古典人像秒变3D,视角还能随意切,华为&上交联手出品
明敏 发自 凹非寺
量子位 报道 | 公众号 QbitAI
如果让GAN生成的逼真人像变成3D版,会怎样?
仿佛有摄像机对着人像直拍,正面、侧面、仰视、俯视不同角度都能展现。
真的有种人要从画中走出来那味儿了。
而且,这些效果都是由静态单视角图片生成的!
甚至能让卡通人像立体起来。
这就是上海交通大学和华为的最新研究:CIPS-3D。
它是一种基于GAN的3D感知生成器,只用原始单视角图像,无需任何上采样,就能生成分辨率256×256的清晰图像。

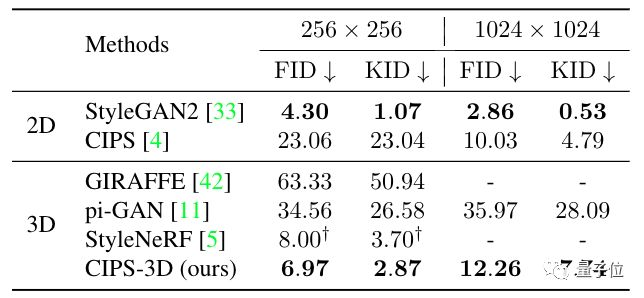
并且创下3D感知图像合成的新记录,FID仅为6.97。
现在,这个项目在GitHub上已有200+星,作者已将源代码开源,训练配置文件将在后续发布。
搞定镜像对称
在高清人脸数据集FFHQ上,CIPS-3D的表现可以说非常nice,连古典画都能变成立体版。
当然也能搞定不同动物的face。

看到图像从2D直接变成3D,可能有人已经想到了谷歌大名鼎鼎的NeRF。
它只需要输入少量静态图片,就能做到多视角的逼真3D效果。
而这次的CIPS-3D,也是基于NeRF开发。
它主要用到了两个网络:NeRF和INR(隐式神经表示法,Implicit Neural Representations)。
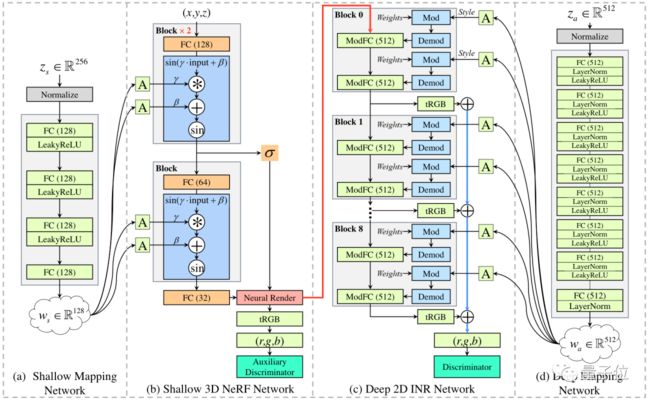
浅层是NeRF,它主要负责把人像从2D变为3D。
它将场景的体积表示优化为向量函数,输入为3D位置坐标和视图方向。
具体而言,就是沿相机射线采样信息,来合成图像。
然后,将这样的场景表示参数化为一个完全连接深度网络(MLP),输出对应的颜色和体积密度值。
为了获得更为准确的3D图像,往往需要对每条光线上多点采样,这也就造成NeRF所需的内存非常大。
因此,如果神经网络中只用NeRF,就会限制网络的深度,导致生成图像模糊、缺乏细节。

△第一列为NeRF生成,第二列为INR生成
所以在CIFS-3D中,研究人员将深层网络设置为INR,让它负责合成高保真的图像。
这种方法也能将各种信号参数化,输出RGB值。
而且由于不再与空间分辨率耦合,它可以对任意空间分辨率进行采样。
论文中也提到,该方法也没有任何上采样。
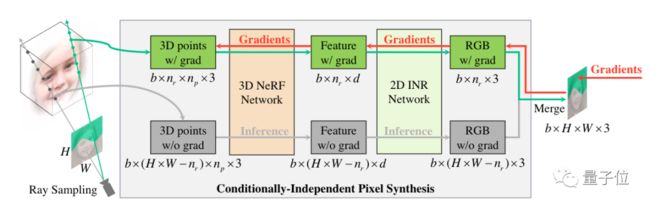
但是受限于CPU内存,如果直接训练高分辨率图像会有一定难度,为此研究人员提出了一种部分梯度反向传播的方法。
在训练时,该方法进对随机采样中的绿色光线进行梯度反向传播计算,其余光线则不计算。
解决了3D化问题,还能保证高保真,你以为这就结束了?
NO、NO、NO
在研究过程中,工作人员发现CIPS-3D还存在镜像对称问题。
这种现象其实在许多3D GAN中都存在,比如GIRAFFE、StyleNeRF。
比如在下面这个案例中,初始单角度图像的刘海是偏左的,但是生成的不同角度图像中,刘海会随着视角的变化而变化,就像是镜像一样。

出现这样的问题,是因为NeRF网络输入的坐标就有存在镜像对称。
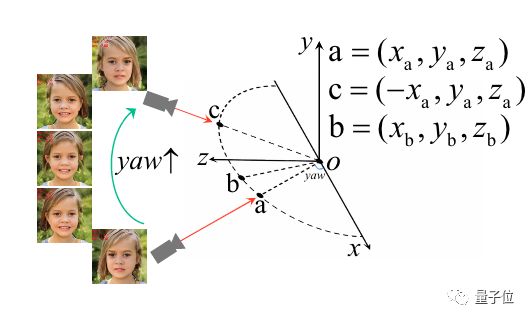
比如图中a、c两点的坐标就是完全镜像对称的关系。
这对于生成完全对称的物体而言没什么问题。
但是放在只给侧面角度的人像上来说,可能就是一场灾难。
为此,研究人员在神经网络中添加了一个鉴别器(discriminator),让它来辅助鉴别这种问题。
最后结果表明,与其他可生成3D人像的方法相比,FID、KID值明显降低,这两个值越低意味着生成图像质量越好。
团队介绍
值得一提的是,该论文通讯作者为田奇。

田奇,美国伊利诺伊大学香槟分校博士、IEEE Fellow, 也是原UTSA计算机系正教授。
发表文章约550余篇,包括250+ IEEE TPAMI、IJCV、CVPR/ICCV/ECCV、NeurIPS等国际顶级期刊和会议。
2018年加入华为云,研究主要方向为计算机视觉、自然语言处理和语音交互。
华为谢凌曦博士、上海交通大学倪冰冰教授也参与了此次研究。
谢凌曦,本科博士均毕业于清华大学计算机专业,专长计算机视觉、自动机器学习。目前为华为高级研究员。

倪冰冰,现为上海交通大学电子系特别研究员/长聘教轨副教授,博士生导师。
本科毕业于上海交通大学电子工程系,之后赴新加坡国立大学攻读博士。
博士期间,先后在微软亚洲研究院和谷歌公司美国总部工作,担任算法科学家。
2010-2015年于美国伊利诺伊大学香槟分校新加坡高等研究院担任研究科学家。
研究方向为计算机视觉、机器学习等。

本项研究已经由论文一作Peng Zhou(上海交通大学)上传至其GitHub主页,感兴趣的童鞋可以前去围观~
论文地址:
https://arxiv.org/abs/2110.09788
GitHub地址:
https://github.com/PeterouZh/CIPS-3D