微信终端自研 C++协程框架的设计与实现

作者:peterfan,腾讯 WXG 客户端开发工程师
背景
基于跨平台考虑,微信终端很多基础组件使用 C++ 编写,随着业务越来越复杂,传统异步编程模型已经无法满足业务需要。Modern C++ 虽然一直在改进,但一直没有统一编程模型,为了提升开发效率,改善代码质量,我们自研了一套 C++ 协程框架 owl,用于为所有基础组件提供统一的编程模型。
owl 协程框架目前主要应用于 C++ 跨平台微信客户端内核(Alita),Alita 的业务逻辑部分全部用协程实现,相比传统异步编程模型,至少减少了 50% 代码量。Alita 目前已经应用于儿童手表微信、Linux 车机微信、Android 车机微信等多个业务,其中 Linux 车机微信的所有 UI 逻辑也全部用协程实现。
为什么要造轮子?
那么问题来了,既然 C++20 已经支持了协程,业界也有不少开源方案(如 libco、libgo 等),为什么不直接使用?
原因:
owl 基础库需要支持尽量多的操作系统和架构,操作系统包括:Android、iOS、macOS、Windows、Linux、
RTOS;架构包括:x86、x86_64、arm、arm64、loongarch64,目前并没有任何一个方案能直接支持。owl 协程自 2019 年初就推出了,而当时 C++20 还未成熟,实际上到目前为止 C++20 普及程度依然不高,公司内部和外部合作伙伴的编译器版本普遍较低,导致目前 owl 最多只能用到 C++14 的特性
业界已有方案有不少缺点:
大多为后台开发设计,不适用终端开发场景
基本只支持 Linux 系统和 x86/x86_64 架构
封装层次较低,大多是玩具或 API 级别,并没有达到框架级别
在 C++ 终端开发没有看到大规模应用案例
Show me the code
那么协程比传统异步编程到底好在哪里?下面我们结合代码来展示一下协程的优势,同时也回顾一下异步编程模型的演化过程:
假设有一个异步方法 AsyncAddOne,用于将一个 int 值加 1,为了简单起见,这里直接开一个线程 sleep 100ms 后再回调新的值:
void AsyncAddOne(int value, std::function callback) {
std::thread t([value, callback = std::move(callback)] {
std::this_thread::sleep_for(100ms);
callback(value + 1);
});
t.detach();
} 要调用 AsyncAddOne 将一个 int 值加 3,有三种主流写法:
1、Callback
传统回调方式,代码写起来是这样:
AsyncAddOne(100, [] (int result) {
AsyncAddOne(result, [] (int result) {
AsyncAddOne(result, [] (int result) {
printf("result %d\n", result);
});
});
});回调有一些众所周知的痛点,如回调地狱、信任问题、错误处理困难、生命周期管理困难等,在此不再赘述。
2、Promise
Promise 解决了 Callback 的痛点,使用 owl::promise 库的代码写起来是这样:
// 将回调风格的 AsyncAddOne 转成 Promise 风格
owl::promise AsyncAddOnePromise(int value) {
return owl::make_promise([=] (auto d) {
AsyncAddOne(value, [=] (int result) {
d.resolve(result);
});
});
}
// Promise 方式
AsyncAddOnePromise(100)
.then([] (int result) {
return AsyncAddOnePromise(result);
})
.then([] (int result) {
return AsyncAddOnePromise(result);
})
.then([] (int result) {
printf("result %d\n", result);
});很显然,由于消除了回调地狱,代码漂亮多了。实际上 owl::promise 解决了 Callback 的所有痛点,通过使用模版元编程和类型擦除技术,甚至连语法都接近 JavaScript Promise。
但实践发现,Promise 只适合线性异步逻辑,复杂一点的异步逻辑用 Promise 写起来也很乱(如循环调用某个异步接口),因此我们废弃了 owl::promise,最终将方案转向了协程。
3、Coroutine
使用 owl 协程写起来是这样:
// 将回调风格的 AsyncAddOne 转成 Promise 风格
// 注:
// owl::promise 擦除了类型,owl::promise2 是类型安全版本
// owl 协程需要配合 owl::promise2 使用
owl::promise2 AsyncAddOnePromise2(int value) {
return owl::make_promise2([=] (auto d) {
AsyncAddOne(value, [=] (int result) {
d.resolve(result);
});
});
}
// Coroutine 方式
// 使用 co_launch 启动一个协程
// 在协程中即可使用 co_await 将异步调用转成同步方式
owl::co_launch([] {
auto value = 100;
for (auto i = 0; i < 3; i++) {
value = co_await AsyncAddOnePromise2(value);
}
printf("result %d\n", value);
}); 使用协程可以用同步方式写异步代码,大大减轻了异步编程的心智负担。co_await 语法糖让 owl 协程写起来跟很多语言内置的协程并无差别。
回调转协程
要在实际业务中使用协程,必须通过某种方式让回调代码转换为协程支持的形式。通过上面的例子可以看出,回调风格接口要支持在协程中同步调用非常简单,只需短短几行代码将回调接口先转成 Promise 接口,在协程中即可直接通过 co_await 调用:
// 回调接口
void AsyncAddOne(int value, std::function callback);
// Promise 接口
owl::promise2 AsyncAddOnePromise2(int value);
// 协程中调用
auto value = co_await AsyncAddOnePromise2(100); 实际项目中通常会省略掉上述中间步骤,直接一步到位:
// 在协程中可以像调用普通函数一样调用此函数
int AsyncAddOneCoroutine(int value) {
return co_await owl::make_promise2([=] (auto d) {
AsyncAddOne(value, [=] (int result) {
d.resolve(result);
});
});
} 后台开发使用协程,通常会 hook socket 相关的 I/O API,而终端开发很少需要在协程中使用底层 I/O 能力,通常已经封装好了高层次的异步 I/O 接口,因此 owl 协程并没有 hook I/O API,而是提供一种方便的将回调转协程的方式。
一个完整的例子
上述代码片段很难体现出协程的实际用法,这个例子使用协程实现了一个 tcp-echo-server,只有 40 多行代码:
int main(int argc, char* argv[]) {
// 使用 co_thread_scope() 创建一个协程作用域,并启动一个线程作为协程调度器
co_thread_scope() {
owl::tcp_server server;
int error = server.listen(3090);
if (error < 0) {
zerror("tcp server listen failed!");
return;
}
zinfo("tcp server listen OK, local %_", server.local_address());
while (true) {
auto client = server.accept();
if (!client) {
zerror("tcp server accept failed!");
break;
}
zinfo("accept OK, local %_, peer %_", client->local_address(), client->peer_address());
// 当有新 client 连接时,使用 co_launch 启动一个协程专门处理
owl::co_launch([client] {
char buf[1024] = { 0 };
while (true) {
auto num_recv = client->recv_some(buf, sizeof(buf), 0);
if (num_recv <= 0) {
break;
}
buf[num_recv] = '\0';
zinfo("[fd=%_] RECV %_ bytes: %_", client->fd(), num_recv, buf);
if (strcmp(buf, "exit") == 0) {
break;
}
auto num_send = client->send(buf, num_recv, 0);
if (num_send < 0) {
break;
}
zinfo("[fd=%_] SENT %_ bytes back", client->fd(), num_send);
}
});
}
};
return 0;
}框架分层

为了便于扩展和复用,owl 协程采用分层设计,开发者可以直接使用最上层的 API,也可以基于 Context API 或 Core API 搭建自己的协程框架。
协程设计
协程栈
协程按有无调用栈分为两类:
有栈协程(stackful):每个协程都有自己的调用栈,类似于线程的调用栈
无栈协程(stackless):协程没有调用栈,协程的状态通过状态机或闭包来实现
很显然,无栈协程比有栈协程占用更少的内存,但无栈协程通常需要手动管理状态,如果自研协程采用无栈方式会非常难用。因此语言级别的协程通常使用无栈协程,将复杂的状态管理交给编译器处理;自研方案通常使用有栈协程,owl 也不例外是有栈协程。
有栈协程按栈的管理方式又可以分为两类:
独立栈:每个协程都有独立的调用栈
共享栈:每个协程都有独立的状态栈,一个线程中的多个协程共享一个调用栈。由于这些协程中同时只会有一个协程处于活跃状态,当前活跃的协程可以临时使用调用栈。当此协程被挂起时,将调用栈中的状态保存到自身的状态栈;当协程恢复运行时,将状态栈再拷贝到调用栈。实践中通常设置较大的调用栈和较小的状态栈,来达到节省内存的目的。

共享栈本质上是一种时间换空间的做法,但共享栈有一个比较明显的缺点,看代码:
owl::co_launch("co1", [] {
char buf[1024] = { 0 };
auto job = owl::co_launch("co2", [&buf] {
// oops!!!
buf[0] = 'a';
});
job->join();
});上面的代码在共享栈模式下会出问题,协程 co1 在栈上分配的 buf,在协程 co2 访问的时候已经失效了。要规避共享栈的这个缺点,可能需要对协程的使用做一些限制或检查,无疑会加重使用者的负担。
对于终端开发,由于同时运行的协程数量并不多,性能问题并不明显,为了使用上的便捷性,owl 协程使用独立栈。
选择独立栈之后,协程栈应该如何分配又是另外的问题,有如下几种方案:
Split Stacks:简单来说是一个支持自动增长的非连续栈,由于只有 gcc 支持且有兼容性问题,实践中比较少用
malloc/mmap:直接使用 malloc 或 mmap 分配内存,业界主流方案
Thread Stack:在线程中预先分配一大段栈内存作为协程栈,业界比较少用
后两种方案通常还会采用内存池来优化性能,采用
mprotect来进行栈保护
owl 协程同时使用了后两种方案,那么什么场景下会使用到 Thread Stack 方案呢?因为 Android JNI 和部分 RTOS 系统调用 会检查 sp 寄存器是否在线程栈空间内,如果不在则认为栈被破坏,程序会直接挂掉。独立栈协程在执行时 sp 寄存器会被修改为指向协程栈,而通过 malloc/mmap 分配的协程栈空间不属于任何线程栈,一定无法通过 sp 检查。为了解决这个问题,我们在 Android 和部分 RTOS 上默认使用 Thread Stack。
协程调度
协程按控制传递机制分为两类:
对称协程(Symmetric Coroutine):和线程类似,协程之间是对等关系,多个协程之间可以任意跳转
非对称协程(Asymmetric Coroutine):协程之间存在调用和被调用关系,如协程 A 调用/恢复协程 B,协程 B 挂起/返回时只能回到协程 A
非对称协程与函数调用类似,比较容易理解,主流编程语言对协程的支持大都是非对称协程。从实现的角度,非对称协程的实现也比较简单,实际上我们很容易用非对称协程实现对称协程。owl 协程使用非对称协程。

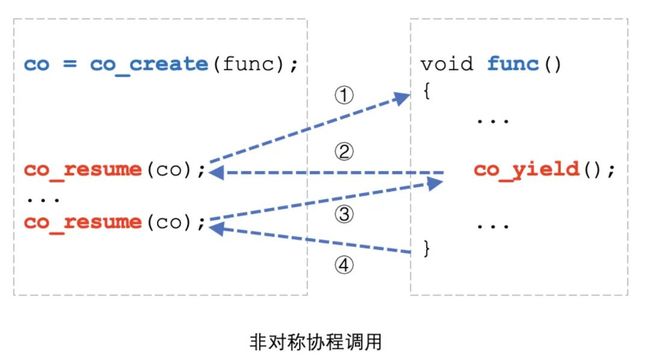
上图展示了非对称协程调用和函数调用的相似性,详细的时序如下:
调用者调用
co_create()创建协程,这一步会分配一个单独的协程栈,并为func设置好执行环境调用者调用
co_resume()启动协程,func函数开始运行协程运行到
co_yield(),协程挂起自己并返回到调用者调用者调用
co_resume()恢复协程,协程从co_yield()后续代码继续执行协程执行完毕,返回到调用者

如上图所示,有意思的是,如果一个协程没用调用 co_yield(),这个协程的调用流程其实跟函数一模一样,因此我们经常会说:函数就是协程的一种特例。
单线程调度器
协程和线程很像,不同的是线程多是抢占式调度,而协程多是协作式调度。多个线程之间共享资源时通常需要锁和信号量等同步原语,而协程可以不需要。
通过上面的示例可以看出,使用 co_create() 创建协程后,可以通过不断调用 co_resume() 来驱动协程的运行,而协程函数可以随时调用 co_yield() 来挂起自己并将控制权转移给调用者。
很显然,当协程数量较多时,通过手工调用 co_resume() 来驱动协程不太现实,因此需要实现协程调度器。
协程调度器分为两类:
1:N 调度(单线程调度):使用 1 个线程调度 N 个协程,由于多个协程都在同一个线程中运行,因此协程之间访问共享资源无需加锁
M:N 调度(多线程调度):使用 M 个线程调度 N 个协程,由于多个协程可能不在同一个线程运行,甚至同一个协程每次调度都有可能运行在不同线程,因此协程之间访问共享资源需要加锁,且协程中使用 TLS(Thread Local Storage) 会有问题

单线程调度通常使用 RunLoop 之类的消息循环来作为调度器,虽然调度性能低于多线程调度,但单线程调度器可以免加锁的特性,能极大降低编码复杂度,因此 owl 协程使用单线程调度。

使用 RunLoop 作为调度器的原理其实很简单,将所有 co_resume() 调用都 Post 到 RunLoop 中执行即可。原理如图所示,要想象一个协程是如何在 RunLoop 中执行的,大概可以认为是:协程函数中的代码被 co_yield() 分隔成多个部分,每一部分代码都被 Post 到 RunLoop 中执行。
使用 RunLoop 作为调度器除了协程不用加锁,还有一些额外的好处:
协程中的代码可以和
RunLoop中的传统异步代码和谐共处若使用 UI 框架的
RunLoop作为调度器,从协程中可以直接访问 UI
为了方便扩展,owl 协程将调度器抽象成一个单独的接口类,开发者可以很容易实现自己的调度器,或和项目已有的 RunLoop 机制结合:
class executor {
public:
virtual ~executor() {}
virtual uint64_t post(std::function closure) = 0;
virtual uint64_t post_delayed(unsigned delay, std::function closure) = 0;
virtual void cancel(uint64_t id) {}
}; 在 Linux 车机微信客户端,我们通过实现自定义调度器让协程运行在 UI 框架的消息循环中,得以方便地在协程中访问 UI。
协程间通信
通过使用单线程调度器,多个协程之间访问共享资源不再需要多线程的锁机制了。
那么用协程写代码是否就完全不需要加锁呢?看代码:
static int value = 0;
for (auto i = 0; i < 4; ++i) {
owl::co_launch([] {
value++;
owl::co_delay(1000);
value--;
printf("value %d\n", value);
});
}假设协程中要先将 value++,做完一些事情,再将 value--,我们期望最终 4 个协程的输出都是 0。但由于 owl::co_delay(1000) 这一行导致了协程调度,最终输出结果必然不符合预期。
一些协程库为了解决这种问题,提供了和多线程锁类似的协程锁机制。好不容易避免了线程锁,又要引入协程锁,难道没有更好的办法了吗?
实际上目前主流的并发模型除了共享内存模型,还有 Actor 模型与 CSP(Communicating Sequential Processes)模型,对比如下:

Do not communicate by sharing memory; instead, share memory by communicating. 不要通过共享内存来通信,而应该通过通信来共享内存
相信这句 Go 语言的哲学大家已经不陌生了,如何理解这句话?本质上看,多个线程或协程之间同步信息最终都是通过共享内存来进行的,因为无论是用哪种通信模型,最终都是从内存中获取数据,因此这句话我们可以理解为 尽量使用消息来通信,而不要直接共享内存。
Actor 模型和 CSP 模型采用的都是消息机制,区别在于 Actor 模型里协程与消息队列(mailbox)是绑定关系;而 CSP 模型里协程与消息队列(channel)是独立的。从耦合性的角度,CSP 模型比 Actor 模型更松耦合,因此 owl 协程使用 channel 作为协程间通信机制。
由于我们在实际业务开发中并没有遇到一定需要协程锁的场景,因此 owl 协程暂没有提供协程锁机制。
结构化并发
想象这样一个场景:我们写一个 UI 界面,在这个界面会启动若干协程通过网络去拉取和更新数据,当用户退出 UI 时,为了不泄露资源,我们希望协程以及协程发起的异步操作都能取消。当然,我们可以通过手动保存每一个协程的句柄,在 UI 退出时通知每一个协程退出,并等待所有协程都结束后再退出 UI。然而,手动进行上述操作非常繁琐,而且很难保证正确性。
不止是使用协程才会遇到上述问题,把协程换成线程,问题依然存在。传统并发主要有两类问题:
生命周期问题:如何保证协程引用的资源不被突然释放?
协程取消问题:1)如何打断正在挂起的协程?2)结束协程时,如何同时结束协程中创建的子协程?3)如何等待所有子协程都结束后再结束父协程?
这里的主要矛盾在于:协程是独立的,但业务是结构化的。
为了解决这个问题,owl 协程引入了结构化并发:
结构化并发的概念是:
作用域中的并发操作,必须在作用域退出前结束
作用域可以嵌套
作用域是一个抽象概念,有明确生命周期的实体都是作用域,如:
一个代码块
一个对象
一个 UI 页面

如上图所示,代码由上而下执行,在进入外部 scope 后,从 scope 中启动了两个协程,并进入了内部 scope,当执行流最终从外部 scope 出来时,结构化并发机制必须保证这两个协程已经结束。同样的,若内部 scope 中启动了协程,执行流从内部 scope 出来时,也必须保证其中的协程全部结束。
结构化并发在 owl 协程的实现其实并不复杂,本质上是一个树形结构:

核心理念是:
协程也是一个作用域
协程有父子关系
父协程取消,子协程也自动取消
父协程结束前,必须等待子协程结束
光说概念有点抽象,最后来看一个 owl 协程结构化并发的例子:
class SimpleActivity {
public:
SimpleActivity() {
// 为 scope_ 设置调度器,后续通过 scope_ 启动的协程
// 默认使用 UI 的消息循环作为调度器
scope_.set_exec(GetUiExecutor());
}
~SimpleActivity() {
// UI 销毁的时候取消所有子协程
scope_.cancel();
// scope_ 析构时会等待所有子协程结束
}
void OnButtonClicked() {
// 在 UI 事件中通过 scope_ 启动协程
scope_.co_launch([=] {
// 启动子协程下载图片
auto p1 = owl::co_async([] { return DownloadImage(...); });
auto p2 = owl::co_async([] { return DownloadImage(...); });
// 等待图片下载完毕
auto image1 = co_await p1;
auto image2 = co_await p2;
// 合并图片
auto new_image = co_await AsyncCombineImage(image1, image2);
// 更新图片,由于协程运行在消息循环中,可以直接访问 UI
image_->SetImage(new_image);
});
// 可以通过 scope_ 启动任意多个协程
scope_.co_launch([=] {
...
});
}
private:
owl::co_scope scope_;
ImageLabel* image_;
};性能测试

说明:
上下文切换:使用 Context API 进行上下文切换的性能,耗时在
20~30ns级别协程切换:使用单线程调度器进行协程切换的性能,耗时在
0.5~3us级别线程切换:pthread 线程切换的性能,耗时在
2~8us级别
owl 协程受限于单线程调度器性能,切换速度和上下文切换比并不算快,但在终端使用也足够了。
总结
总的来说,自 owl 协程在实际项目中应用以来,开发效率和代码质量都有很大提升。owl 协程虽然已经得到广泛应用,但还存在很多不完善的地方,未来会继续迭代打磨。owl 现阶段在腾讯内部开源,待框架更完善且 API 稳定后,再进行对外开源。
最近热文
业界首创,腾讯网络平台部实现大规模光网络实时管控系统TOOP
腾讯程序员不寻常的三年