文章根据 Juicedata 工程师朱唯唯,在云原生 Meetup 杭州站所作主题演讲《JuiceFS CSI Driver 的最佳实践》整理而成。
大家好,我是来自 Juicedata 的朱唯唯,现在主要负责 JuiceFS CSI Driver 方面的开发,很高兴今天有这个机会跟大家做一个分享和交流,我今天分享的题目是 “JuiceFS CSI Driver 的最佳实践”。主要会从以下几个方面给大家做一个分享:
- Kubernetes 存储方案
- 如何在 Kubernetes 中使用 JuiceFS
- JuiceFS CSI Driver 架构设计实践
Kubernetes 存储方案
在 Kubernetes 里面对存储有三个概念,第一个是 PV,也就是持久卷,代表的是集群中的一份存储,可以定义存储的类型、大小等,比如指定它是哪一种类型, NFS 或 GlusterFS ,也可以指定它是 CSI 的。第二个概念是 PVC,持久卷申明,代表的是 Pod 使用存储的一份请求,Pod 不直接使用 PV 而是通过 PVC 来使用 PV。另一个是 StorageClass,持久卷类型,代表的是集群中的存储类型,它不定义存储的大小,只定义类型,在使用的时候 Kubernetes 会根据 StorageClass 自动创建 PV。以上就是 Kubernetes 对 Pod 使用存储所定义的三种资源。
apiVersion: v1 aversion: v1 apiVersion: v1
kind: PersistentVolume kind: PersistentVolumeClaim kind: Pod
metadata: metadata: metadata:
name: pv0001 name: myclaim name: pv-recycler
labels: spec: spec:
pv: pv0001 accessModes containers:
spec: - ReadWriteMany - name: pv-recycler
capacity: volumeMode: Filesystem image: "nginx"
storage: 5Gi resources volumeMounts:
volumeMode: Filesystem requests: - name: my-volume
accessModes: storage: 5Gi mountPath: /root/data
- ReadWriteMany selector: volumes:
hostPath: matchLabels: - name: my-volume
path: /root/data/test pv: pv0001 persistentVolumeClaim:
claimName: myclaim
我们再来看一下在 Kubernetes 中 Pod 怎样使用存储,主要有两种方式,第一种是静态存储,就是 PV 加 PVC 的方式,可以看上图的几个 yaml 文件,第一个就是 PV 的 yaml 文件。一般由系统管理员先在集群中创建一份 PV,然后在使用的时候创建一个 PVC ,指定使用哪个 PV,但是一个 PV 只能被一个 Pod 使用,每当有新的 Pod 需要使用存储时,系统管理员也要创建相应的 PV,并在 PV 里面是指定它有多大的存储量,用什么样的访问方式以及它是什么类型的,文中给出来的例子就是 hostPath,当然也可以在这里指定它为 Kubernetes 内置的一些存储类型,比如 NFS 、CSI,如果是 CSI 的话,那就需要我们第三方去实现关于 CSI 的一个插件。
PV 定义好了之后,在集群里面就代表有这么一份存储可以用,当 Pod 在使用该 PV 的时候,需要用户提前先去建立一个 PVC 的资源,然后在 PVC 中去指定用什么样的方式去访问存储,以及需要用多大的容量,当然这个容量不能超过 PV 中指定的已有容量。也可以用 label select 的方式去指定这个 PVC 使用哪个 PV ,以上就完成了一个 PVC 资源的创建。
当 PVC 创建好了之后 Pod 就可以直接使用了,使用的方式就是当挂载在 volume 的时候指定一下 Claim 是哪一个 PVC 就可以了。这是静态存储的方案,但是这种方案有一个问题,一个 PV 只能被一个 PVC 使用,当 Pod 被运行起来在使用 PV 的时候, PV 的状态也就会被 Kubernetes 改成 Bound 状态,它一旦是 Bound 状态,另一个 Pod 的 PVC 就不能使用了。那也就意味着每当有新的 Pod 需要使用存储时,系统管理员也要创建相应的 PV,可想而知系统管理员的工作量会很大。
apiVersion: storage.k8s.io/v1 aversion: v1 apiVersion: v1
kind: StorageClass kind: PersistentVolumeClaim kind: Pod
metadata: metadata: metadata:
name: example-nfs name: myclaim name: pv-recycler
provisioner: example.com/external-nfs spec: spec:
parameters: accessModes: containers:
server: nfs-server.example.com - ReadWriteMany - name: pv-recycler
path: /share volumeMode: Filesystem image: "nginx"
readOnly: false resources: volumeMounts:
requests: - name: my-volume
storage: 5Gi mountPath: /root/data
storageClassName: example-nfs volumes:
- name: my-volume
persistentVolumeClaim:
claimName: myclaim另一种方式是动态存储,动态存储的方式就是 StorageClass + PVC 使用方式也类似,就是系统管理员先在集群中创建一份 StorageClass,只需指定存储类型,以及它的一些访问参数。在 Pod 在使用的时候依然是创建一个 PVC 指定它需要使用多大容量以及它的访问方式,再指定 StorageClass ,然后 Pod 里面使用和上文是一样的。但在该方案中当 Kubernetes 在创建 Pod 之前会根据 StorageClass 中指定的类型和 PVC 中指定的容量大小等参数,自动创建出对应的 PV,这种方式相比之下解放了系统管理员。
无论是 PV 还是 StorageClass,在指定存储类型的时候,可以使用 Kubernetes 内置的存储类型,比如 hostPath、NFS 等,还有一种方式就是 CSI,第三方云厂商通过实现 CSI 接口来为 Pod 提供存储服务。JuiceFS 也实现了自己的 CSI Driver。
什么是 JuiceFS

JuiceFS 是一款面向云环境设计的高性能共享文件系统,可以被多台主机同时挂载读写,使用对象存储来作为底层的存储层,我们没有重复造轮子,而是选择了站在对象存储的肩膀上。对象存储大家都知道它有很多好处,一个是低价排量、高吞吐、高可用性,但是它同时也有很多缺点,比如很重要的一点就是它没有目录的管理能力,对于文件系统来说,用户访问起来不是很方便,同时它就只有HTTP接口,并且是按照调用次数收费的。
针对对象存储的这种问题,我们引入了元数据服务,通过这方式我们可以在对象存储的基础上提供完备的 POSIX 兼容性。我们对外提供各种各样的接口,包括 POSIX 接口,各种网络存储协议以及各种各样的 SDK,通过这样的一种架构,我们可以将海量低价的云存储作为本地磁盘使用成为了一种可能。
如何在 Kubernetes 中使用 JuiceFS?
Kubernetes 是目前最流行的一种应用编排引擎,将资源池化,使得用户不再需要关心底层的基础设施和基础资源,这一点 JuiceFS 的设计理念是相同的。同时 Kubernetes 也提供了一些声明式 API 并且它的可拓展性很强,它提供了一种 CSI 的一种接入方式,让 JuiceFS 可以很方便的接入进来,
在 Kubernetes 中使用 JuiceFS 十分简单,我们提供了两种安装方式,helm chart 安装和 Kubernetes yaml 直接 apply,任意一种方式都可以做到一键安装部署。然后再准备一个元数据引擎和对象存储服务就可以直接通过 Kubernetes 原生方式,在 Pod 里直接使用 Juicefs 类型的存储了。

在 KubeSphere 中使用 JuiceFS 就更简单了。在界面上通过「应用模板」上传 chart 包或者在「应用仓库」中添加 JuiceFS 的官网 chart 仓库地址,就可以直接安装 Juicefs CSI Driver 了,然后在 KubeSphere 中使用和原生的 Kubernetes 使用方式是一样的,后续我们会把 JuiceFS 做为 Kubesphere 的原生插件,在部署 Kubesphere 之后即可直接使用,大家可以期待一下。
CSI 工作原理
如果大家平时使用过 CSI 或者接触过它的一些原理的话,我们会知道它其实很复杂,CSI 的官方提供了很多插件,主要有两种方式,一种是 CSI 内部的组件,另一种是外部的,内部的话我们在这里就不介绍了,我们只介绍外部的两类插件,一类是需要我们自己去实现的插件,CSI Controller,CSI Node 和 CSI Identity ,还有一类就是官方提供的一些 SideCar,这些 SideCar 全部都是配合以上三个插件去完成存储的所有功能。
CSI Controller,它是以 deployment 的形式运行在集群里面,主要负责 provision 和 attach 工作。当然 attach 不是每一个存储都会用到的,而 provision 就是在使用 StorageClass 的时候会动态创建 PV 的过程,所以 CSI Controller 在实现 provision 这个功能的时候,是 external-provisioner 这个 SideCar 去配合实现的,在实现 attach 功能的时候是 external-attacher 配合它一起完成的。
CSI Node 和 CSI Identity 通常是部署在一个容器里面的,它们是以 daemonset 的形式运行在集群里面,保证每一个节点会有一个 Pod 部署出来,这两个组件会和 CSI Controller 一起完成 volume 的 mount 操作。CSI Identity 是用来告诉 Controller,我现在是哪一个 CSI 插件,它实现的接口会被 node-driver-registrar 调用给 Controller 去注册自己。CSI Node 会实现一些 publish volume 和 unpublished volume 的接口,Controller 会去调用来完成 volume 的 mount 的操作,我们只需要实现这几个插件的接口就可以了。
Provision 过程
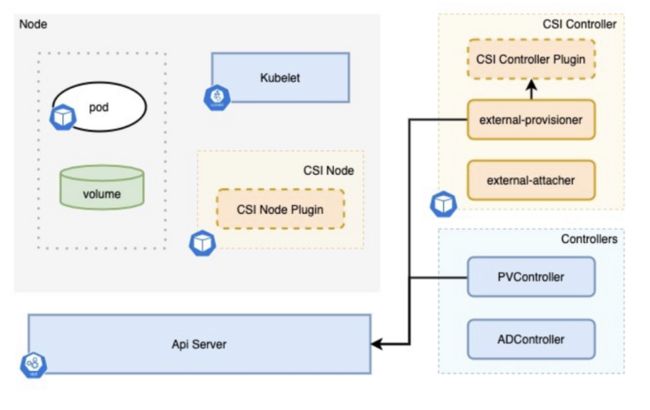
上文介绍的 Kubernetes 中的动态存储方案,是管理员只需要创建 StorageClass,然后用户创建 PVC,由 Kubernetes 自动的帮你创建 PV 的这么一个过程,其中具体的流程如上图所示,首先是 PVController 会去向 API Server 监听 PVC 资源的创建,它监听到 PVC 资源的创建会给 PVC 打上一个注解,注解里告诉 Kubernetes 是现在 PVC 使用的是哪一个 CSI 然后同时 external-provisioner 这个 SideCar 也会去监听 PVC 的资源,如果注解信息和自己的 CSI 是一样的话,它就会去调用 CSI controller 的接口去实现创建 volume 的逻辑,这个接口调用成功之后,external-provisioner 就会认为 volume 已经创建好了,然后就会去对应的创建 PV。
Mount 过程
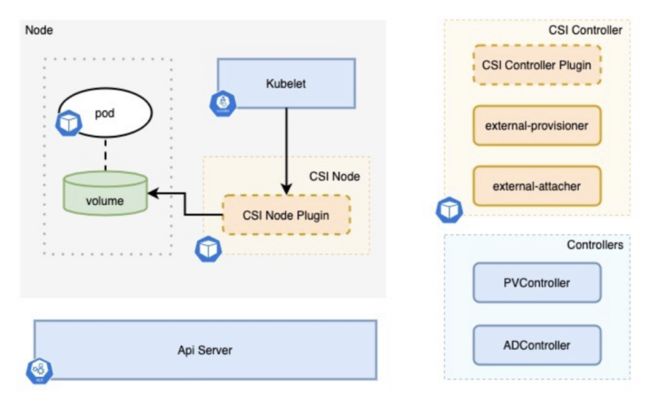
PV 创建好了之后就到了 Mount 的过程,还是那张图,但是调用接口不一样,在 Mount 过程中参与的组件是 Kubelet 和 CSI Node。Kubelet 在创建 Pod 之前会去帮它准备各种各样的运行环境,包括需要声明存储的环境,这些环境准备好之后 Kubelet 才会去创建 Pod,那么准备 volume 的环境就是 Kubelet 去调用 CSI Node Plugin 的接口去实现的,在这个接口里面去实现 volume 的 mount 过程就完成了整个 Pod 所需要的一些存储环境。这些整个完成之后,Kubelet 的才会创建 Pod。
JuiceFS CSI Driver 的设计
CSI Driver 遇到的挑战
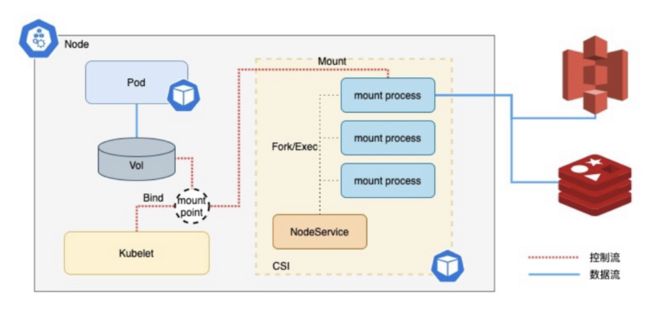
JuiceFS CSI Driver 最初的架构设计是这样的,我们实现了 CSI 的几个接口和常见的基本一样,不同的就是我们在 NodeService 组件里面,我们会去实现 JuiceFS mount 这个过程。
由于 JuiceFS 是用户态文件系统,CSI 在完成 Mount 工作的时候,首先是会在节点上创建一个挂载点,同时会 fork 出一个 mount 进程,也就是 JuiceFS 客户端。而进程它是直接运行在 CSI Node 的 Pod 里的,挂载点准备好之后,我们还会在接口里面把这个机器上的挂载点 bind 到 kubelet target 路径。这个进程直接运行在 CSI Pod 里,有多少 Volume 就会有多少进程同时运行在这个 Pod 里,这样的实现就会带来一系列的问题。
首先,JuiceFS 客户端之间没有资源隔离,而且进程直接运行在 CSI Pod 里会导致 Kubernetes 集群对客户端进程无感知,当客户端进程意外退出的时候,在集群中是看不出任何变化的;最关键的是 CSI Driver 不能平滑升级,升级的唯一方式就是,先把用户所有使用到 JuiceFS 的 Pod 全部停掉,然后升级,升级完再把所有的业务 Pod 一个个再运行起来。这样的升级方式对于运维同学来说简直是灾难;另外一个问题是 CSI Driver 的爆炸半径过大,跟第三点类似,CSI Driver 一旦退出,那运行在里面的 JuiceFS 客户端都不能正常使用。
CSI Driver 架构升级
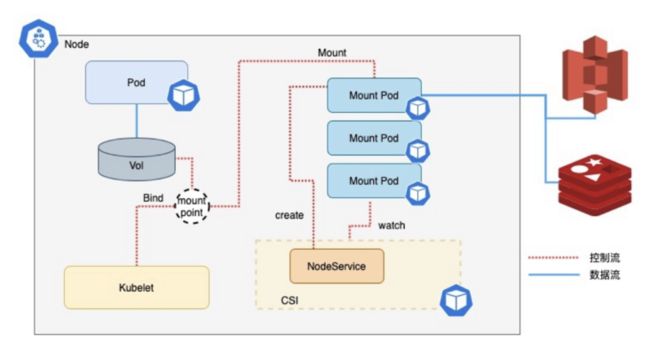
针对这些问题,我们对 CSI Driver 的架构设计进行了一些改进。具体的做法就是将执行 volume 挂载的操作在单独的 Pod 里执行,这样 fork 出来的进程就可以运行在 Pod 里了。如果有多个的业务 Pod 共用一份存储,mount Pod 会在 annotation 进行引用计数,确保不会重复创建。每当有业务 Pod 退出时,mount Pod 会删除对应的计数,只有当最后一个记录被删除时 mount Pod 才会被删除。还有一点是 CSI Node 会通过 APIService watch mount Pod 的状态变化,以管理其生命周期。我们一旦观察到它意外退出,及它 Pod 的退出了,但是它的 annotation 还有计数,证明它是意外退出,并不是正常的一个被删除,这样的话我们会把它重新起来,然后在业务的容器的 target 路径重新执行 mount bind,这是我们目前还在开发的一个功能。
架构升级的益处
- 最直接的好处就是 CSI Driver 被解耦出来了,CSI driver无论做什么操作都不会影响到客户端,做升级不会再影响到业务容器了,
- 将 JuiceFS 客户端独立在 Pod 中运行也就使其在 Kubernetes 的管控内,可观测性更强;
- 同时 Pod 的好处我们也能享受到,比如隔离性更强,可以单独设置客户端的资源配额等。
未来展望
对于未来我们还会去做一些工作,目前我们把 JuiceFS 客户端的进程运行在单独的 Pod 里,但是对于 FUSE 进程在容器环境的高可用性依然存在很大的挑战,这也是我们今后会一直关注探讨的问题。另外我们也在持续摸索对于 JuiceFS 在云原生环境更多的可能性,比如使用方式上面除了 CSI 还会有 Fluid、Paddle-operator 等方式。
推荐阅读:
百亿级小文件存储,JuiceFS 在自动驾驶行业的最佳实践
项目地址: Github (https://github.com/juicedata/juicefs)如有帮助的话欢迎关注我们哟! (0ᴗ0✿)