Pytorch实战__CNN做图像分类
0. 介绍
首先需要指出的是,代码是从李宏毅老师的课程中下载的,并不是我自己码的。这篇文章主要是在原代码中加了一些注释和讲解,以及将繁体字改成了简体字。
我们要解决的问题是一个食物图片分类的问题。如下图中,我们要将荷包蛋和肉分开。

总得来说,食物的种类一共有11类,分别是:Bread、Dairy product、Dessert、Egg、Fried food、Meat、Noodles/Pasta、Rice、Seafood、Soup、Vegetable/Fruit。训练集中有9866张图片,验证集中有3430张图片,测试集中有3347张图片。
所有的代码是在Colab上运行的。
1. 下载数据
下载数据集的命令是两段Linux命令,其中第一步是从指定的地址下载food-11.zip这个压缩包,第二步是将这个压缩包解压。
!gdown --id '19CzXudqN58R3D-1G8KeFWk8UDQwlb8is' --output food-11.zip # 下载数据集
!unzip food-11.zip # 解压
2. 导入包
import os
import numpy as np
import cv2
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import pandas as pd
from torch.utils.data import DataLoader, Dataset
import time
3. 读取数据
3.1 编写读取数据的函数
因为我们要读取的并不是简单的数字,而是图片以及它们的标签,因此需要我们自己编写读取数据的函数
def readfile(path, label):
# label 是一个bool值,代表是否需要返回便签(因为读取测试集的时候是没有标签的)
image_dir = sorted(os.listdir(path)) #os.listdir函数是将path下的所有文件名列成一个dir,方便后续用for循环读取数据
x = np.zeros((len(image_dir), 128, 128, 3), dtype=np.uint8)
y = np.zeros((len(image_dir)), dtype=np.uint8)
for i, file in enumerate(image_dir):
img = cv2.imread(os.path.join(path, file))#path和file合并以后就是图片的完整地址
x[i, :, :] = cv2.resize(img,(128, 128))#resize是将图片的尺寸进行修改,以方便放入x中
if label:
y[i] = int(file.split("_")[0]) #图片的存储格式形如“food-11/validation/7_20.jpg”其中前面的7是图片的类型,故我们通过split来取label
if label:
return x, y
else:
return x
分別将 training set、validation set、testing set 用 readfile 函数读取进来
workspace_dir = './food-11'#因为我们在colab上用第一第二行命令下载的数据会存在当前目录下,所以地址要这样写
print("Reading data")
train_x, train_y = readfile(os.path.join(workspace_dir, "training"), True)
print("Size of training data = {}".format(len(train_x)))
val_x, val_y = readfile(os.path.join(workspace_dir, "validation"), True)
print("Size of validation data = {}".format(len(val_x)))
test_x = readfile(os.path.join(workspace_dir, "testing"), False)
print("Size of Testing data = {}".format(len(test_x)))
4.创造Dataset类
-
在 Pytorch 中,我们可以使用 torch.utils.data 的 Dataset 及 DataLoader 来"包装" data,使后续的 training 及 testing 更为方便。这里我们选择自己写一个Dataset类,而不是使用torch.utils.data 的 Dataset函数
-
Dataset 需要 overload 两个函数:len 及 getitem
-
len 必须要返回 dataset 的大小,而 getitem 则定义了使用index取值时,dataset 应该返回什么数据
#training 时候做的data augmentation
train_transform = transforms.Compose([
transforms.ToPILImage(),#将数据转为PILImage格式
#这两个旋转操作是为了增强模型的泛化能力。简单地说,我们要让我们的模型避免“横看成岭侧成峰”的情况,对于
#同样的食物,不能因为拍摄角度不一样就识别不出来了
transforms.RandomHorizontalFlip(), #随机将图片数据反转
transforms.RandomRotation(15), #随机选择图片数据
transforms.ToTensor(), #将图片转为tensor
])
#testing 时不做 data augmentation
test_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor(),
])
class ImgDataset(Dataset):
def __init__(self, x, y=None, transform=None):
self.x = x #定义x
# label is required to be a LongTensor(这一点需要注意!!)
self.y = y #定义y
if y is not None:
self.y = torch.LongTensor(y)
self.transform = transform #定义transform
def __len__(self):
return len(self.x)
def __getitem__(self, index):
X = self.x[index] #读取x
if self.transform is not None:
X = self.transform(X) #如果输入参数要求我们做transform,则在此步做transform
if self.y is not None:
Y = self.y[index] #如果输入参数要求我们返回图片的label,则在此步返回
return X, Y
else:
return X
实例化Dataset类
batch_size = 128 #每次训练的数据个数为128
train_set = ImgDataset(train_x, train_y, train_transform)
val_set = ImgDataset(val_x, val_y, test_transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True) #shuffle=True使得读入数据的时候打乱原有的顺序
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False)
5. 编写CNN模型
网络模型较为简单,开始的每个卷积块都是由一个卷积层,一个标准化层,一个激活函数和一个池化层组成的(各个层的参数已经在注释中给出,同时,每一层输入输出的图片的size也给出了)。之后,就是一个全连接层。最终的输出是11维向量(因为我们要分类的食品一共11种)。
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
#torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
#torch.nn.MaxPool2d(kernel_size, stride, padding)
#input 维度 [3, 128, 128]
self.cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), # [64, 128, 128] (padding=1,所以图片大小没有变)
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [64, 64, 64] (padding=0,所以经过一个size为2,stride为2的池化层,大小降为原来的一半)
nn.Conv2d(64, 128, 3, 1, 1), # [128, 64, 64]
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [128, 32, 32]
nn.Conv2d(128, 256, 3, 1, 1), # [256, 32, 32]
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [256, 16, 16]
nn.Conv2d(256, 512, 3, 1, 1), # [512, 16, 16]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 8, 8]
nn.Conv2d(512, 512, 3, 1, 1), # [512, 8, 8]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 4, 4]
)
self.fc = nn.Sequential(
nn.Linear(512*4*4, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 11)
)
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1)
return self.fc(out)
6.训练
使用训练集训练model,并使用验证集查看训练的好坏。我们通过这种方式来寻找最优的参数(主要是训练的轮数epoch)。从最终的输出结果可以看出,epoc选取29的时候模型在验证集上表现最好。
model = Classifier().cuda() #.cuda使得我们的模型使用GPU训练
loss = nn.CrossEntropyLoss() # 因为是 classification task,所以 loss 使用 CrossEntropyLoss(交叉熵损失)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # optimizer 使用 Adam
num_epoch = 40
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
model.train() # 确保 model 是在 train model
for i, data in enumerate(train_loader): #从dataloader里面一步步取数据
optimizer.zero_grad() # 用 optimizer 将 model 参数的 gradient 清零,防止上一步训练出来的gradient影响这一步的训练
train_pred = model(data[0].cuda()) # 利用 model 得到预测的概率分步 这样实际上是在使用 model 的 forward 函数
batch_loss = loss(train_pred, data[1].cuda()) # 计算 loss (注意 prediction 取 label 必须同时在 CPU 或是 GPU 上)
batch_loss.backward() # 利用 back propagation 算出每个参数的 gradient
optimizer.step() # step表示前进,即optimizer 用 gradient 更新参数数值
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item()
model.eval() #确保 model 是在 val model
with torch.no_grad(): #在验证集上不涉及使用back propagation训练参数,所以要用这个命令,防止模型训练好的参数被改变
for i, data in enumerate(val_loader):
val_pred = model(data[0].cuda())
batch_loss = loss(val_pred, data[1].cuda())
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == data[1].numpy())#哪个类别概率最大,就识别哪个类别
val_loss += batch_loss.item()
#将结果 print 出來
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f | Val Acc: %3.6f loss: %3.6f' % \
(epoch + 1, num_epoch, time.time()-epoch_start_time, \
train_acc/train_set.__len__(), train_loss/train_set.__len__(), val_acc/val_set.__len__(), val_loss/val_set.__len__()))
我们在这里展示一下部分的训练结果,可以看到epoch为29 的时候,模型在验证集上表现的最好。
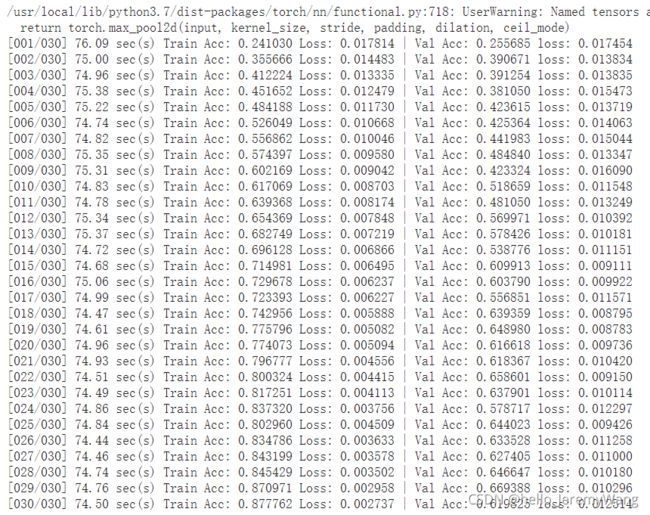
得到好的参数后,我们使用使用training set和validation set共同训练(数据越多,模型效果越好)
train_val_x = np.concatenate((train_x, val_x), axis=0)#np.concatenate函数是用来合并np.array的函数
train_val_y = np.concatenate((train_y, val_y), axis=0)
train_val_set = ImgDataset(train_val_x, train_val_y, train_transform)
train_val_loader = DataLoader(train_val_set, batch_size=batch_size, shuffle=True)
训练一下,代码和上次训练的时候一模一样
model_best = Classifier().cuda()
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model_best.parameters(), lr=0.001)
num_epoch = 29
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
model_best.train()
for i, data in enumerate(train_val_loader):
optimizer.zero_grad()
train_pred = model_best(data[0].cuda())
batch_loss = loss(train_pred, data[1].cuda())
batch_loss.backward()
optimizer.step()
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item()
#將結果 print 出來
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f' % \
(epoch + 1, num_epoch, time.time()-epoch_start_time, \
train_acc/train_val_set.__len__(), train_loss/train_val_set.__len__()))
7. 进行预测
利用刚刚训练好的模型进行预测
#首先将数据做出Dataset,并用Dataloader
test_set = ImgDataset(test_x, transform=test_transform)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)
model_best.eval() #使用刚刚训练好的model_best来进行预测
prediction = []
with torch.no_grad():
for i, data in enumerate(test_loader):
test_pred = model_best(data.cuda())
test_label = np.argmax(test_pred.cpu().data.numpy(), axis=1)#哪个类别概率最大,就识别哪个类别
for y in test_label:
prediction.append(y)
#将结果写入csv
with open("predict.csv", 'w') as f:
f.write('Id,Category\n')
for i, y in enumerate(prediction):
f.write('{},{}\n'.format(i, y))