Python Scrapy爬取华为应用市场APK信息
Python Scrapy是功能十分强大的爬虫框架,使用起来非常方便,下面讲解下爬取华为应用市场APK的过程。
(1)安装
Scrapy是第三方爬虫框架,需要先安装,我window上安装的是Python2.7,框架安装比较简单。依次执行下面的命令就可以安装成功。
pip install scrapy
pip install pywin32
如果电脑上安装的是Python3的版本,Scrapy框架安装麻烦点,请参照这篇文章进行安装,
http://blog.csdn.net/liuweiyuxiang/article/details/68929999
总之就是安装过程中缺少什么库,就去这个网址下载对应的.whl文件,然后执行pip install xxx.whl文件就可以了
http://www.lfd.uci.edu/~gohlke/pythonlibs/
(2)创建项目
创建项目命令为 : scrapy startproject 项目名

创建之后,使用JetBrains PyCharm工具打开项目,项目目录结构如下
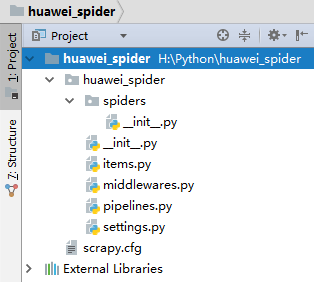
文件说明:
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
(3)编写爬虫
在spiders目录,新建huawei_spider.py文件。
items.py文件
- 在items.py文件,定义HuaweiSpiderItem对象,分别保存每个APK的名字、描述信息和当前页面的url。
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class HuaweiSpiderItem(scrapy.Item):
# define the fields for your item here like:
appName = scrapy.Field()
appDesc = scrapy.Field()
url = scrapy.Field()
passhuawei_spider.py文件:
- 由于需要爬取华为应用市场全站的内容,所以继承CrawlSpider类
- name必须定义,该爬虫名字
- allowed_domains定义允许爬取的域名
- start_urls定义开始爬取的站点,可以写多个
- rules定义爬取的规则
from scrapy.spiders.crawl import Rule, CrawlSpider
from scrapy.linkextractors import LinkExtractor
from huawei_spider.items import HuaweiSpiderItem
class AppStoreSpider(CrawlSpider):
name = 'huawei'
allowed_domains = ["app.hicloud.com"]
start_urls =['http://app.hicloud.com/']
rules = [
Rule(LinkExtractor(allow='app/C\d+'),callback='parse_items')
]
def parse_items(self,response):
item = HuaweiSpiderItem()
item['appName'] = response.xpath("//p/span[@class='title']/text()").extract()
item['appDesc'] = response.xpath("//div[@id='app_strdesc']/text()").extract()
item['url'] = response.url
yield item
对于代码中Rule规则如何定义和xpath规则如何提取,请参照官方文档。
https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
pipelines.py文件
该文件对爬取的数据进行处理,保存到huawei.json文件中
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class HuaweiSpiderPipeline(object):
def process_item(self, item, spider):
return item
def __init__(self):
self.filename = open("huawei.json", "w")
def process_item(self, item, spider):
text = json.dumps(dict(item), ensure_ascii = False) + ",\n"
self.filename.write(text.encode("utf-8"))
return item
def close_spider(self, spider):
self.filename.close()
setting.py文件
这个文件是全局的配置文件,我修改了两个地方
- 由于爬取华为应用市场,需要爬虫请求报文头带入浏览器信息,因此DEFAULT_REQUEST_HEADERS中添加如下信息,要不然会报python scrapy 报错 DEBUG: Ignoring response 403错误

- 配置管道

该类的完整代码如下:
# -*- coding: utf-8 -*-
# Scrapy settings for huawei_spider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'huawei_spider'
SPIDER_MODULES = ['huawei_spider.spiders']
NEWSPIDER_MODULE = 'huawei_spider.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'huawei_spider (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;",
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'huawei_spider.middlewares.HuaweiSpiderSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'huawei_spider.middlewares.HuaweiSpiderDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'huawei_spider.pipelines.HuaweiSpiderPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'