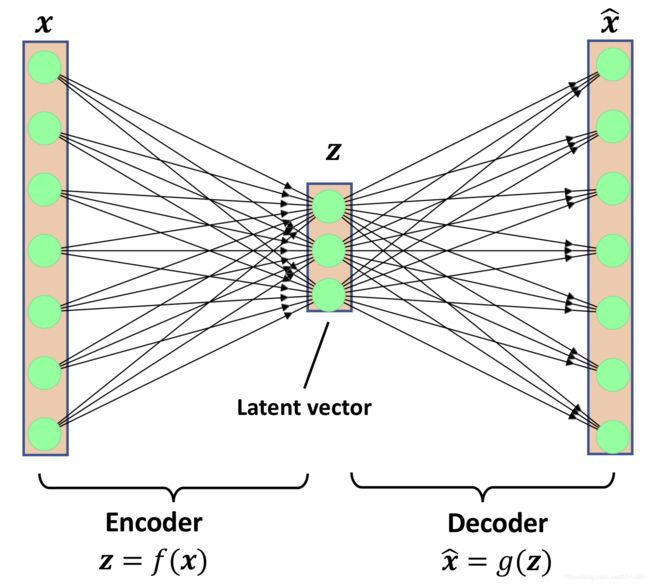
当自动编码器中两个网络不存在非线性关系时,其基本上就等同于主成分分析PCA。
上述过程的矩阵表示形式:
z = U T x (公式1) \mathbf{z}=\boldsymbol{U}^{T} \boldsymbol{x}\tag{公式1} z=UTx(公式1)
x ^ = U Z (公式2) \widehat{\boldsymbol{x}}=\boldsymbol{U} \boldsymbol{Z}\tag{公式2} x =UZ(公式2)
整体形式为:
x ^ = U U T x (公式3) \widehat{\boldsymbol{x}}=\boldsymbol{U U}^{T} \boldsymbol{x}\tag{公式3} x =UUTx(公式3)
其中,在主成分分析里面,变换矩阵的设定需要满足一个条件,即正交,表示如下:
U U T = I n × n (公式4) \boldsymbol{U U}^{T}=\boldsymbol{I}_{n \times n}\tag{公式4} UUT=In×n(公式4)
生成式模型–Generative models
生成模型与自动编码器的主要区别:在autoencoder中,我们不知道 Z Z Z的分布,但在generative模型在, Z Z Z的分布是完全可以描述的。
实际上也完全可以将autoencoder泛化为一个生成模型generative model。一种方法就是VAEs。
Image(filename='images/17_02.png', width=700)
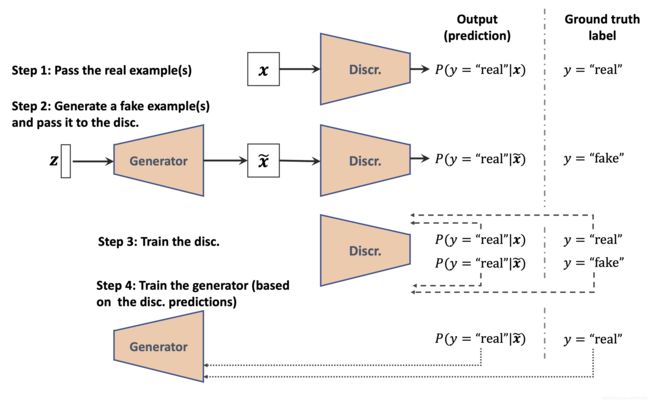
使用GANs产生新的样本数据
在GAN模型中,存在两个网络,分别是generator(生成器)和discriminator(判别器)。
首先,初始化模型权重,生成器生成那种看起来并不太真实的images数据,类似的,判别器在区分生成的图像与真实图像的任务是表现也非常差。
但随着模型的训练,所有的网络都变得更好。生成器和判别器之间像是在做一场对弈游戏,生成器在努力学习产生更逼真的输出从而实现对判别器的蒙蔽,同时
判别器也在提升对生成样本的检测能力。
Image(filename='images/17_03.png', width=700)
GAN的目标是生成与训练数据集具有相同分布的新样本。
GAN模型基于generator和discriminator网络的损失函数
生成对抗网络论文链接。文中对模型的目标函数表示如下:
V ( θ ( D ) , θ ( G ) ) = E x ∼ p data ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] (公式5) V\left(\theta^{(D)}, \theta^{(G)}\right)=E_{\boldsymbol{x} \sim p_{\text {data }}(\boldsymbol{x})}[\log D(\boldsymbol{x})]+E_{\mathbf{z} \sim p_{\boldsymbol{z}}(\mathrm{z})}[\log (1-D(G(\mathbf{z})))]\tag{公式5} V(θ(D),θ(G))=Ex∼pdata (x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))](公式5)
其中, V ( θ ( D ) , θ ( G ) ) V\left(\theta^{(D)}, \theta^{(G)}\right) V(θ(D),θ(G))叫做值函数value function。我们的目标是:
最大化其相对于判别器discriminator(D)的值,同时最小化其相对于生成器generator(G)的值。因此表示如下:
min G max D V ( θ ( D ) , θ ( G ) ) (公式6) \min _{G} \max _{D} V\left(\theta^{(D)}, \theta^{(G)}\right)\tag{公式6} GminDmaxV(θ(D),θ(G))(公式6)
其中, D ( x ) D(\boldsymbol{x}) D(x)表示的是输入样本是真实real或者虚假fake—生成的样本。
GAM网络的训练过程:
训练过程分为两个步骤:(1)最大化值函数相对于判别器的值;(2)最小化值函数相对于生成器的值;通常这两个步骤是交替进行的。
且在训练过程中,需要在固定一个网络的参数的同时,训练另一个网络。具体而言:
假设固定fixed了生成器(generator network),想优化判别器。(公式5)的第一项对应于真实样本的损失,第二项对应于fake(生成样本)的损失。
当G是固定的,我们想要最大化— maximize V ( θ ( D ) , θ ( G ) ) \operatorname{maximize} V\left(\theta^{(D)}, \theta^{(G)}\right) maximizeV(θ(D),θ(G)),这就代表试图使判别器在区分real和fake样本的
任务上具有更好的能力;
在使用基于real和fake样本的损失项对判别器进行优化之后,下面就要开始优化生成器了。
固定fixed判别器discriminator,优化生成器,此时仅仅是(公式5)的第二项包含有针对生成器的梯度。当D是固定的,我们的目标是 minimize V ( θ ( D ) , θ ( G ) ) \operatorname{minimize} V\left(\theta^{(D)}, \theta^{(G)}\right) minimizeV(θ(D),θ(G))。
此时表示如下:
min G E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] (公式7) \min _{G} E_{\mathbf{z} \sim p_{\mathbf{z}}(\mathbf{z})}[\log (1-D(G(\mathbf{z})))]\tag{公式7} GminEz∼pz(z)[log(1−D(G(z)))](公式7)
但是, log ( 1 − D ( G ( z ) ) ) \log (1-D(G(\mathbf{z}))) log(1−D(G(z)))往往会遭遇梯度消失。原因就是模型在早期的学习中,生成器所产生的样本与真实样本可能完全不同,因此 D ( G ( z ) ) D(G(\mathbf{z})) D(G(z))
将会趋近于零。因此为解决这一问题,通常会有如下形式的表示:
max G E z ∼ p z ( z ) [ log ( D ( G ( z ) ) ) ] (公式8) \max _{G} E_{\mathbf{z} \sim p_{z}(\mathbf{z})}[\log (D(G(\mathbf{z})))]\tag{公式8} GmaxEz∼pz(z)[log(D(G(z)))](公式8)
Image(filename='images/17_04.png', width=800)
利用Tensorflow实现GAN模型
在Google Colab上训练GAN模型
Image(filename='images/17_05.png', width=700)

Image(filename='images/17_06.png', width=600)

Image(filename='images/17_07.png', width=600)
# Uncomment the following line if running this notebook on Google Colab
#! pip install -q tensorflow-gpu==2.0.0
import tensorflow as tf
print(tf.__version__)
print("GPU Available:", tf.test.is_gpu_available())
# print(tf.config.list_physical_devices('GPU'))
if tf.test.is_gpu_available():
device_name = tf.test.gpu_device_name()
else:
device_name = 'cpu:0'
print(device_name)
2.1.0
GPU Available: True
/device:GPU:0
#from google.colab import drive
#drive.mount('/content/drive/')
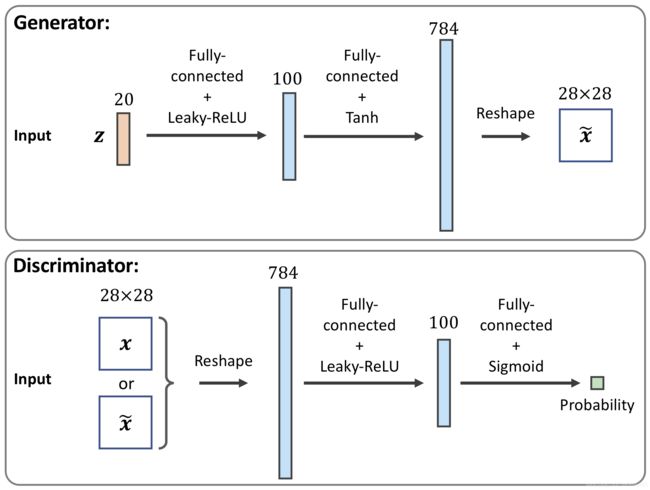
实现generator 和 discriminator 网络
Image(filename='images/17_08.png', width=600)
Image(filename='images/17_17.png', width=600)
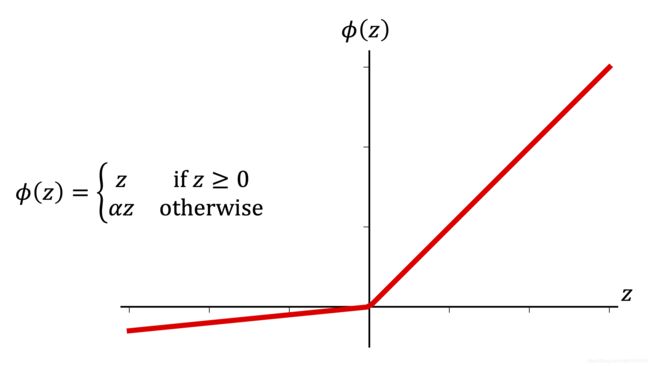
# 导入相关工具包
import tensorflow as tf
import tensorflow_datasets as tfds
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
Image(filename='images/17_08.png', width=300)
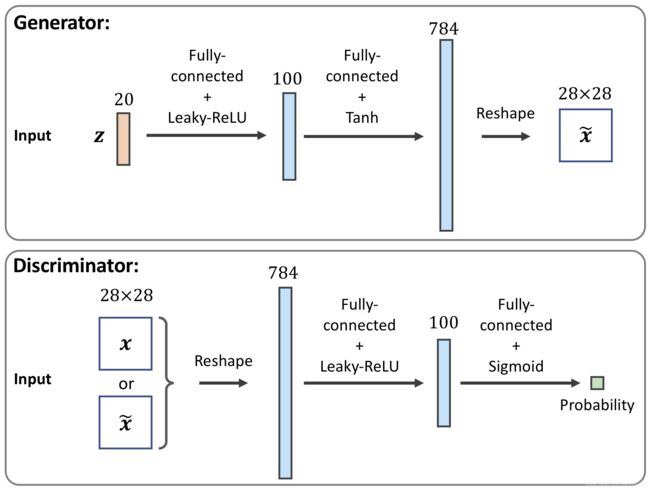
## define a function for the generator: 输出层使用的是tanh函数
def make_generator_network(
num_hidden_layers=1, # 隐层层数为1
num_hidden_units=100, # 隐层神经元为100个
num_output_units=784): # 输出层神经元为100个
model = tf.keras.Sequential() # 调用tf.keras.Sequential类创建网络
for i in range(num_hidden_layers):
model.add(
tf.keras.layers.Dense(
units=num_hidden_units, # 添加隐层
use_bias=False)
)
model.add(tf.keras.layers.LeakyReLU()) # 激活函数,带泄露的RELU
model.add(tf.keras.layers.Dense(
units=num_output_units, activation='tanh')) # 添加输出层,激活函数为
return model
## define a function for the discriminator: # 隐层后面紧跟dropout,且输出没有激活函数,一般也可以使用Sigmoid
def make_discriminator_network(
num_hidden_layers=1, # 隐层层数为1
num_hidden_units=100, # 隐层神经元为100个
num_output_units=1): # 输出层神经元为100个
model = tf.keras.Sequential() # 调用tf.keras.Sequential类创建网络,把各个层次堆叠起来
for i in range(num_hidden_layers):
model.add(tf.keras.layers.Dense(units=num_hidden_units)) # 添加隐层,形式为全连接
model.add(tf.keras.layers.LeakyReLU()) # 添加激活函数,LeakyRELU
model.add(tf.keras.layers.Dropout(rate=0.5)) # 添加Dropout,rate设置为0.5
model.add(
tf.keras.layers.Dense(
units=num_output_units, # 添加输出层,没有激活函数
activation=None)
)
return model
image_size = (28, 28) # MNIST数据的像素为28x28 pixels
z_size = 20 # 指定输入向量的size,大小为20
mode_z = 'uniform' # 'uniform' vs. 'normal' # 这里使用均匀分布初始化模型权重
gen_hidden_layers = 1
gen_hidden_size = 100
disc_hidden_layers = 1
disc_hidden_size = 100
tf.random.set_seed(1)
gen_model = make_generator_network(
num_hidden_layers=gen_hidden_layers,
num_hidden_units=gen_hidden_size,
num_output_units=np.prod(image_size))
gen_model.build(input_shape=(None, z_size))
gen_model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) multiple 2000
_________________________________________________________________
leaky_re_lu (LeakyReLU) multiple 0
_________________________________________________________________
dense_1 (Dense) multiple 79184
=================================================================
Total params: 81,184
Trainable params: 81,184
Non-trainable params: 0
_________________________________________________________________
disc_model = make_discriminator_network(
num_hidden_layers=disc_hidden_layers,
num_hidden_units=disc_hidden_size)
disc_model.build(input_shape=(None, np.prod(image_size)))
disc_model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) multiple 78500
_________________________________________________________________
leaky_re_lu_1 (LeakyReLU) multiple 0
_________________________________________________________________
dropout (Dropout) multiple 0
_________________________________________________________________
dense_3 (Dense) multiple 101
=================================================================
Total params: 78,601
Trainable params: 78,601
Non-trainable params: 0
_________________________________________________________________
构建训练数据集
由于generator的输出层使用的是tanh激活函数,因此合成图像的像素值将在 ( − 1 , 1 ) (-1, 1) (−1,1)范围内。
然而,MNIST数据图像的输入像素范围在[0, 255], 但Tensorflow data type为tf.uint8。因此这里要使用tf.image.convert_image_dtype函数实现图像数据的类
型转换。调用这个函数更改数据类型之外,它也会将输入像素的取值范围更改为[0, 1]。
实现将上述的像素范围改为[-1, 1],可以直接乘以2,减去1得到。
mnist_bldr = tfds.builder('mnist')
mnist_bldr.download_and_prepare()
mnist = mnist_bldr.as_dataset(shuffle_files=False)
def preprocess(ex, mode='uniform'):
image = ex['image']
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.reshape(image, [-1])
image = image*2 - 1.0
if mode == 'uniform':
input_z = tf.random.uniform( # 从均匀分布或者正态分布中创建随机向量z,
shape=(z_size,), minval=-1.0, maxval=1.0)
elif mode == 'normal':
input_z = tf.random.normal(shape=(z_size,))
return input_z, image # 函数将返回处理后的图像和前面随机初始化得到的向量z,两者以一个元组形式返回
mnist_trainset = mnist['train']
print('Before preprocessing: ')
example = next(iter(mnist_trainset))['image']
print('dtype: ', example.dtype, ' Min: {} Max: {}'.format(np.min(example), np.max(example)))
mnist_trainset = mnist_trainset.map(preprocess)
print('After preprocessing: ')
example = next(iter(mnist_trainset))[0]
print('dtype: ', example.dtype, ' Min: {} Max: {}'.format(np.min(example), np.max(example)))
Before preprocessing:
dtype: Min: 0 Max: 255
After preprocessing:
dtype: Min: -0.6264450550079346 Max: 0.9958574771881104
这里的image源于数据集,z是通过随机初始化得到的输入向量。
z代表的是generator所接受的,用于生成新图像的输入;
image代表的是输入到discriminator中的图像images;
- Step-by-step walk through the data-flow
"""
检查所创建的数据
"""
mnist_trainset = mnist_trainset.batch(32, drop_remainder=True)
input_z, input_real = next(iter(mnist_trainset))
print('input-z -- shape:', input_z.shape)
print('input-real -- shape:', input_real.shape)
"""
将这批输入向量z提供给generator,以得到他的输出,g_output----这对应的是一batch的fake examples
"""
g_output = gen_model(input_z)
print('Output of G -- shape:', g_output.shape)
"""
上述输出提供给discriminator,从而得到批量fake examples的logits,即 d_logits_fake
同时,来自于真实数据集,且被处理过后的images也将被提供给discriminator,从而得到real examples的d_logits_real.
"""
d_logits_real = disc_model(input_real)
d_logits_fake = disc_model(g_output)
print('Disc. (real) -- shape:', d_logits_real.shape)
print('Disc. (fake) -- shape:', d_logits_fake.shape)
input-z -- shape: (32, 20)
input-real -- shape: (32, 784)
Output of G -- shape: (32, 784)
Disc. (real) -- shape: (32, 1)
Disc. (fake) -- shape: (32, 1)
上述得到的两个几率,d_logits_fake和d_logits_real将被用于计算损失函数,从而用于训练模型。
训练GAN 模型
这里结合二分类交叉熵损失函数来计算generator和discriminator的损失。
为了做到这一点,我们需要得到每个输出的真实标签。
对于generator,这里创建一个全1向量,它的shape与包含生成图像的预测几率的向量d_logits_fake的向量相同。
对于discriminator 损失,这里包含两项:其中包括d_logits_fake和检测真实样本的损失d_logits_real。
V ( θ ( D ) , θ ( G ) ) = E x ∼ p data ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] V\left(\theta^{(D)}, \theta^{(G)}\right)=E_{\boldsymbol{x} \sim p_{\text {data }}(\boldsymbol{x})}[\log D(\boldsymbol{x})]+E_{\mathbf{z} \sim p_{\mathbf{z}}(\mathbf{z})}[\log (1-D(G(\mathbf{z})))] V(θ(D),θ(G))=Ex∼pdata (x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
loss_fn = tf.keras.losses.BinaryCrossentropy(from_logits=True)
## Loss for the Generator
g_labels_real = tf.ones_like(d_logits_fake)
g_loss = loss_fn(y_true=g_labels_real, y_pred=d_logits_fake)
print('Generator Loss: {:.4f}'.format(g_loss))
## Loss for the Discriminator
d_labels_real = tf.ones_like(d_logits_real)
d_labels_fake = tf.zeros_like(d_logits_fake)
d_loss_real = loss_fn(y_true=d_labels_real, y_pred=d_logits_real)
d_loss_fake = loss_fn(y_true=d_labels_fake, y_pred=d_logits_fake)
print('Discriminator Losses: Real {:.4f} Fake {:.4f}'
.format(d_loss_real.numpy(), d_loss_fake.numpy()))
Generator Loss: 0.7505
Discriminator Losses: Real 1.5073 Fake 0.6434
- 整体过程
import time
num_epochs = 100
batch_size = 64
image_size = (28, 28)
z_size = 20
mode_z = 'uniform'
gen_hidden_layers = 1
gen_hidden_size = 100
disc_hidden_layers = 1
disc_hidden_size = 100
tf.random.set_seed(1)
np.random.seed(1)
if mode_z == 'uniform':
fixed_z = tf.random.uniform(
shape=(batch_size, z_size),
minval=-1, maxval=1)
elif mode_z == 'normal':
fixed_z = tf.random.normal(
shape=(batch_size, z_size))
def create_samples(g_model, input_z):
g_output = g_model(input_z, training=False)
images = tf.reshape(g_output, (batch_size, *image_size))
return (images+1)/2.0
## Set-up the dataset
mnist_trainset = mnist['train']
mnist_trainset = mnist_trainset.map(
lambda ex: preprocess(ex, mode=mode_z))
mnist_trainset = mnist_trainset.shuffle(10000)
mnist_trainset = mnist_trainset.batch(
batch_size, drop_remainder=True)
## Set-up the model
with tf.device(device_name):
gen_model = make_generator_network(
num_hidden_layers=gen_hidden_layers,
num_hidden_units=gen_hidden_size,
num_output_units=np.prod(image_size))
gen_model.build(input_shape=(None, z_size))
disc_model = make_discriminator_network(
num_hidden_layers=disc_hidden_layers,
num_hidden_units=disc_hidden_size)
disc_model.build(input_shape=(None, np.prod(image_size)))
## Loss function and optimizers:
loss_fn = tf.keras.losses.BinaryCrossentropy(from_logits=True)
g_optimizer = tf.keras.optimizers.Adam()
d_optimizer = tf.keras.optimizers.Adam()
all_losses = []
all_d_vals = []
epoch_samples = []
start_time = time.time()
for epoch in range(1, num_epochs+1):
epoch_losses, epoch_d_vals = [], []
for i,(input_z,input_real) in enumerate(mnist_trainset):
## Compute generator's loss
with tf.GradientTape() as g_tape:
g_output = gen_model(input_z)
d_logits_fake = disc_model(g_output, training=True)
labels_real = tf.ones_like(d_logits_fake)
g_loss = loss_fn(y_true=labels_real, y_pred=d_logits_fake)
g_grads = g_tape.gradient(g_loss, gen_model.trainable_variables)
g_optimizer.apply_gradients(
grads_and_vars=zip(g_grads, gen_model.trainable_variables))
## Compute discriminator's loss
with tf.GradientTape() as d_tape:
d_logits_real = disc_model(input_real, training=True)
d_labels_real = tf.ones_like(d_logits_real)
d_loss_real = loss_fn(
y_true=d_labels_real, y_pred=d_logits_real)
d_logits_fake = disc_model(g_output, training=True)
d_labels_fake = tf.zeros_like(d_logits_fake)
d_loss_fake = loss_fn(
y_true=d_labels_fake, y_pred=d_logits_fake)
d_loss = d_loss_real + d_loss_fake
## Compute the gradients of d_loss
d_grads = d_tape.gradient(d_loss, disc_model.trainable_variables)
## Optimization: Apply the gradients
d_optimizer.apply_gradients(
grads_and_vars=zip(d_grads, disc_model.trainable_variables))
epoch_losses.append(
(g_loss.numpy(), d_loss.numpy(),
d_loss_real.numpy(), d_loss_fake.numpy()))
d_probs_real = tf.reduce_mean(tf.sigmoid(d_logits_real))
d_probs_fake = tf.reduce_mean(tf.sigmoid(d_logits_fake))
epoch_d_vals.append((d_probs_real.numpy(), d_probs_fake.numpy()))
all_losses.append(epoch_losses)
all_d_vals.append(epoch_d_vals)
print(
'Epoch {:03d} | ET {:.2f} min | Avg Losses >>'
' G/D {:.4f}/{:.4f} [D-Real: {:.4f} D-Fake: {:.4f}]'
.format(
epoch, (time.time() - start_time)/60,
*list(np.mean(all_losses[-1], axis=0))))
epoch_samples.append(
create_samples(gen_model, fixed_z).numpy())
Epoch 001 | ET 0.62 min | Avg Losses >> G/D 2.9725/0.2859 [D-Real: 0.0318 D-Fake: 0.2540]
Epoch 002 | ET 1.03 min | Avg Losses >> G/D 4.9018/0.3412 [D-Real: 0.1136 D-Fake: 0.2276]
Epoch 003 | ET 1.43 min | Avg Losses >> G/D 3.2743/0.6966 [D-Real: 0.3073 D-Fake: 0.3893]
Epoch 004 | ET 1.83 min | Avg Losses >> G/D 2.0788/0.8689 [D-Real: 0.4436 D-Fake: 0.4252]
Epoch 005 | ET 2.24 min | Avg Losses >> G/D 2.1288/0.8016 [D-Real: 0.4373 D-Fake: 0.3643]
Epoch 006 | ET 2.62 min | Avg Losses >> G/D 1.8294/0.9176 [D-Real: 0.4901 D-Fake: 0.4275]
Epoch 007 | ET 3.01 min | Avg Losses >> G/D 1.5428/1.0126 [D-Real: 0.5415 D-Fake: 0.4711]
Epoch 008 | ET 3.39 min | Avg Losses >> G/D 1.4945/1.0041 [D-Real: 0.5434 D-Fake: 0.4607]
Epoch 009 | ET 3.78 min | Avg Losses >> G/D 1.4962/0.9985 [D-Real: 0.5483 D-Fake: 0.4503]
Epoch 010 | ET 4.16 min | Avg Losses >> G/D 1.3668/1.0592 [D-Real: 0.5722 D-Fake: 0.4870]
Epoch 011 | ET 4.56 min | Avg Losses >> G/D 1.2842/1.1204 [D-Real: 0.5951 D-Fake: 0.5254]
Epoch 012 | ET 4.95 min | Avg Losses >> G/D 1.3766/1.0685 [D-Real: 0.5635 D-Fake: 0.5049]
Epoch 013 | ET 5.33 min | Avg Losses >> G/D 1.2320/1.1680 [D-Real: 0.6056 D-Fake: 0.5624]
Epoch 014 | ET 5.71 min | Avg Losses >> G/D 1.2143/1.1424 [D-Real: 0.5975 D-Fake: 0.5449]
Epoch 015 | ET 6.09 min | Avg Losses >> G/D 1.1790/1.1791 [D-Real: 0.6096 D-Fake: 0.5694]
Epoch 016 | ET 6.48 min | Avg Losses >> G/D 1.1176/1.1989 [D-Real: 0.6208 D-Fake: 0.5781]
Epoch 017 | ET 6.87 min | Avg Losses >> G/D 1.2007/1.1699 [D-Real: 0.6031 D-Fake: 0.5669]
Epoch 018 | ET 7.26 min | Avg Losses >> G/D 1.1197/1.2071 [D-Real: 0.6169 D-Fake: 0.5902]
Epoch 019 | ET 7.64 min | Avg Losses >> G/D 1.1493/1.1879 [D-Real: 0.6129 D-Fake: 0.5750]
Epoch 020 | ET 8.02 min | Avg Losses >> G/D 1.1159/1.2043 [D-Real: 0.6152 D-Fake: 0.5890]
Epoch 021 | ET 8.42 min | Avg Losses >> G/D 1.0957/1.1994 [D-Real: 0.6165 D-Fake: 0.5829]
Epoch 022 | ET 8.80 min | Avg Losses >> G/D 1.1403/1.1988 [D-Real: 0.6109 D-Fake: 0.5879]
Epoch 023 | ET 9.20 min | Avg Losses >> G/D 1.1028/1.2088 [D-Real: 0.6165 D-Fake: 0.5923]
Epoch 024 | ET 9.58 min | Avg Losses >> G/D 1.0557/1.2266 [D-Real: 0.6259 D-Fake: 0.6007]
Epoch 025 | ET 9.97 min | Avg Losses >> G/D 1.0378/1.2336 [D-Real: 0.6280 D-Fake: 0.6056]
Epoch 026 | ET 10.36 min | Avg Losses >> G/D 1.0593/1.2395 [D-Real: 0.6286 D-Fake: 0.6109]
Epoch 027 | ET 10.75 min | Avg Losses >> G/D 1.1011/1.2276 [D-Real: 0.6214 D-Fake: 0.6063]
Epoch 028 | ET 11.14 min | Avg Losses >> G/D 0.9897/1.2411 [D-Real: 0.6319 D-Fake: 0.6092]
Epoch 029 | ET 11.52 min | Avg Losses >> G/D 1.0854/1.2433 [D-Real: 0.6279 D-Fake: 0.6154]
Epoch 030 | ET 11.91 min | Avg Losses >> G/D 1.0929/1.2540 [D-Real: 0.6290 D-Fake: 0.6250]
Epoch 031 | ET 12.29 min | Avg Losses >> G/D 0.9627/1.2728 [D-Real: 0.6458 D-Fake: 0.6270]
Epoch 032 | ET 12.67 min | Avg Losses >> G/D 0.9482/1.2796 [D-Real: 0.6466 D-Fake: 0.6330]
Epoch 033 | ET 13.04 min | Avg Losses >> G/D 1.0746/1.2406 [D-Real: 0.6254 D-Fake: 0.6152]
Epoch 034 | ET 13.42 min | Avg Losses >> G/D 1.0286/1.2480 [D-Real: 0.6310 D-Fake: 0.6169]
Epoch 035 | ET 13.79 min | Avg Losses >> G/D 0.9617/1.2580 [D-Real: 0.6362 D-Fake: 0.6218]
Epoch 036 | ET 14.17 min | Avg Losses >> G/D 0.9727/1.2907 [D-Real: 0.6484 D-Fake: 0.6423]
Epoch 037 | ET 14.54 min | Avg Losses >> G/D 1.0502/1.2549 [D-Real: 0.6293 D-Fake: 0.6256]
Epoch 038 | ET 14.92 min | Avg Losses >> G/D 1.0158/1.2591 [D-Real: 0.6344 D-Fake: 0.6247]
Epoch 039 | ET 15.30 min | Avg Losses >> G/D 0.9446/1.2818 [D-Real: 0.6475 D-Fake: 0.6343]
Epoch 040 | ET 15.68 min | Avg Losses >> G/D 0.9448/1.2953 [D-Real: 0.6526 D-Fake: 0.6427]
Epoch 041 | ET 16.05 min | Avg Losses >> G/D 0.9873/1.2892 [D-Real: 0.6458 D-Fake: 0.6433]
Epoch 042 | ET 16.43 min | Avg Losses >> G/D 0.9799/1.2914 [D-Real: 0.6486 D-Fake: 0.6428]
Epoch 043 | ET 16.81 min | Avg Losses >> G/D 0.9127/1.3064 [D-Real: 0.6548 D-Fake: 0.6516]
Epoch 044 | ET 17.19 min | Avg Losses >> G/D 0.9510/1.3005 [D-Real: 0.6516 D-Fake: 0.6489]
Epoch 045 | ET 17.56 min | Avg Losses >> G/D 1.0084/1.2852 [D-Real: 0.6430 D-Fake: 0.6422]
Epoch 046 | ET 17.94 min | Avg Losses >> G/D 0.9395/1.3063 [D-Real: 0.6549 D-Fake: 0.6514]
Epoch 047 | ET 18.32 min | Avg Losses >> G/D 0.8963/1.3105 [D-Real: 0.6597 D-Fake: 0.6507]
Epoch 048 | ET 18.69 min | Avg Losses >> G/D 0.9818/1.2986 [D-Real: 0.6482 D-Fake: 0.6504]
Epoch 049 | ET 19.07 min | Avg Losses >> G/D 0.9595/1.2969 [D-Real: 0.6485 D-Fake: 0.6484]
Epoch 050 | ET 19.45 min | Avg Losses >> G/D 0.9079/1.3082 [D-Real: 0.6609 D-Fake: 0.6473]
Epoch 051 | ET 19.83 min | Avg Losses >> G/D 0.9214/1.3081 [D-Real: 0.6566 D-Fake: 0.6515]
Epoch 052 | ET 20.20 min | Avg Losses >> G/D 0.9788/1.2894 [D-Real: 0.6477 D-Fake: 0.6417]
Epoch 053 | ET 20.57 min | Avg Losses >> G/D 0.9589/1.2928 [D-Real: 0.6500 D-Fake: 0.6428]
Epoch 054 | ET 20.95 min | Avg Losses >> G/D 0.9073/1.2951 [D-Real: 0.6522 D-Fake: 0.6429]
Epoch 055 | ET 21.33 min | Avg Losses >> G/D 0.9531/1.3003 [D-Real: 0.6500 D-Fake: 0.6503]
Epoch 056 | ET 21.71 min | Avg Losses >> G/D 0.9475/1.3060 [D-Real: 0.6544 D-Fake: 0.6516]
Epoch 057 | ET 22.08 min | Avg Losses >> G/D 0.9199/1.3078 [D-Real: 0.6567 D-Fake: 0.6511]
Epoch 058 | ET 22.46 min | Avg Losses >> G/D 0.9505/1.3013 [D-Real: 0.6542 D-Fake: 0.6470]
Epoch 059 | ET 22.83 min | Avg Losses >> G/D 0.9508/1.3053 [D-Real: 0.6555 D-Fake: 0.6498]
Epoch 060 | ET 23.20 min | Avg Losses >> G/D 0.9308/1.3126 [D-Real: 0.6589 D-Fake: 0.6536]
Epoch 061 | ET 23.58 min | Avg Losses >> G/D 0.9127/1.3087 [D-Real: 0.6577 D-Fake: 0.6510]
Epoch 062 | ET 23.96 min | Avg Losses >> G/D 0.8953/1.3123 [D-Real: 0.6585 D-Fake: 0.6538]
Epoch 063 | ET 24.34 min | Avg Losses >> G/D 0.9309/1.3082 [D-Real: 0.6567 D-Fake: 0.6515]
Epoch 064 | ET 24.71 min | Avg Losses >> G/D 0.9601/1.3109 [D-Real: 0.6555 D-Fake: 0.6555]
Epoch 065 | ET 25.09 min | Avg Losses >> G/D 0.9139/1.3030 [D-Real: 0.6565 D-Fake: 0.6465]
Epoch 066 | ET 25.47 min | Avg Losses >> G/D 0.9159/1.3070 [D-Real: 0.6565 D-Fake: 0.6505]
Epoch 067 | ET 25.85 min | Avg Losses >> G/D 0.9145/1.3145 [D-Real: 0.6586 D-Fake: 0.6559]
Epoch 068 | ET 26.22 min | Avg Losses >> G/D 0.9500/1.3006 [D-Real: 0.6519 D-Fake: 0.6487]
Epoch 069 | ET 26.60 min | Avg Losses >> G/D 0.9083/1.3130 [D-Real: 0.6577 D-Fake: 0.6553]
Epoch 070 | ET 26.98 min | Avg Losses >> G/D 0.9207/1.3069 [D-Real: 0.6554 D-Fake: 0.6516]
Epoch 071 | ET 27.35 min | Avg Losses >> G/D 0.9009/1.3231 [D-Real: 0.6648 D-Fake: 0.6584]
Epoch 072 | ET 27.73 min | Avg Losses >> G/D 0.9384/1.3106 [D-Real: 0.6567 D-Fake: 0.6539]
Epoch 073 | ET 28.10 min | Avg Losses >> G/D 0.9678/1.3089 [D-Real: 0.6548 D-Fake: 0.6540]
Epoch 074 | ET 28.48 min | Avg Losses >> G/D 0.8750/1.3167 [D-Real: 0.6616 D-Fake: 0.6551]
Epoch 075 | ET 28.85 min | Avg Losses >> G/D 0.9425/1.3098 [D-Real: 0.6559 D-Fake: 0.6539]
Epoch 076 | ET 29.23 min | Avg Losses >> G/D 0.9719/1.2975 [D-Real: 0.6459 D-Fake: 0.6517]
Epoch 077 | ET 29.61 min | Avg Losses >> G/D 0.8828/1.3186 [D-Real: 0.6621 D-Fake: 0.6565]
Epoch 078 | ET 29.98 min | Avg Losses >> G/D 0.8964/1.3293 [D-Real: 0.6674 D-Fake: 0.6620]
Epoch 079 | ET 30.36 min | Avg Losses >> G/D 1.0005/1.2964 [D-Real: 0.6498 D-Fake: 0.6466]
Epoch 080 | ET 30.74 min | Avg Losses >> G/D 0.9073/1.3099 [D-Real: 0.6610 D-Fake: 0.6489]
Epoch 081 | ET 31.12 min | Avg Losses >> G/D 0.8859/1.3183 [D-Real: 0.6635 D-Fake: 0.6548]
Epoch 082 | ET 31.50 min | Avg Losses >> G/D 0.9480/1.3096 [D-Real: 0.6562 D-Fake: 0.6534]
Epoch 083 | ET 31.88 min | Avg Losses >> G/D 0.8958/1.3199 [D-Real: 0.6622 D-Fake: 0.6578]
Epoch 084 | ET 32.25 min | Avg Losses >> G/D 0.9297/1.3130 [D-Real: 0.6577 D-Fake: 0.6554]
Epoch 085 | ET 32.63 min | Avg Losses >> G/D 0.9062/1.3174 [D-Real: 0.6611 D-Fake: 0.6563]
Epoch 086 | ET 33.01 min | Avg Losses >> G/D 0.9131/1.3172 [D-Real: 0.6608 D-Fake: 0.6564]
Epoch 087 | ET 33.39 min | Avg Losses >> G/D 0.9357/1.3123 [D-Real: 0.6574 D-Fake: 0.6549]
Epoch 088 | ET 33.77 min | Avg Losses >> G/D 0.8964/1.3147 [D-Real: 0.6580 D-Fake: 0.6568]
Epoch 089 | ET 34.15 min | Avg Losses >> G/D 0.9122/1.3161 [D-Real: 0.6605 D-Fake: 0.6556]
Epoch 090 | ET 34.52 min | Avg Losses >> G/D 0.9392/1.3040 [D-Real: 0.6524 D-Fake: 0.6516]
Epoch 091 | ET 34.90 min | Avg Losses >> G/D 0.8813/1.3224 [D-Real: 0.6660 D-Fake: 0.6563]
Epoch 092 | ET 35.28 min | Avg Losses >> G/D 0.9050/1.3219 [D-Real: 0.6616 D-Fake: 0.6604]
Epoch 093 | ET 35.66 min | Avg Losses >> G/D 0.9402/1.3117 [D-Real: 0.6582 D-Fake: 0.6535]
Epoch 094 | ET 36.04 min | Avg Losses >> G/D 0.9148/1.3156 [D-Real: 0.6599 D-Fake: 0.6557]
Epoch 095 | ET 36.41 min | Avg Losses >> G/D 0.9022/1.3266 [D-Real: 0.6660 D-Fake: 0.6606]
Epoch 096 | ET 36.79 min | Avg Losses >> G/D 0.9276/1.3198 [D-Real: 0.6620 D-Fake: 0.6577]
Epoch 097 | ET 37.17 min | Avg Losses >> G/D 0.9103/1.3130 [D-Real: 0.6595 D-Fake: 0.6535]
Epoch 098 | ET 37.54 min | Avg Losses >> G/D 0.9094/1.3290 [D-Real: 0.6681 D-Fake: 0.6609]
Epoch 099 | ET 37.92 min | Avg Losses >> G/D 0.9064/1.3206 [D-Real: 0.6625 D-Fake: 0.6581]
Epoch 100 | ET 38.30 min | Avg Losses >> G/D 0.9175/1.3190 [D-Real: 0.6612 D-Fake: 0.6577]
#import pickle
# pickle.dump({'all_losses':all_losses,
# 'all_d_vals':all_d_vals,
# 'samples':epoch_samples},
# open('/content/drive/My Drive/Colab Notebooks/PyML-3rd-edition/ch17-vanila-learning.pkl', 'wb'))
#gen_model.save('/content/drive/My Drive/Colab Notebooks/PyML-3rd-edition/ch17-vanila-gan_gen.h5')
#disc_model.save('/content/drive/My Drive/Colab Notebooks/PyML-3rd-edition/ch17-vanila-gan_disc.h5')
import itertools
fig = plt.figure(figsize=(16, 6))
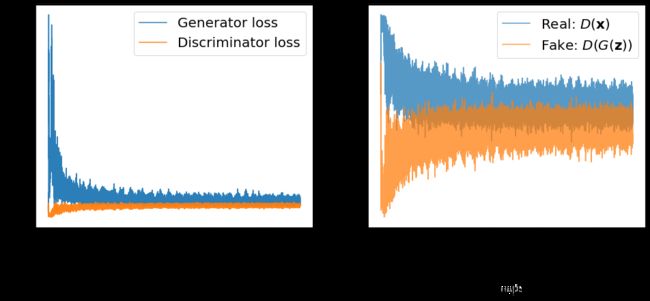
## Plotting the losses
ax = fig.add_subplot(1, 2, 1)
g_losses = [item[0] for item in itertools.chain(*all_losses)]
d_losses = [item[1]/2.0 for item in itertools.chain(*all_losses)]
plt.plot(g_losses, label='Generator loss', alpha=0.95)
plt.plot(d_losses, label='Discriminator loss', alpha=0.95)
plt.legend(fontsize=20)
ax.set_xlabel('Iteration', size=15)
ax.set_ylabel('Loss', size=15)
epochs = np.arange(1, 101)
epoch2iter = lambda e: e*len(all_losses[-1])
epoch_ticks = [1, 20, 40, 60, 80, 100]
newpos = [epoch2iter(e) for e in epoch_ticks]
ax2 = ax.twiny()
ax2.set_xticks(newpos)
ax2.set_xticklabels(epoch_ticks)
ax2.xaxis.set_ticks_position('bottom')
ax2.xaxis.set_label_position('bottom')
ax2.spines['bottom'].set_position(('outward', 60))
ax2.set_xlabel('Epoch', size=15)
ax2.set_xlim(ax.get_xlim())
ax.tick_params(axis='both', which='major', labelsize=15)
ax2.tick_params(axis='both', which='major', labelsize=15)
## Plotting the outputs of the discriminator
ax = fig.add_subplot(1, 2, 2)
d_vals_real = [item[0] for item in itertools.chain(*all_d_vals)]
d_vals_fake = [item[1] for item in itertools.chain(*all_d_vals)]
plt.plot(d_vals_real, alpha=0.75, label=r'Real: $D(\mathbf{x})$')
plt.plot(d_vals_fake, alpha=0.75, label=r'Fake: $D(G(\mathbf{z}))$')
plt.legend(fontsize=20)
ax.set_xlabel('Iteration', size=15)
ax.set_ylabel('Discriminator output', size=15)
ax2 = ax.twiny()
ax2.set_xticks(newpos)
ax2.set_xticklabels(epoch_ticks)
ax2.xaxis.set_ticks_position('bottom')
ax2.xaxis.set_label_position('bottom')
ax2.spines['bottom'].set_position(('outward', 60))
ax2.set_xlabel('Epoch', size=15)
ax2.set_xlim(ax.get_xlim())
ax.tick_params(axis='both', which='major', labelsize=15)
ax2.tick_params(axis='both', which='major', labelsize=15)
#plt.savefig('images/ch17-gan-learning-curve.pdf')
plt.show()
selected_epochs = [1, 2, 4, 10, 50, 100]
fig = plt.figure(figsize=(10, 14))
for i,e in enumerate(selected_epochs):
for j in range(5):
ax = fig.add_subplot(6, 5, i*5+j+1)
ax.set_xticks([])
ax.set_yticks([])
if j == 0:
ax.text(
-0.06, 0.5, 'Epoch {}'.format(e),
rotation=90, size=18, color='red',
horizontalalignment='right',
verticalalignment='center',
transform=ax.transAxes)
image = epoch_samples[e-1][j]
ax.imshow(image, cmap='gray_r')
#plt.savefig('images/ch17-vanila-gan-samples.pdf')
plt.show()

从上图可以看出,随着训练的进行,generator生成的图像越来越逼真。但是,在经过100个epoch之后,生成的图像与MNIST数据集中包含的手写数字相比,仍然具有较大的差异。
前面提到,NN中的卷积操作有诸多好处,比如可以更好地捕捉到图像数据中的局部特征,因此可以考虑在GAN模型中添加卷积层以试图提升模型的输出。下面将实现一个deep convolutional GAN(DCGAN)。它在generator和discriminator网络中都添加了卷积层。