擦除:提升 CNN 特征可视化的 3 种重要手段
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达作者丨皮特潘
导读
所谓擦除,就是去除掉一部分有用的信息,以提高网络提取特征的能力。本文对3种提升特征可视化的方法进行了详细综述,包括直接擦除、利用预测信息(CAM)擦除以及Dropout方法。
前言
在CNN的测试阶段,我们一般会用CAM(Class Activation Mapping)来判断网络训练的好不好,到底可不可信赖。CAM被认为是表示网络真正看到哪里,也是指示最具有判别的特征以及依据。但是在实际应用的过程中,我们发现现实并不是那么美好。因为我们采用的loss梯度下降方法更新网络,是直接对loss进行负责的,并非CAM。侧面反映了网络看到的不是exactly我们想要的。因此我们就会自然想到,能否采用某些手段,去提升CAM的质量?CAM质量提升了,当然网络提取特征的能力也会提升,泛化能力自然也不是问题。因此本文就是研究其中的一种手段——擦除。最重要的还是提供一种思路。
CAM
关于CAM,可以参考这篇文章,它详细介绍了CAM的来龙去脉,以及最新的研究成果。
皮特潘:万字长文:特征可视化技术(CAM)

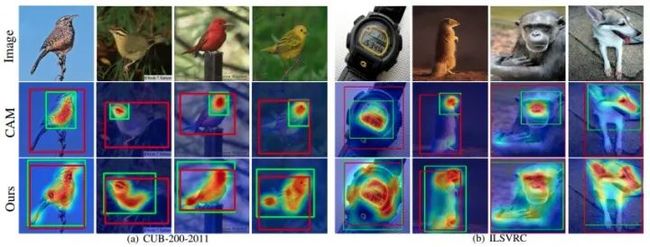
首先看一下CAM存在的问题:
对于前景类别,CAM通常只能cover最具有判别的部分,导致一些重要的区域漏掉;
对于背景,CAM经常cover错掉,或者说解释性没那么强;
cover的边缘不够精确,当然这是由于可视化的特征图远小于原图大小,分类网络一般为32倍下采样,进行插值到原图大小,边缘肯定不清晰;
有时CAM并不能cover到我们真正想要的特征。例如:当我们对"船"进行分类,CAM会cover到"水面";因为“水面”通常都是伴随“船”存在的。
擦除方法
所谓擦除,就是去除掉一部分有用的、具有判别的信息,希望网络依靠剩余信息也可以进行精准预测,这样就自然提高了网络提取更全面特征的能力,对应的CAM会更加精准。
简单划分,擦除⼀般包括两种⽅式:
对原始图片擦除
对特征图进行擦除
再细分一点:
直接在原图上擦除,通常按照一定规则随机进行,常用于数据增强。
利用网络预测的信息进行擦除,类似一种注意力机制反着使用。比如网络输入为原始图片,训练当中利用实时的CAM擦除,再进行loss计算。这种训练-擦除-再训练-再擦除的方式通常被称为对抗擦除。再比如,直接利用CAM作为mask作用到特征图上,等等。
类dropout的策略,按照一定规则在特征图上进行随机擦除,通常不会利用网络预测信息,是一种正则化的手段。
本文涉及的论文
直接擦除:Hide-and-Seek、 Random Erasing、 Cutout、 Grid Mask
利用预测信息(CAM)擦除:AE-PSL 、ACoL 、SPG 、GAIN、seeNet、ADL
Dropout方法:DropBlock、FickleNet(https://www.researchgate.net/publication/331397104_FickleNet_Weakly_and_Semi-supervised_Semantic_Image_Segmentationusing_Stochastic_Inference)
直接擦除
Hide-and-Seek :Hide-and-Seek: A Data Augmentation Technique for Weakly-Supervised Localization and Beyond(https://openaccess.thecvf.com/content_ICCV_2017/papers/Singh_Hide-And-Seek_Forcing_a_ICCV_2017_paper.pdf)
Random Erasing:Random erasing data augmentation(https://arxiv.org/pdf/1708.04896v2.pdf)
Cutout: Improved Regularization of Convolutional Neural Networks with Cutout(https://arxiv.org/abs/1708.04552v2)
Grid Mask: Grid Mask Data Augmentation(https://arxiv.org/abs/2001.04086v2)
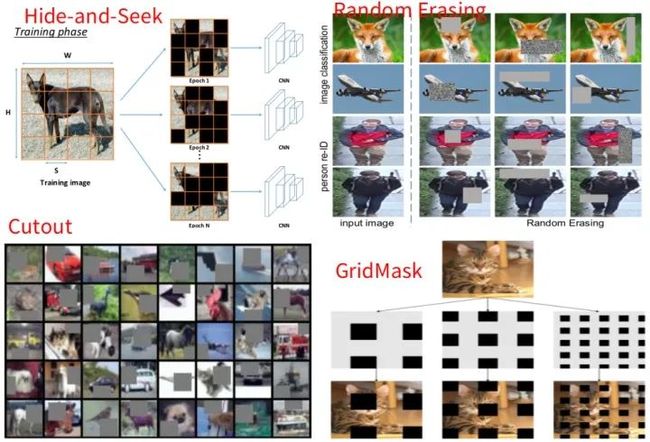
核心解读:这四种做法本质上是一样的,也比较简单,所以放到一起说。不过实现的方式有一些差别,看图就⼀眼明⽩了! 核⼼思想都是去掉⼀些区域,使得CNN只⽤其他区域也可以识别出物体,这样CNN可以使⽤图像的全局信息⽽不是仅由⼀些⼩特征组成的局部信息来识别物体。另外,通过模拟遮挡,可以提⾼模型的性能和泛化能⼒。关于填充什么颜色,也有一定的讲究。暴力填黑会影响数据的分布,例如BN的参数方面,效果可能不好。因此可以选择填充数据集的均值。当然也可以填充随机噪声。此类方法可以作为如random crop、flip等通用数据增强方法的一个补充,适用于任何CNN任务当中。个⼈看法:
hide操作肯定不能把整个前景全都隐藏起来,隐藏⽹格的⼤⼩或密度是⼀个超参。
完全随机,没有任何⾼层信息指导的⽅式是低效,⽽且不能保证⽹络总能发现新对象区域。
⼩⽬标检测要慎⽤,或者说要提前设计好,不能把整个目标都擦数掉。这样会有引入一些噪声的风险。
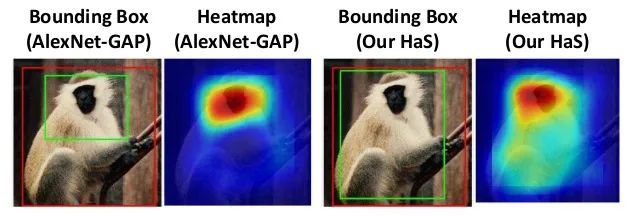
正如Hide-and-Seek 中实验效果,该方法是可以提升CAM质量和网络性能的。如下:
AE-PSL
文章标题:Object Region Mining with Adversarial Erasing: A Simple Classifification to Semantic Segmentation Approach(https://arxiv.org/pdf/1703.08448.pdf)
一作解读:颜水成和冯佳时团队一作详解CVPR录用论文:基于对抗擦除的物体区域挖掘
https://www.leiphone.com/news/201709/pL7GwHcZmw9VylcZ.html
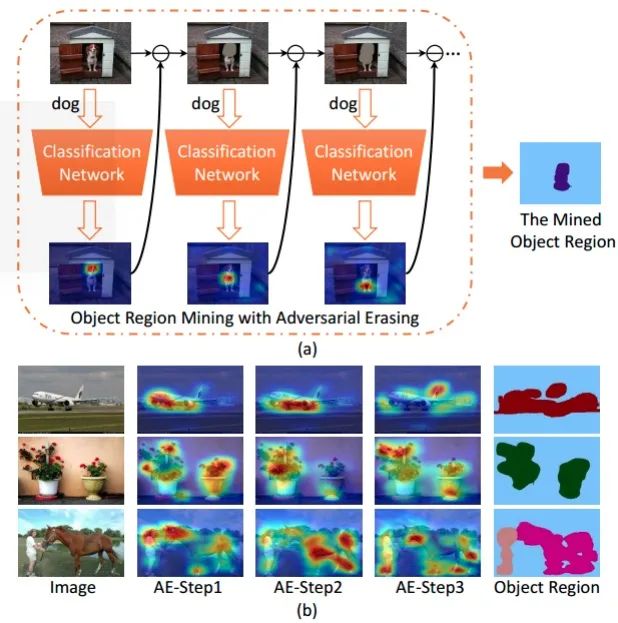
核心解读:
⾸先利⽤原始图像训练⼀个分类⽹络,并利⽤⾃上⽽下的attention⽅法(CAM)来定位图像中最具判别⼒的物体区域。然后,将挖掘出的区域从原始图⽚中擦除,并将擦除后的图像继续训练另⼀个分类⽹络来定位其它的物体区域。重复此过程,直到⽹络在被擦除的训练图像上不能很好地收敛。最后将被擦除的区域合并起来作为挖掘出的物体区域。
基于VGG16训练图像的分类⽹络,将最后两个全连接层替换为卷积层,CAM被⽤来定位标签相关区域。在⽣成的location map(H)中,属于前20%最⼤值的像素点被擦除。具体的擦除⽅式是将对应的像素点的值设置为所有训练集图⽚的像素的平均值。作者发现在实施第四次擦除后,⽹络训练收敛后的 loss值会有较⼤提升。主要原因在于⼤部分图⽚中的物体的区域已经被擦除,这种情况下⼤量的背景区域也有可能被引⼊。因此只合并了前三次擦除的区域作为图⽚中的物体区域。
另外,本文的第二部分是使用提升好的CAM作为伪标签进行弱监督语义分割,不再本次讨论范围。缺点: 1,擦除动作论⽂试出来需要3次,但是不同数据集需要尝试设定这个参数;对于我们缺陷数据,⼤部分都是经过⼀次擦除就可以掩盖掉全部的缺陷特征;2,对于只需要提⾼CAM的场景,擦除动作引⼊的噪声很难克服;
ACoL
文章标题:Adversarial Complementary Learning for Weakly Supervised Object Localization
https://openaccess.thecvf.com/content_cvpr_2018/papers/Zhang_Adversarial_Complementary_Learning_CVPR_2018_paper.pdf
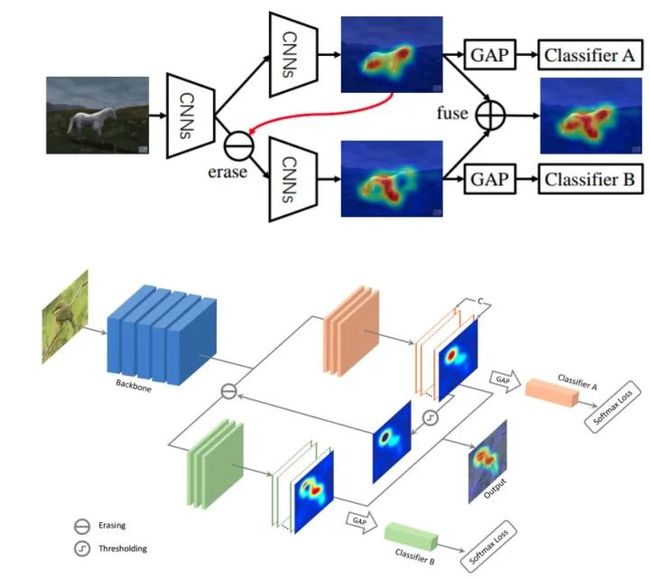
核心解读:
又被称为对抗互补擦除。具体流程可以通过上图解释,即现在我们有分类器A和B,先训练A分类,然后找出对应的类别的feature-map,然后在训练B过程中把这部分feature-map擦除(0代替),因为有监督训练B,因此B可以再学到该类别的其他区域(⽐如图中,A学习到的⻢的头和后腿,B学习到⻢的前脚,两个区域互补)。最终A和B两个学习的并起来就是完整的⽬标。最后融合的方式是pixel-wise的方式。
擦除的伪代码:
def erase_feature_maps(self, atten_map_normed, feature_maps, threshold):
if len(atten_map_normed.size())>3:
atten_map_normed = torch.squeeze(atten_map_normed)
atten_shape = atten_map_normed.size()
pos = torch.ge(atten_map_normed, threshold)
mask = torch.ones(atten_shape).cuda()
mask[pos.data] = 0.0 # 填0擦除
mask = torch.unsqueeze(mask, dim=1)
#erase
erased_feature_maps = feature_maps * Variable(mask)
return erased_feature_maps实验效果上,比CAM cover的更全一点。
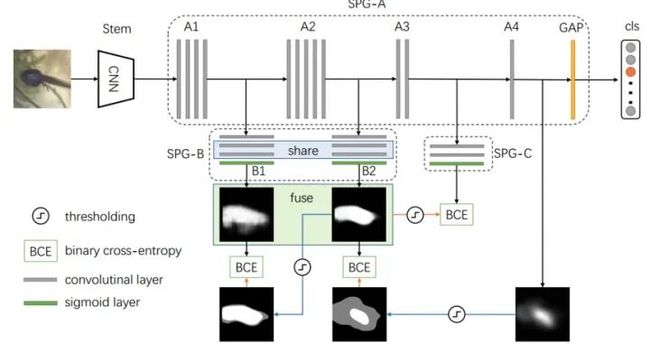
SPG
文章标题:Self-produced Guidance for Weakly-supervised Object Localization
https://arxiv.org/pdf/1807.08902v1.pdf
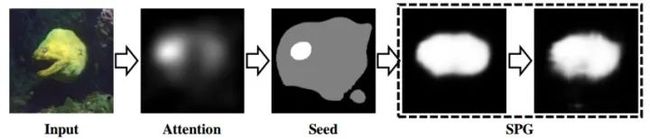
论⽂认为,分类CAM还是可以分出前景和背景的,虽然前景、背景概率较⾼的像素可能不会覆盖整个⽬标物体、背景,它们仍然提供重要的线索。基于此,论⽂利⽤这些可靠的前景、背景种⼦作为监督,以⿎励感知前景物体和背景分布的⽹络区域。具体做法为:给定⼀张图⽚,先根据分类⽹络⽣成attention maps,然后根据attention maps的置信度将其分成 object、background和undefined regions三部分Seed。
ACoL(作者也是他)⽅法的问题是,忽略了像素之间的关联性。因为有关联的像素之间往往共享类似的表征,所以⼀些reliable前景/背景区域可以通过这些seeds来发现。⽂中使⽤了⼀种top down机制,使⽤⾼层的输出作为底层的监督来学习物体的位置信息。SPG Masks {0,1,255}是根据以下公式产⽣的:
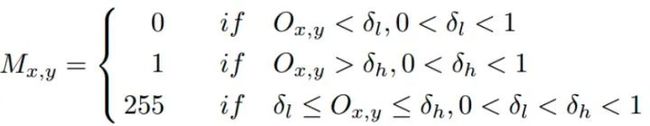
实验效果:

GAIN
文章标题:Tell Me Where to Look: Guided Attention Inference Network
https://arxiv.org/abs/1802.10171
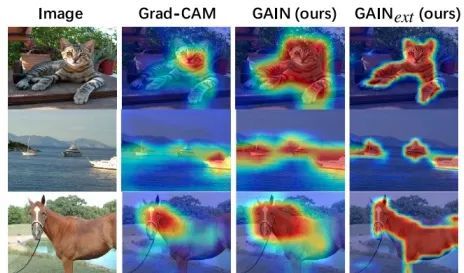
GAIN的作者发现了⼀个问题,那就是在识别某些物体的时候,⽹络容易会将“注意⼒CAM”放在和所要识别的物体相关的东西上,⽽不会将“注意⼒”放在物体本⾝上。如图所⽰,可以看出,⽹络在识别船的时候,却把“注意⼒”放在了⽔⾯上。

针对于本问题,作者提出了⼀种新的训练⽅式,通过在最⼩化原图像识别损失函数的同时来最⼩化遮挡住待识别物体的图像的识别分数来训练整个⽹络,训练后的⽹络能够更好的将“注意⼒”放在待识别的物体上
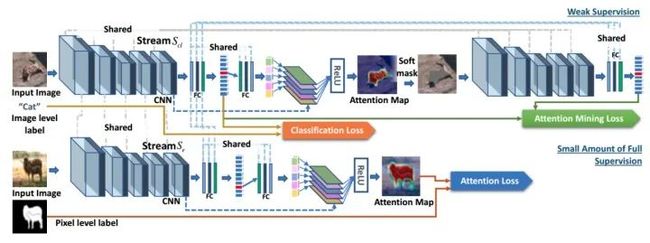
该结构可⽀持分类标签监督或语义监督或⼆者都有,其中语义监督可以为bbox形状的mask。该机制 work的原因猜测是利⽤了image net的预训练权重,能保证⽹络刚开始就能预测⽐较靠谱的attention map。该map通过grad-cam获取,是在线可训练的。然后利⽤注意⼒图对原始图⽚进⾏"擦除",擦除⽅式如下:
其中c为类别,I为原始图⽚,T()为⼆值化操作,乘的⽅式为pixel-wise相乘。⼆值化利⽤可导⼆值化的操作,σ为阈值:
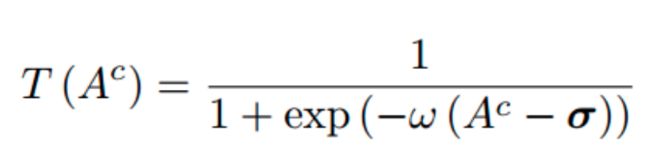
这⾥利⽤可导⼆值化的原因是,原图-前向-擦除图-前向是⼀个完整的前向过程,既后⾯⼀次前向后更新梯度的过程也会优化前⾯⼀次过程。整个训练的⽬的是:原始图⽚尽量获取更⾼的类别得分, "擦除"动作尽量将有⽤的特征掩盖掉,所以擦除图⽚尽量获取更低的类别得分。当然,使用了额外的语义map,CAM效果肯定会特别好,主要是一个思路吧。
SeeNet
文章标题:Self-Erasing Network for Integral Object Attention
https://arxiv.org/abs/1810.09821
⽂章认为,对抗擦除的⽅式,注意⼒区域随着训练持续的迭代,将逐渐扩展到⽆⽬标区域,这将显著降低注意⼒map的质量,也很难确定什么时候训练该停⽌。本⽂利⽤CAM⽣成三元mask,在featuremap上进⾏信息⾃擦除。
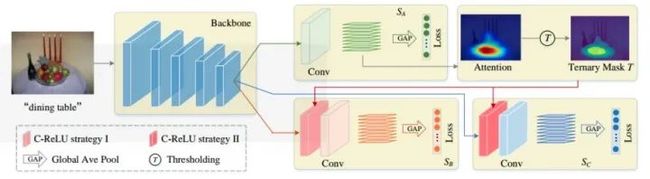
利⽤双阈值的⽅法获取Ternary Mask:三元mask,the internal“attention zone”, the external “background zone”, and the middle “potential zone”。
SA:initial attention ;
SB:擦除策略1:擦除背景区域, 并确保潜在区域被挖掘, 把TA的⾮负值设置为1;
SC:擦除策略2:避免attention到背景区域。将TA设置为背景为1,其余为0;
整个步骤就是:
利⽤CAM算法,得到初始的attention map A ;
根据阈值h(A最⼤值的0.7)和l(A最⼤值的0.05),将A阈值化为⼀个三元矩阵T,其中⼩于l的为-1,⼤于h的为0,在l和h之间的为1(为可能包含物体的区域);
根据输⼊的特征图F和得到的三元矩阵T,阈值化,得到erase后的特征,对其分类;
根据T,得到⼀个⼆元矩阵,其中背景区域为1,前景区域为0,对背景特征分类,使其不属于任意类别;
最终map获取的⽅式:丢弃SC,把SA和SB进⾏融合,另外还⽤到Hflip进⾏多次融合,下图对应b是本文效果。
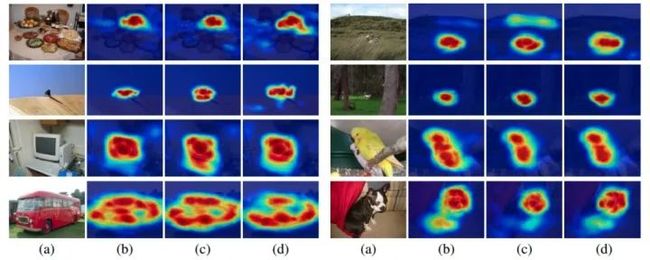
ADL
文章标题:Attention-based Dropout Layer for Weakly Supervised Object Localization
https://arxiv.org/abs/1908.10028
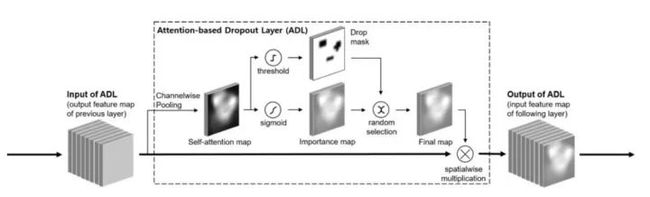
思路比较简单,结合空间注意⼒和特征擦除操作,在每⼀层卷积上插⼊该模块,没有可学习的参数。训练过程,每次forward, 都会随机选择使⽤importance map 或 drop mask作⽤到特征图上;测试过程,不使⽤该模块。有两个超参需要设置, 获取drop mask的阈值,以及随机选择的概率;阈值⽤以控制只是擦除明显,容易判别的特征。随机选择的⽅式防⽌最明显特征全部被擦除导致⽹络confuse。

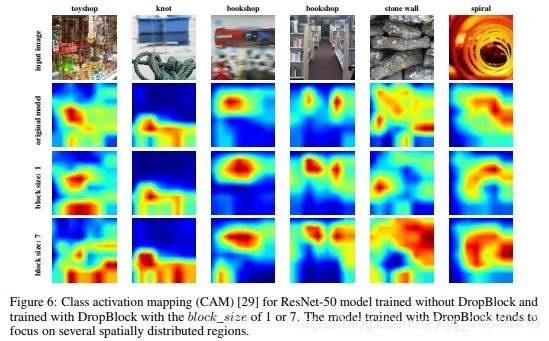
Dropblock
文章标题:DropBlock: A regularization method for convolutional networks
https://arxiv.org/pdf/1810.12890.pdf

b图表示了随机dropout激活单元,但是这样dropout后,网络还会从drouout掉的激活单元附近学习到同样的信息。c图表示本文的DropBlock,通过dropout掉一部分相邻的整片的区域(比如头和脚),网络就会去注重学习狗别的部位的特征,来实现正确分类,从而表现出更好的泛化能力。整体流程:

FickleNet
文章标题:FickleNet: Weakly and Semi-supervised Semantic Image Segmentation using Stochastic Inference
https://arxiv.org/abs/1902.10421
⽂章认为,之前的图像级擦除和特征图的擦除,⼀般必须有第⼆个分类器,⽽第⼆个分类器仅有次优性能。另外,具有判别⼒的特征被删除会混淆第⼆个分类器,⽽第⼆个分类器可能没有得到正确的训练。⽽区域增⻓的⽅法,会⽐较依赖初始CAM种⼦的质量,⽽且很难增⻓到⾮最具判别的区域。
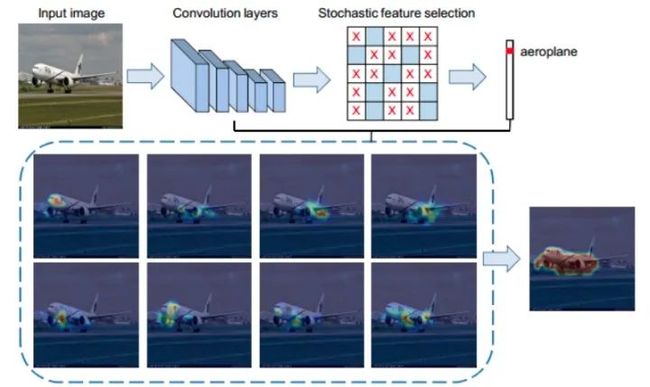
FickleNet通⽤CNN特征图上的各种定位组合。它随机选择隐藏单元,然后使⽤它们获得图像分类的激活分数。隐含地学习了特征映射中每个位置的⼀致性,从⽽产⽣了⼀个定位图, 它可以识别对象的其他部分。通过选择随机隐藏单元对从单个⽹络获得整体效果,这意味着从单个图像⽣成各种定位图。该⽅法不需要任何额外的训练步骤,只需在标准卷积神经⽹络中添加⼀个简单的层。选择所有隐藏单元,将⽣成平滑效果作为背景和前景⼀起激活。随机选择隐藏单位可以提供更灵活的组合,可以更清楚地对应对象的部分或背景。与传统dropout最⼤的区别是,传统dropout只在训练中使⽤,⽽本⽂⽅法在测试中也会⽤。主要步骤:
Stochastic hidden unit selection: 它使⽤随机选择的隐藏单元,多分类任务训练。
Training Classifier: 然后⽣成训练图像的定位图。
Inference CAMs: 最后获取CAM。
后记
希望你能举一反三,从本文得到一些思路,应用到实际的需求当中。
好消息,小白学视觉团队的知识星球开通啦,为了感谢大家的支持与厚爱,团队决定将价值149元的知识星球现时免费加入。各位小伙伴们要抓住机会哦!
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~