【NLP实践】使用pytorch进行文本分类——ADGCNN
前言
在文本分类任务中常用的网络是RNN系列或Transformer的Encoder,很久没有看到CNN网络的身影(很久之前有TextCNN网络)。本文尝试使用CNN网络搭建一个文本分类器,命名为:ADGCNN。
ADGRCNN网络有以下元素构成:
- A:Self-Attention(自注意力);
- D:Dilated Convolution(空洞卷积);
- G:Gated Linear Units(门控线性单元);
- R:ResNets(残差网络);
Dilated Convolution
Dilated Convolution又称膨胀卷积,可以在不增加参数、不减少计算速度的情况下,扩大卷积核的探测范围。
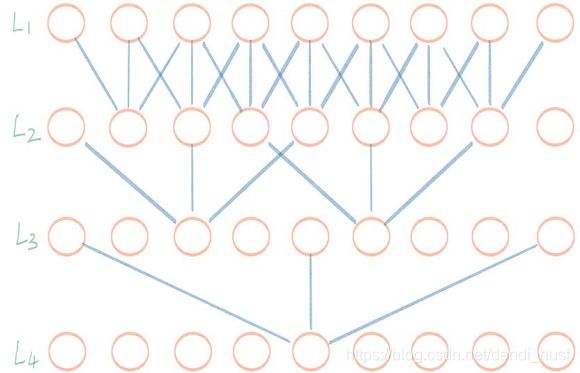
如上图所示,kernel_size=3,dilate_rate=[1, 2, 4],卷积效果如下:
dilate_rate=1时,一个卷积核可以检测长度为3的序列范围;dilate_rate=2时,一个卷积核可以检测长度为5的序列范围;dilate_rate=4时,一个卷积核可以检测长度为9的序列范围;
GLU
GLU是Gated Linear Units(门控线性单元)的简称,出自论文《Convolutional Sequence to Sequence Learning》,其结构如下图所示:
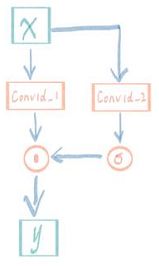
表达式为:
y = C o n v 1 d 1 ( x ) ⋅ s i g m o i d ( C o n v 1 d 2 ( x ) ) y = Conv1d_1(x) \cdot sigmoid(Conv1d_2(x)) y=Conv1d1(x)⋅sigmoid(Conv1d2(x))
Conv1d_1 和 conv1d_2是两个形式一样,但权值不同的两个卷积核。其中一个在卷积计算之后使用sigmoid进行激活,另一个不进行激活只进行卷积计算,然后将这两个计算结果进行点乘计算,得到结果。
- 直观来看,输入
x经过Conv1d_1之后不再进行激活,相当于线性计算,在BP过程中几乎不会出现梯度消失现象; - 此外,
Conv1d_2经过sigmoid函数进行激活,输出的值域为:(0, 1),相当于为Conv1d_1的输出加上一个开关(可以控制哪些信息可以通过,哪些信息不可以通过);
GLU+残差结构

网络结构
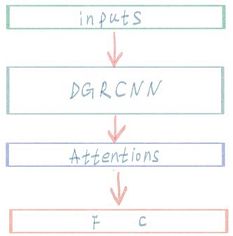
模型细节
1.input:在本任务中除了把字向量作为输入特征外,还加入了拼音向量;又因为CNN网络对位置信息不敏感,又将位置向量作为特征输入进网络;

2. mask:因为存在pad,所以需要mask,关于mask的作用,可以参见这里;
3. fine-tune:在实践中,使用学习率lr=0.001进行训练,在训练集的准确率为:99.14%,验证集准确率为:97.78%。然后调整学习率为lr=0.0001对该模型进行fine-tune,最终模型在训练集准确率为:99.41%,验证集准确率为:99.57%。fine-tune效果明显。
网络代码
def get_masks(src, trg=None, pad_idx=1):
'''
获得 mask
:param src: [batch_size, src_seq_length]
:param trg: [batch_size, trg_seq_length]
:return:
'''
# src_mask shape [batch_size, 1, 1, src_seq_length]
# src_mask = (src != pad_idx).unsqueeze(1).unsqueeze(2)
src_mask = (src != pad_idx)
if trg is not None:
# trg_pad_mask shape [batch_size, 1, trg_seq_length, 1]
trg_pad_mask = (trg != pad_idx).unsqueeze(1).unsqueeze(3)
trg_len = trg.shape[1]
# trg_sub_mask shape [trg_seq_length, trg_seq_length]
trg_sub_mask = torch.tril(torch.ones((trg_len, trg_len))).bool()
# trg_mask shape [batch_size, 1, trg_seq_length, trg_seq_length]
trg_mask = trg_pad_mask & trg_sub_mask
return src_mask, trg_mask
else:
return src_mask
def get_position(x, max_length=1024):
batch_size = x.shape[0]
seq_length = x.shape[1]
# pos_id = torch.range(0, seq_length - 1)
pos_id = torch.from_numpy(np.array([item if item < max_length else max_length - 1 for item in range(0, seq_length)]))
pos_id = pos_id.unsqueeze(0).repeat(batch_size, 1)
return pos_id.long()
class DGCNNLayer(nn.Module):
def __init__(self, in_channels, out_channels, k_size=3, dilation_rate=1, dropout=0.1):
super(DGCNNLayer, self).__init__()
self.k_size = k_size
self.dilation_rate = dilation_rate
self.hid_dim = out_channels
self.pad_size = int(self.dilation_rate * (self.k_size - 1) / 2)
self.dropout_layer = nn.Dropout(dropout)
# self.liner_layer = nn.Linear(int(out_channels / 2), out_channels)
self.glu_layer = nn.GLU()
self.conv_layer = nn.Conv1d(in_channels, out_channels * 2, kernel_size=k_size, dilation=dilation_rate,
padding=(self.pad_size,))
self.layer_normal = nn.LayerNorm(in_channels)
def forward(self, x, mask):
'''
:param x: shape: [batch_size, seq_length, channels(embeddings)]
:return:
'''
x_r = x
x = x.permute(0, 2, 1)
x = self.conv_layer(x)
x = x.permute(0, 2, 1)
x = self.glu_layer(x)
x = self.dropout_layer(x)
# x = self.liner_layer(x)
# x = self.dropout_layer(x)
mask = mask.unsqueeze(2).repeat(1, 1, self.hid_dim).float()
x = x * mask
return self.layer_normal(x + x_r)
class SelfAttentionLayer(nn.Module):
def __init__(self, hid_dim, n_heads, dropout, device):
super(SelfAttentionLayer, self).__init__()
self.hid_dim = hid_dim
self.n_heads = n_heads
assert self.hid_dim % n_heads == 0
self.w_q = nn.Linear(hid_dim, hid_dim)
self.w_k = nn.Linear(hid_dim, hid_dim)
self.w_v = nn.Linear(hid_dim, hid_dim)
self.fc = nn.Linear(hid_dim, hid_dim)
self.dropout = nn.Dropout(dropout)
self.scale = torch.sqrt(torch.FloatTensor([hid_dim // n_heads])).to(device)
def forward(self, q, k, v, mask=None):
'''
:param q: shape [batch_size, seq_length, hid_dim]
:param k: shape [batch_size, seq_length, hid_dim]
:param v: shape [batch_size, seq_length, hid_dim]
:param mask:
:return:
'''
batch_size = q.shape[0]
Q = self.w_q(q)
K = self.w_k(k)
V = self.w_v(v)
# Q,K,V shape [batch_size, n_heads, seq_length, hid_dim // n_heads]
Q = Q.contiguous().view(batch_size, -1, self.n_heads, self.hid_dim // self.n_heads).permute(0, 2, 1, 3)
K = K.contiguous().view(batch_size, -1, self.n_heads, self.hid_dim // self.n_heads).permute(0, 2, 1, 3)
V = V.contiguous().view(batch_size, -1, self.n_heads, self.hid_dim // self.n_heads).permute(0, 2, 1, 3)
# energy [batch_size, n_heads, seq_length, seq_length]
energy = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale
if mask is not None:
energy = energy.masked_fill(mask == 0, -1e10)
# attention [batch_size, n_heads, seq_length, seq_length]
attention = self.dropout(torch.softmax(energy, dim=-1))
# x [batch_size, n_heads, seq_length, hid_dim // n_heads]
x = torch.matmul(attention, V)
x = x.contiguous().permute(0, 2, 1, 3)
# x [batch_size, seq_length, hid_dim]
x = x.contiguous().view(batch_size, -1, self.n_heads * (self.hid_dim // self.n_heads))
x = self.fc(x)
if mask is not None:
mask = mask.squeeze(1).squeeze(1)
mask = mask.unsqueeze(2).repeat(1, 1, self.hid_dim).float()
x = x * mask
# [batch_size, seq_length, hid_dim]
return x
class TextDGCNN(nn.Module):
def __init__(self,
config: DGCNNConfig,
char_size=7000,
pinyin_size=7000,
max_length=1024,
device=None):
super(TextDGCNN, self).__init__()
self.hid_dim = config.embedding_size
# 字embedding
self.char_embedding = nn.Embedding(char_size, int(config.embedding_size / 2))
# 拼音embedding
self.pinyin_embedding = nn.Embedding(pinyin_size, int(config.embedding_size / 2))
# 位置embedding
self.position_embedding = nn.Embedding(max_length, int(config.embedding_size / 2))
# 位置embedding初始化:均匀分布
nn.init.uniform_(self.position_embedding.weight)
# 膨胀卷积列表
self.dgcnn_list = nn.ModuleList([
DGCNNLayer(config.embedding_size, config.embedding_size,
k_size=item[0], dilation_rate=item[1], dropout=config.keep_dropout)
for item in config.cnn_conf_list
])
# 自注意力层
self.atten_layer = SelfAttentionLayer(config.embedding_size, config.n_heads, config.keep_dropout, device)
# 全连接层
self.fc_layer = nn.Sequential(
nn.Linear(config.embedding_size, config.embedding_size // 2),
nn.ReLU(),
nn.Dropout(config.keep_dropout),
nn.Linear(config.embedding_size // 2, config.num_classes)
)
self.ext_conv = nn.Conv1d(self.hid_dim, self.hid_dim, stride=2, kernel_size=2)
self.ext_maxpool = nn.MaxPool1d(2, 2)
def ext_conv_block(self, x):
'''
:param x: shape [batch_size, seq_length, hid_dim]
:return: [batch_size, 1, hid_dim]
'''
x = x.permute(0, 2, 1)
x_r = self.ext_maxpool(x)
x = self.ext_conv(x)
x = F.relu(x)
x = x + x_r
x = x.permute(0, 2, 1)
return x
def forward(self, char_input, pinyin_input, char_pos, pinyin_pos, char_mask, pinyin_mask):
#
char_input = self.char_embedding(char_input)
char_pos = self.position_embedding(char_pos)
#
pinyin_input = self.pinyin_embedding(pinyin_input)
pinyin_pos = self.position_embedding(pinyin_pos)
#
char_input = torch.cat([char_input, char_pos], dim=2)
pinyin_input = torch.cat([pinyin_input, pinyin_pos], dim=2)
# inputs shape: [batch_size, seq_length, embeddings]
inputs = torch.cat([char_input, pinyin_input], dim=1)
# inputs_mask shape:[batch_size, seq_length]
inputs_mask = torch.cat([char_mask, pinyin_mask], dim=-1)
# inputs = self.atten_layer(inputs, inputs, inputs, inputs_mask)
dgcnn_output = inputs
for dgcnn in self.dgcnn_list:
dgcnn_output = dgcnn(inputs, inputs_mask)
atten_mask = inputs_mask.unsqueeze(1).unsqueeze(2)
# shape : []
attn_output = self.atten_layer(dgcnn_output, dgcnn_output, dgcnn_output, atten_mask)
fc_output = self.fc_layer(attn_output)
fc_output = torch.mean(fc_output, dim=1)
return fc_output
核心参数
class DGCNNConfig(object):
'''CNN参数配置'''
# fine_tune
fine_tune = True
num_classes = 2
# 学习率
learning_rate = 0.001
fine_tune_lr = learning_rate * 0.1
# 是否使用GPU
cuda = True
# drop out
keep_dropout = 0.1
# 字向量长度
embedding_size = 256
# 多头
n_heads = 4
# 卷积核大小
# kernel_size, dilation
cnn_conf_list = [ (3, 1), (3, 2), (3, 4), (3, 1)]
# 批次数量
batch_size = 16
# 迭代次数
epoches = 500
# l2正则
l2_reg_lambda = 0.0001
实践
经笔者的实践,在分类任务中该网络并不比BILSTM+ATTENTION(链接)网络效果差。