初识scrapy - scrapy成神之路
逐渐深入
-
- 准备工作
-
- 安装 :
- 创建工程 :
- 构建爬虫文件 :
- 对settings.py文件设置:
- 简单案例
-
- 运行操作:
- 演示代码:
- 内容解析:
- 运行查看结果:
- 持久化存储
-
- 基于终端的存储
- 基于管道的存储
- 保存到数据库中
- scrapy递归爬虫
- 爬取图片
- 中间件操作
-
- 更换User-Agent和代理IP
- selenium与scrapy的简单结合
- crawlspider爬取全站数据
-
- 基本讲解
- 开始实战
准备工作
安装 :
pip install scrapy
创建工程 :
在终端下输入scrapy startproject 工程名字,运行完生成两个文件
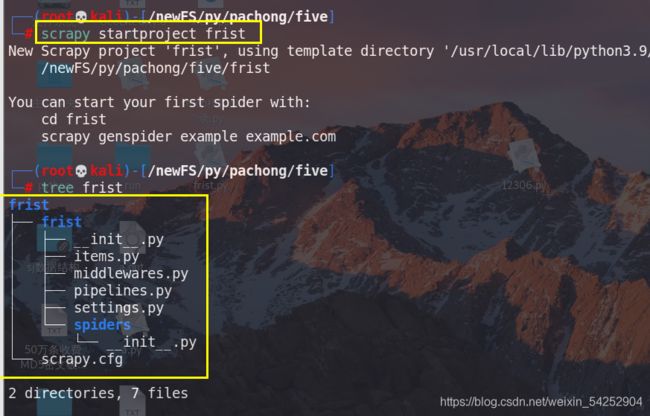
构建爬虫文件 :
必须先进入目录, scrapy genspider 文件名(不用添加py后缀,自动添加) url(随便)
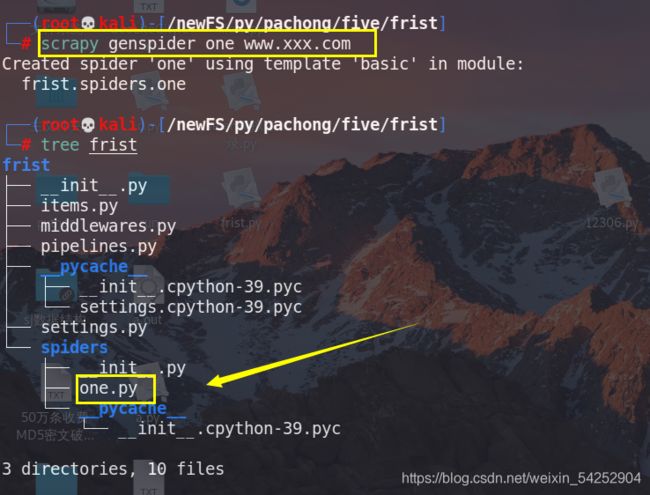
这个one.py就是将要编写爬虫文件
对settings.py文件设置:
USER_AGENT:表示你的请求头,你可以自行进行修改
ROBOTSTXT_OBEY = False #不遵循roboot协议(君子协议)
LOG_LEVEL = ‘ERROR’ #输出过程只显示错误日志
简单案例
运行操作:
scrapy crawl 你的文件名(不加py后缀)
演示代码:
下面我的python文件为frist.py
import scrapy
class FristSpider(scrapy.Spider):
name = 'frist'
#allowed_domains = ['www.xxx.com']
start_urls = ['https://www.runoob.com/coder-learn-path']
def parse(self, response):
div_List = response.xpath('//div[@class="article"]')
#title = div_List.xpath('./div[2]/h2[3]/text()')[0].extract()
title = div_List.xpath('./div[2]/h2[3]/text()').extract_first()
#调用extract方法后可以将selector对象中存储的字符串提取出来
nei = div_List.xpath('./div[2]/ol[3]//text()').extract()
nei = "".join(nei) #将列表转换成字符串
print(title,nei)
内容解析:
name = “” 你的爬虫文件名
allowed_domains=[] :只有这个url可以发起请求,对start_urls进行限制,注释即可
start_urls = [] :里面是你想要发起请求的url地址,可以有多个以逗号隔开
这个框架可以直接调用xpath解析
div_List = response.xpath(’//div[@class=“article”]’) 返回的是一个selector对象
![]()
存储着这种形式的数据,前面是你的xpath路径,后面是正常爬虫返回数据
nei = div_List.xpath(’./div[2]/ol[3]//text()’).extract() #extract()函数是将Selector中的data数据取出
#.extract_first()是对第一个selector的data数据取出
nei = “”.join(nei) #将列表转换成字符串 #由于最后取出的data是列表形式,将列表转换成字符串
运行查看结果:
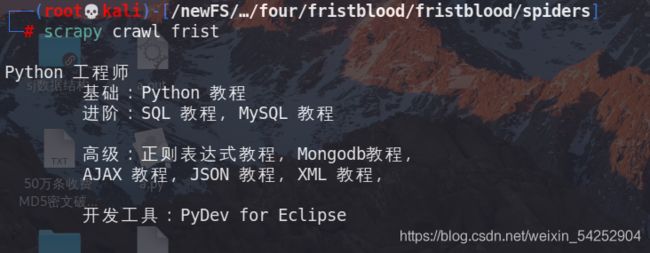
完美!
持久化存储
基于终端的存储
前提爬虫文件返回具体数据
如:
def parse(self, response):
date = []
div_List = response.xpath('//div[@class="article"]')
for i in range(1,6):
title = div_List.xpath('./div[2]/h2['+str(i)+']/text()').extract_first()
#调用extract方法后可以将selector对象中存储的字符串提取出来
nei = div_List.xpath('./div[2]/ol['+str(i)+']//text()').extract()
nei = "".join(nei) #将列表转换成字符串
dic = {
"title":title,
"data":nei
}
print(title,nei)
date.append(dic)
return date
最终都把爬虫的数据存储到一个列表中,当做返回值进行返回
终端执行命令:scrapy crawl 爬虫文件名(不加py后缀) -o 保存的文件
只能保存成:json csv xml等格式
演示:
- scrapy crawl frist -o frist.json
- scrapy crawl frist -o frist.csv
- scrapy crawl frist -o frist.xml
基于管道的存储
你需要先在item.py文件中创建几个对象,然后再在你的爬虫文件中把爬虫数据存储到这几个对象中,在发送给管道文件pipelines.py
- 先在item.py文件中,设立几个对象,这几个对象是最终要把你爬虫得到的数据存储进去
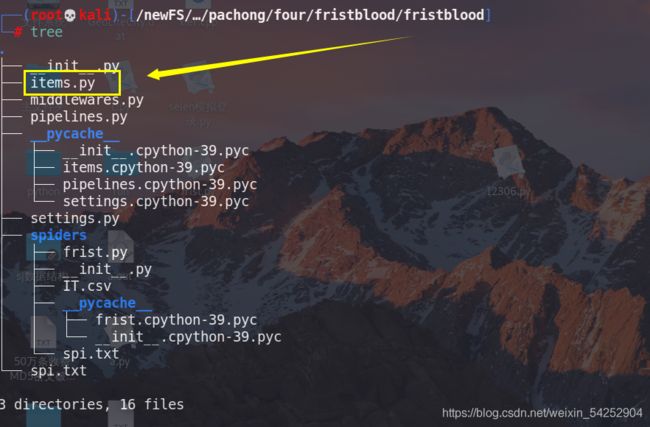
创建格式为:对象名 = scrapy.Field()
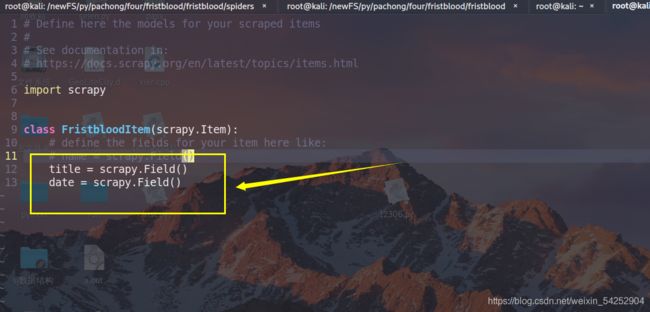
2.将爬虫数据存储到这几个对象中
因为要用的这几个对象,所以先把对象导入爬虫文件,这里直接导入类即可

def parse(self, response):
date = []
div_List = response.xpath('//div[@class="article"]')
for i in range(1,6):
title = div_List.xpath('./div[2]/h2['+str(i)+']/text()').extract_first()
#调用extract方法后可以将selector对象中存储的字符串提取出来
nei = div_List.xpath('./div[2]/ol['+str(i)+']//text()').extract()
nei = "".join(nei) #将列表转换成字符串
item = FristbloodItem()
item['title'] = title
item['date'] = nei
yield item
核心代码多了这几句
item = FristbloodItem() #创建一个类对象,就是item.py中的类对象
item[‘title’] = title #把爬虫数据赋给类的对象中的title,就是你创建的对象
item[‘date’] = nei #
yield item #把爬虫数据存到类对象中后,发给pipelines.py中的对象
- pipelines.py
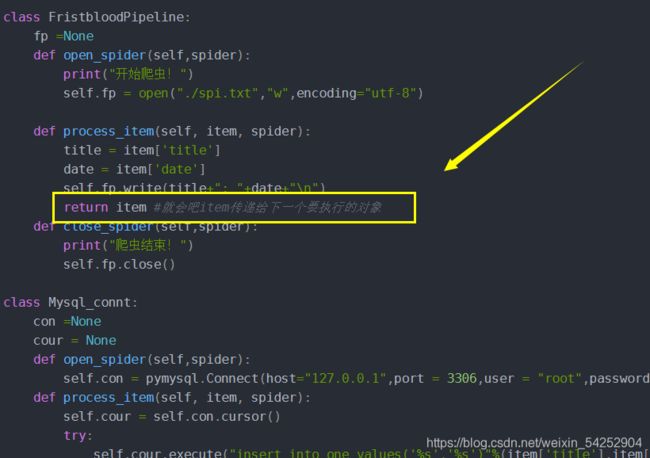
class FristbloodPipeline:
fp =None
def open_spider(self,spider):
print("开始爬虫!")
self.fp = open("./spi.txt","w",encoding="utf-8")
def process_item(self, item, spider):
title = item['title']
date = item['date']
self.fp.write(title+": "+date+"\n")
return item #就会吧item传递给下一个要执行的对象
def close_spider(self,spider):
print("爬虫结束!")
self.fp.close()
定义open_spider方法,这是框架自带的方法,用来当 process_item()执行前的操作
创建一个文件句柄:self.fp = open("./spi.txt",“w”,encoding=“utf-8”)
核心代码:
def process_item(self, item, spider): #参数接受item数据
title = item[‘title’] #取出item对象中title数据
date = item[‘date’] #取出item对象中的date数据
self.fp.write(title+": “+date+”\n") #写入本地文件
close_spider()是当程序结束后调用,关闭文件句柄
- 最好配置setting.py文件
把下面代码前面的注释去掉,表示调用此程序,300表示文件执行的先后顺序,数值越小,越先执行。类似与权重
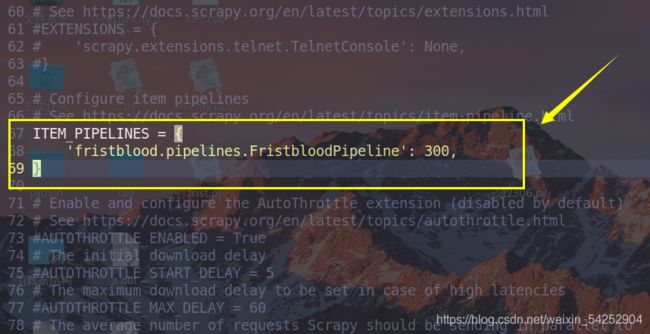
5.执行:scrapy crawl frist
查看保存的本地文件:
成功!
保存到数据库中
在pipelines.py文件中导入pymysql数据库模块
下载命令:pip3 install pymysql
python连接数据库:
https://www.cnblogs.com/chongdongxiaoyu/p/8951433.html
https://blog.csdn.net/limy_liu/article/details/103831912
from itemadapter import ItemAdapter
import pymysql
class FristbloodPipeline:
fp =None
def open_spider(self,spider):
print("开始爬虫!")
self.fp = open("./spi.txt","w",encoding="utf-8")
def process_item(self, item, spider):
title = item['title']
date = item['date']
self.fp.write(title+": "+date+"\n")
return item #就会吧item传递给下一个要执行的对象
def close_spider(self,spider):
print("爬虫结束!")
self.fp.close()
class Mysql_connt:
con =None
cour = None
def open_spider(self,spider):
self.con = pymysql.Connect(host="127.0.0.1",port = 3306,user = "root",password ="123.com",db = "IT",charset="utf8")
def process_item(self, item, spider):
self.cour = self.con.cursor()
try:
self.cour.execute("insert into one values('%s','%s')"%(item['title'],item['date']))
self.con.commit()
except Exception as e:
print(e)
return item #就会吧item传递给下一个要执行的对象
def close_spider(self,spider):
print("存取数据库结束!")
self.cour.close()
self.con.close()
相比较与上面的操作就是添加了对数据的操作,
我先申明:这个class FristbloodPipeline:对只是保存到本地文件的那串代码,对数据库没有任何关系,只是他用完item后,把其传给了下面需要用的对象罢了
核心代码:
class Mysql_connt:
con =None
cour = None
def open_spider(self,spider):
#连接数据库
self.con = pymysql.Connect(host="127.0.0.1",port = 3306,user = "root",password ="123.com",db = "IT",charset="utf8")
def process_item(self, item, spider):
# 得到一个可以执行SQL语句的光标对象
self.cour = self.con.cursor()
try:
# 执行SQL语句,把爬虫得到的数据写入one数据库中
self.cour.execute("insert into one values('%s','%s')"%(item['title'],item['date']))
#提交事务
self.con.commit()
except Exception as e:
print(e)
return item #就会吧item传递给下一个要执行的对象
def close_spider(self,spider):
print("存取数据库结束!")
self.cour.close()
self.con.close()
最好配置settings.py文件
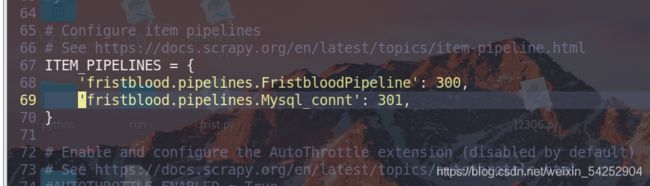
把创建的对数据库操作的类写入其中,后面的数字代表执行先后,越小越先执行
这里有一点要注意,就是item,因为我们是先执行300那个类操作,当执行完后item要传给301使用,只需要把item当做返回值即可
执行命令:scrapy crawl frist
提示数据太长了,没事。
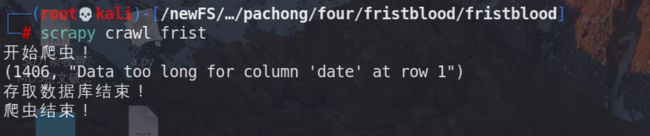
查看IT数据库的one表:
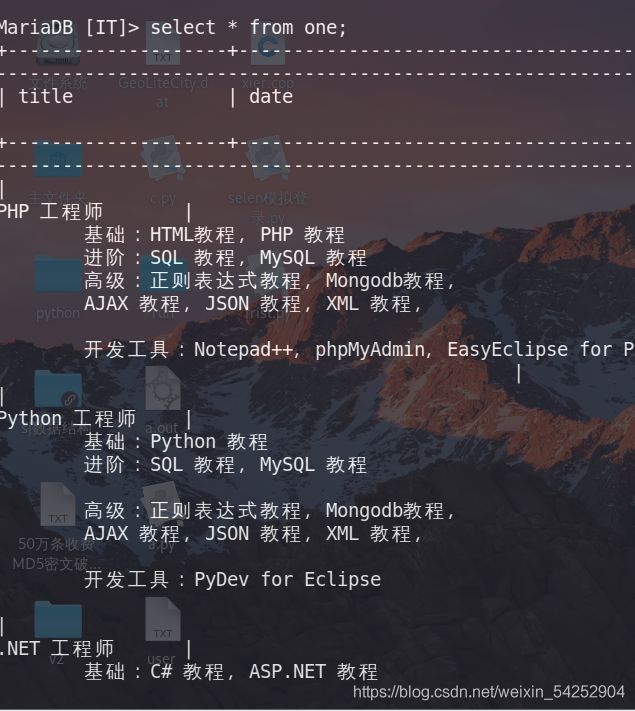
成功!
scrapy递归爬虫
主要爬取带有页码规律的url数据
import scrapy
class OneSpider(scrapy.Spider):
name = 'one'
#allowed_domains = ['www.xxx.com']
start_urls = ['https://pic.netbian.com/4kyouxi/']
urls = "https://pic.netbian.com/4kyouxi/index_%d.html"
page_num = 2
def parse(self, response):
li_list = response.xpath('//div[@class="slist"]/ul/li')
for li in li_list:
src = li.xpath('./a/img/@src')[0].extract()
img_src = "https://pic.netbian.com" + str(src)
print(img_src)
#====================关键部分来了=======================
#我这里只爬取5页,你可以随便设置
if self.page_num <= 5:
#拼接新的url
new_url = format(self.urls%self.page_num)
#然后页码数据加1,使下次爬取下一页数据
self.page_num = self.page_num + 1
#向scrapy.Request发起请求回调self.parse函数url参数为新的url
yield scrapy.Request(url=new_url,callback=self.parse)
这些代码相较于前面的代码就是多了这几句:
-
urls = “https://pic.netbian.com/4kyouxi/index_%d.html” #因为要爬区对方网站是以分页的方式,而url与分页码有关,我们正好抓住这点,来把数字逐渐加1来变量url页面
-
page_num = 2 #先从第二个开始,为什么不从第一个,因为第一个的url上面没有数字1,只有从第二个开始以后才有数字规律
-
new_url = format(self.urls%self.page_num) #format拼凑,不要说不会,python基础部分内容
-
self.page_num = self.page_num + 1 #然后把数字加1,来进行循环
-
yield scrapy.Request(url=new_url,callback=self.parse) #关键部分,向scrapy.Request重新发起请求,参数为新的url,和爬虫方法,callback=self.parse一为回调self.parse函数
执行命令:scrapy crawl one
成功!
爬取图片
前面的都是对文本数据进行爬取,没有对图片二进制爬取,
图片的爬取与文本的爬取是不一样的用scrapy
这里我们使用scrapy自带的类对象: ImagesPipeline
并编写我们自己的类方法
先上基础代码:
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ImgItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
img_src = scrapy.Field()
爬虫文件
import scrapy
from IMG.items import ImgItem #这里我们要把请求的数据发送给管道,所以引入item对象来把数据进行传递给管道
class ImgSpider(scrapy.Spider):
name = 'img'
#allowed_domains = ['www.xxx.com']
start_urls = ['https://sc.chinaz.com/tupian/']
def parse(self, response):
div_list = response.xpath('//*[@id="container"]/div')
for div in div_list:
src2 = div.xpath('./div//a/img/@src2')[0].extract()
img_src = "https:" + str(src2)
#定义一个item对象
item = ImgItem()
#给item中的img_src对象赋值
item['img_src'] = img_src
#把item发给管道,进行处理
yield item
核心管道文件:pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from scrapy.pipelines.images import ImagesPipeline #引入这个处理图片的类
import scrapy
import re #正则
#我们自己定义一个类对象,用来处理图片,继承与ImagesPipeline这个scrapy自带的类
class Img_piple(ImagesPipeline):
#重写父类的get_media_requests方法,对图像地址发起请求
def get_media_requests(self,item,info):
#直接yield发送给Request方法图像地址(item['img_src']),这样就会直接对图像地址发起请求
yield scrapy.Request(item['img_src'])
#重新file_path方法,保存图像名字
def file_path(self,request,response=None,info=None):
#这里我要对图片的名字进行设置,截取url最后的部分,就是原图片的名称
imgName = request.url.split('/')[-1]
#imgNa = request.url.split('/')[-1]
#ret = re.search('(\w*)_s.jpg',imgNa)
#imgName = ret.group(1) + ".jpg"
return imgName #返回图像名称
#重新item_completed方法
def item_completed(self,results,item,info):
return item #返回item值,给下一个需要用的对象
这里有一点需要注意https://sc.chinaz.com/tupian/这个网站的图片加载形式是图片懒加载,意思是:当我们没有看到图片时,图片的属性和看到图片的属性是不一样的
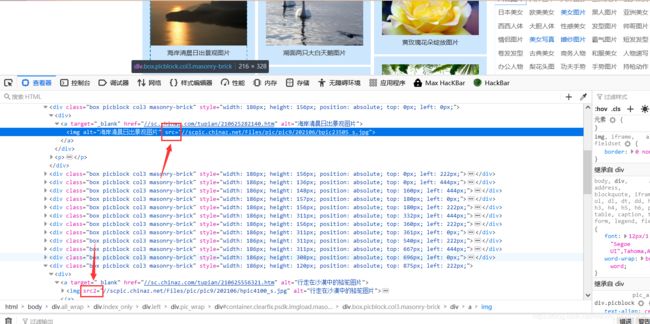
上面的地址图片,是我们已经看到已经加载的图片他的属性是src,而下面的图片我们还没有看到所以他的属性是src2,而我们爬虫时是看不到图片的,所以都是src2,故要把src改为src2
settings.py文件
定义图片保存的地址
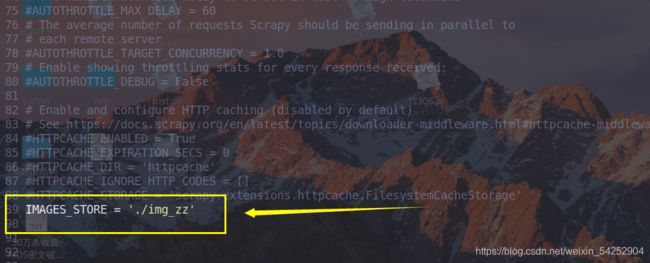
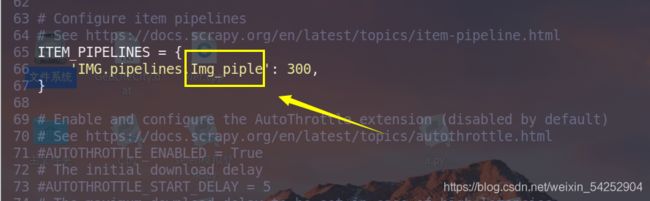
开启管道类,要把名字改成我们自定义的管道类的名字
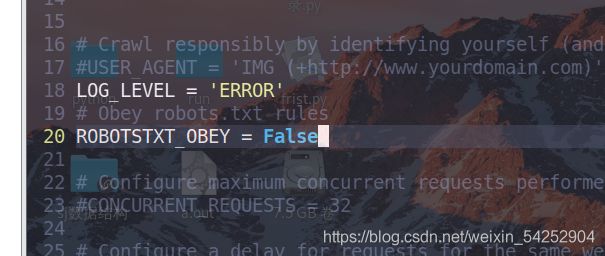
还有把禁用reboot协议和错误日志即可
执行命令

成功!
中间件操作
这里我就不做赘述了,这篇讲的很不错!https://www.cnblogs.com/xieqiankun/p/know_middleware_of_scrapy_1.html
直接操作
更换User-Agent和代理IP
重写我们的中间件文件 middlewares.py
这里我们只对下载中间件进行操作,所以就把和爬虫中间件给删了,并把一些没有用的方法去除了
from scrapy import signals
import random
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
#下载中间件
class IpUaDownloaderMiddleware:
USER_AGENT_LIST = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0) ',
]
http_proxy = "172.21.204.107:10809" #这是我本地的代理ip用于测试的
#定义的http代理ip
http_proxy_list = [
"195.225.49.134:58302"
"80.93.213.214:3128"
]
#定义的https代理ip
https_proxy_list = [
"94.28.8.61:8080"
"178.222.250.223:59083"
]
#拦截请求
def process_request(self, request, spider):
#对请求头中的UA进行设置,从代理池中随机抽取一个
request.headers['User-Agent'] = random.choice(self.USER_AGENT_LIST)
#更换请求中的ip,这里我用于测试的代理ip
request.meta['proxy'] = "http://172.21.204.107:10809"
return None
# 拦截数据相应
def process_response(self, request, response, spider):
return response
#拦截发生异常的响应
def process_exception(self, request, exception, spider):
#由于我们爬虫时,容易Ip就会被对方封禁,这是就会发出异常,针对异常我们对ip进行设置
#如果请求的url地址是基于http的就从http代理Ip中更换
if request.url.split(':')[0] == "http":
request.meta['proxy'] = "http://" + random.choice(self.http_proxy_list)
#剩下的就是https了
else:
request.meta['proxy'] = "https://" + random.choice(self.https_proxy_list)
#异常处理好后,要把请求重新发送
return request
USER_AGENT_LIST:因为我们要更换UA头,所以找了个UA池来进行设置
ok,这样就设置好了!
selenium与scrapy的简单结合
今天爬取的是网易新闻的四个模块:国内,国际,军事,航空

可能你会想这有什么好爬的,哼哼,格局小了,这个新闻可是动态加载的,你如果使用单纯的定位标签是获取不到信息的,你看我点开这个军事,而里面的信息是处于加载状态,这个时候你是获取不到标签数据的

所以我们要考虑使用selenuim和scrapy结合,你不是动态加载吗,我直接selenium获取页面源码数据,
但获取的源码数据怎么给scrapy接受处理呢,这就要使用下载中间间了
开干:
- 新建工程
scrapy startprojiect NEW
cd NEW
scrapy genspider new www.xxx.com
- items文件
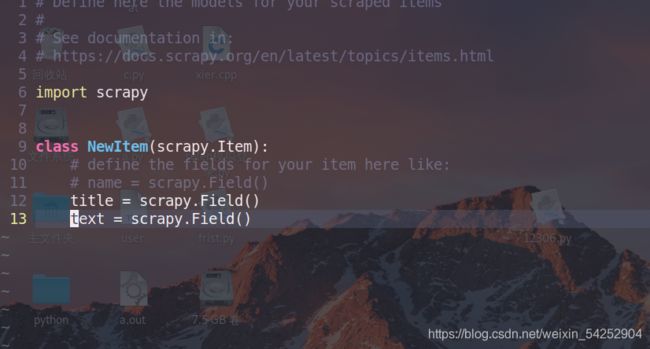
创建两个对象,用于接受标题数据和主要新闻数据
- 对爬虫文件进行处理
import scrapy
from NEW.items import NewItem #导入item,最后要把数据给item存储
from selenium import webdriver #导入selenium
class NewSpider(scrapy.Spider):
name = 'new'
#allowed_domains = ['www.xxx.com']
start_urls = ['https://news.163.com/']
ul_sort = [2,3,5,6] #因为我们爬取的四个板块位置下标
modol_urls = [] #要把获取到的url信息存到列表中
def __init__(self):
self.web = webdriver.Chrome(executable_path="./chromedriver.exe") #创建一个浏览器对象,记住要下载对应的驱动哦,我用的是谷歌的驱动,如果不明白看我写的selenuim那一篇
def parse(self, response):
li_list = response.xpath('//div[@class="ns_area list"]/ul/li')
for i in self.ul_sort:
li = li_list[i].xpath('./a/@href')[0].extract() #后期这四个板块的url信息
self.modol_urls.append(li) #添加到列表中
for url in self.modol_urls: #针对这四个url信息,我们进行处理,调用函数
yield scrapy.Request(url=url,callback=self.parse_model)
def parse_model(self,response):
div_list = response.xpath('//div[@class="ndi_main"]/div')
#print(div_list)
for div in div_list:
title = div.xpath('./div/div[1]/h3/a/text()')[0].extract() #获取新闻界面的标签信息
detail_url = div.xpath('./div/div[1]/h3/a/@href')[0].extract() #和因为主要信息都另存在一个url中,所以我们又要在一次获取其中的url信息
#print(title)
#print(detail_url)
item = NewItem() #创建一个item对象,用于本地存储,不要说不会啊,我前面都讲过
item['title'] = title #把标题信息赋给item对象中的title
yield scrapy.Request(url=detail_url,callback=self.parse_datail_url,meta={
"item":item})
#接下来,我们就要对获取的主要信息的url发送请求
#这里有一点要注意,就是这个meta,他是传递参数,因为我们的item对象在这个函数中,
#而我们最终获取的信息要在下一个函数中处理,所以要把item传递给调用的函数,
#让下一个函数给item中的text赋值
def parse_datail_url(self,response):
#定位主要的具体内容信息
div_text = response.xpath('//div[@class="post_body"]//text()').extract()
#由于返回的是列表,我们把他转换为字符串
div_text = "".join(div_text)
#看,这就是接受这个item参数
item =response.meta['item']
#然后给Item中的text赋值
item['text'] = div_text
#最后都处理完了,交给管道文件进行处理
yield item
我上面的注释,写的已经特别详细了
4.主要中间件文件
我已经把其他没用的信息删除了,只留最核心的就行了,其他都暂且没什么用
from scrapy import signals
from itemadapter import is_item, ItemAdapter
from scrapy.http import HtmlResponse #引入这个模块,来把处理的响应数据转化为scrapy能接受的形式
from selenium import webdriver
import time
class NewDownloaderMiddleware:
def process_request(self, request, spider):
#这里我就不使用UA伪装和ip代理了
return None
#对拦截的响应数据进行处理
def process_response(self, request, response, spider):
#接受爬虫文件终端浏览器对象
web = spider.web
#这就显示到刚才在爬虫文件中把那四个板块存储到列表中的好处了
#我们根据请求的url栏进行操作,因为我们只针对那四个板块的响应数据进行处理
#所以我们根据,请求的url在不在这四个url中来进行判断处理
if request.url in spider.modol_urls:
web.get(request.url) #如果在,就使用浏览器对这个url发起请求
web.execute_script('window.scrollBy(0,5000)')
#执行js语句让浏览器向下滑动页面(5000像素),使更多的数据加载出来
time.sleep(1)
web.execute_script('window.scrollBy(5000,10000)')
time.sleep(1)
web.execute_script('window.scrollBy(10000,15000)')
time.sleep(1)
web.execute_script('window.scrollBy(15000,20000)')
time.sleep(2) #暂停时间,让页面加载出来
page_txt = web.page_source #获取页面的源码数据
#最关键的一步,我们要把获取的响应源码数据交给scrapy,记住,就以这种形式写就行了
#url就是原本请求的url,最重要的body就是页面源码数据
new_response = HtmlResponse(url=request.url,body=page_txt,encoding="utf-8",request=request)
#最后返回数据
return new_response
else:
return response
def process_exception(self, request, exception, spider):
pass
- 管道文件
from itemadapter import ItemAdapter
class NewPipeline:
f = open("./new.txt","w",encoding="utf-8")
def process_item(self, item, spider):
title = item['title'] #接受item中的title值
text = item['text']
self.f.write(title + text) #写入文件
return item
def close_spider(self,spider):
print("爬虫结束!")
self.f.close() #结束后关闭文件句柄
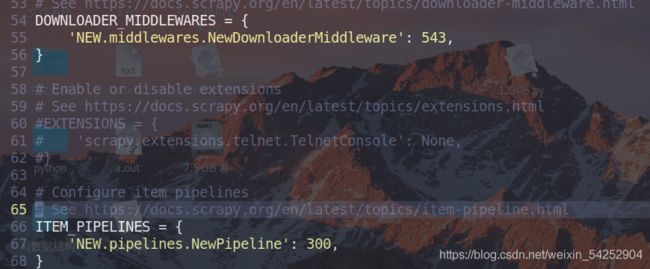
6.settings文件
开启管道和下载中间件
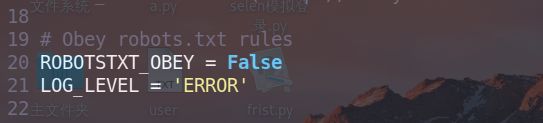
禁用reboot协议和只打印错误信息
7.执行命令
scrapy crawl new
成功!
crawlspider爬取全站数据
基本讲解
crawlspider也是scrapy爬取数据的一种形式,让我们来试一试吧
新建工程
scrapy startproject CRAWL
cd CRAWL
scrapy genspider -t crawl one www.xxx.com #这里是带-t参数的哦
我们的爬虫文件内容:
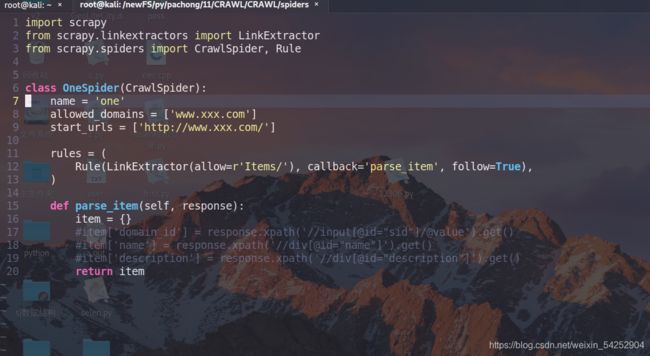 这个Rule为规则解析器,rules 实例化了一个规则解析器对象
这个Rule为规则解析器,rules 实例化了一个规则解析器对象
- 作用:将链接提取器提取到的链接进行指定规则(callback)的解析
这个LinkExtractor为链接提取器,作用在规则解析器当中
- 作用:根据指定的规则(allow)进行指定链接的提取
我们来解释一下他们的作用,这个链接提取器根据正则表达式所匹配到url链接,来交给callback回调函数处理,至于这个follow=True表示如果提取到url,则会自动在作用到提取的url进行回调函数处理,是不是不明白,看下面:
而这个正则匹配也很有意思,只有匹配到Url链接的一部分就可以提取完整url,我来演示
这里的follow=False,表示提取到url后不重新作用到这个url上
左边为settings.py文件设置禁用reboot协议和只显示错误日志
爬虫文件中,我匹配正则表达式只根据后面的id和page进行匹配就能匹配到这个url
不需要匹配完整,只要匹配到其中的一部分即可,挺强大的
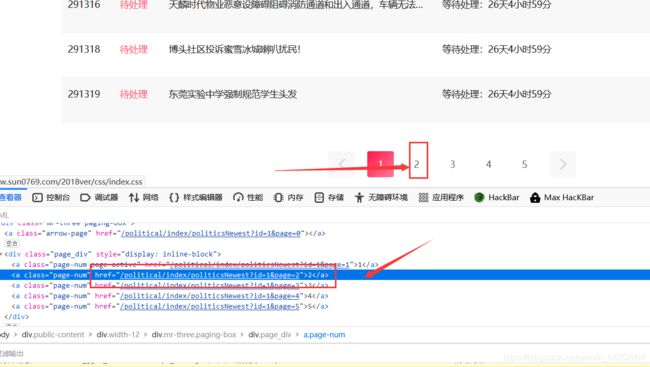
运行一下看看,scrapy crawl one
这里说明一点,如果匹配到重复的url会自动去重
 成功爬取!,而这个只显示这个页面源码中的url,还有其他的页的没有提取,因为我们现在是定位到了这个第二页的url上,当我们设置follow=True时,会自动对提取到了url页面进行一次callback相同操作,上代码看看吧:
成功爬取!,而这个只显示这个页面源码中的url,还有其他的页的没有提取,因为我们现在是定位到了这个第二页的url上,当我们设置follow=True时,会自动对提取到了url页面进行一次callback相同操作,上代码看看吧:
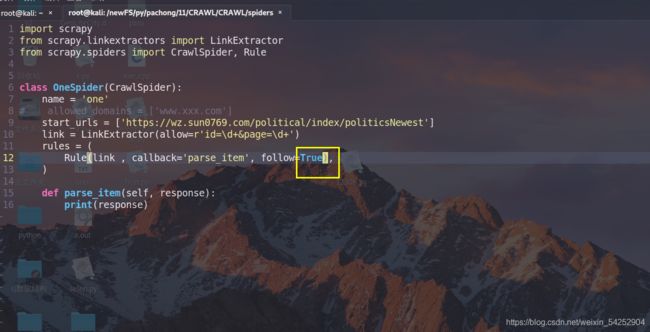
执行命令:
看明白了吧,他就是会吧提取到的url为对象进行一次相同的callback操作,因为每页所显示的页码数都是固定的几个,当我们在第一页时只能提取到1-5
当我们在第5页时,能提取到3-7,就这样逐渐递归就会把全站的页面url给提取到

开始实战
对象https://wz.sun0769.com/political/index/politicsNewest
爬取页面的编号和问政标题,和他所对应的内容信息
 每一个问政标题都对应一个url,主要信息都存在其中:
每一个问政标题都对应一个url,主要信息都存在其中:

直接上代码,解释都在注释中
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from CRAWL.items import CrawlItem #最后要保存数据所以要使用item
from CRAWL.items import Detail_CrawlItem #我又令创建了一个item,为什么要另创建,向下看
class OneSpider(CrawlSpider):
name = 'one'
#allowed_domains = ['www.xxx.com']
start_urls = ['https://wz.sun0769.com/political/index/politicsNewest']
link = LinkExtractor(allow=r'id=\d+&page=\d+') #这个是匹配提取每一页的url
#因为这个主要信息,都在另一个问政标题里的url里面,所以要提取其中的url
link2 = LinkExtractor(allow=r'index\?id=\d+')
rules = (
Rule(link , callback='parse_item', follow=True),
Rule(link2 , callback='parse_detail_url') #因为这个是直接就取数据,不需要使用follow
)
def parse_item(self, response):
li_list = response.xpath('//div[@class="width-12"]/ul[@class="title-state-ul"]/li')
#print(li_list)
for li in li_list:
#提取编号
tip = li.xpath('./span[@class="state1"]/text()')[0].extract()
#提取问政标题
title = li.xpath('./span[@class="state3"]//text()')[0].extract()
#实例化一个item用于本地存储
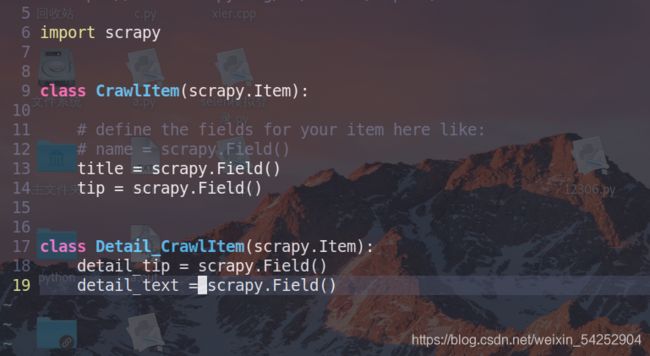
item = CrawlItem()
#把编号赋给item中的tip
item['tip'] = tip
#把问政标题赋给item中的title
item['title'] = title
#发送给管道进行处理
yield item
#每一个问政标题都对应一个url,主要信息都存在其中
#所以我们需要另使用一个函数来处理,上面的callback就是这个函数
def parse_detail_url(self,response):
#匹配图片上的编号,这里你们会有个疑问刚才不是已经提取过编号了吗,为什么再提取一次
#这是因为,如果我们想把数据存到数据库中的话,当然是信息对应编号了
#如果我们不匹配这个编号,到时候向数据库中存数据的话,该向哪个编号所对应的存呢
#当然是利用这个编号和上面提取的编号进行对比,相等则存入其中
detail_tip = response.xpath('/html/body/div[3]/div[2]/div[2]/div[1]/span[4]/text()')[0].extract()
#提取主要信息
detail_text = response.xpath('//div[@class="width-12 mr-three"]/div[2]/div[@class="details-box"]/pre/text()')[0].extract()
#看到了吧,这里就是为什么我要另写一个item对象,
#因为crawlspider中不像spider那样,它没有参数传递,没办法两个函数使用同一个item
#只能再写一个item了
item = Detail_CrawlItem()
#把编号赋给item中的tip
item['detail_tip'] = detail_tip
#把主要信息赋给item中的detail_text
item['detail_text'] = detail_text
#发送交给管道处理
yield item
item文件,这下更明白了吧
管道文件
import pymysql
from itemadapter import ItemAdapter
class CrawlPipeline:
con =None
cour = None
title = None
tip = None
detail_tip = None
detail_text = None
def open_spider(self,spider):
self.con = pymysql.Connect(host='127.0.0.1',port=3306,user='root',password='123.com',db='tab',charset='utf8')
print('开始存储')
def process_item(self, item, spider):
self.cour = self.con.cursor()
if item.__class__.__name__=='CrawlItem':
self.tip = item['tip']
self.title = item['title']
else:
self.detail_tip = item['detail_tip']
self.detail_text = item['detail_text']
#我这里没写好,就注释了
#self.cour.execute("insert into news(detail_text) values('%s') where %s = news.tip"%(self.detail_text,self.tip))
#self.con.commit()
#self.cour.execute("insert into news(tip,titile) values('%s','%s')"%(self.tip,self.title))
#self.con.commit()
def cloes_spider(self,spider):
print("爬虫结束!")
self.con.close()
self.cour.close()
return item
这里需要注意的一点是我们使用管道接受item时由于传过来的是两个,我们怎么区分呢
使用Python的类方法
item._class_._name_==‘CrawlItem’ 用于判断item的类对象名称,来区分,
剩下的就是导入数据库或本地存储的操作了,每什么好说的了上面已经写过了
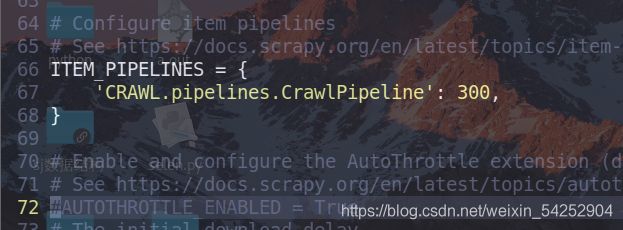
最后的settings.py文件
要开启管道
ok了…
就要完了,哈哈 ,还剩最后的分布式爬虫,和增量式爬虫…